







 mapreduce的组合,排序,分组在使用mapreduce处理数据时,总有种“简单,粗暴”的感觉,就像一个傻大个一样。为了能更加灵活的处理分析数据,以及将这个傻大个使用的更加得心应手,今天总结下这位傻大个在处理数据时使用的自身的一些组件。1.combiner(组合)当然可能大家已经非常熟知了,我在这里就不卖弄了,简单的解释一下使用它的优势,为大家灌个耳音,combiner的作用是组合map阶段生成
mapreduce的组合,排序,分组在使用mapreduce处理数据时,总有种“简单,粗暴”的感觉,就像一个傻大个一样。为了能更加灵活的处理分析数据,以及将这个傻大个使用的更加得心应手,今天总结下这位傻大个在处理数据时使用的自身的一些组件。1.combiner(组合)当然可能大家已经非常熟知了,我在这里就不卖弄了,简单的解释一下使用它的优势,为大家灌个耳音,combiner的作用是组合map阶段生成
mapreduce的组合,排序,分组
在使用mapreduce处理数据时,总有种“简单,粗暴”的感觉,就像一个傻大个一样。
为了能更加灵活的处理分析数据,以及将这个傻大个使用的更加得心应手,今天总结下这位傻大个在处理数据时使用的自身的一些组件。
1.combiner(组合)
当然可能大家已经非常熟知了,我在这里就不卖弄了,简单的解释一下使用它的优势,为大家灌个耳音,
combiner的作用是组合map阶段生成的数据,是好像说的根reduce一样,不同点在于它只组合一个map task产生的数据。给大家上一张盗过来的图。
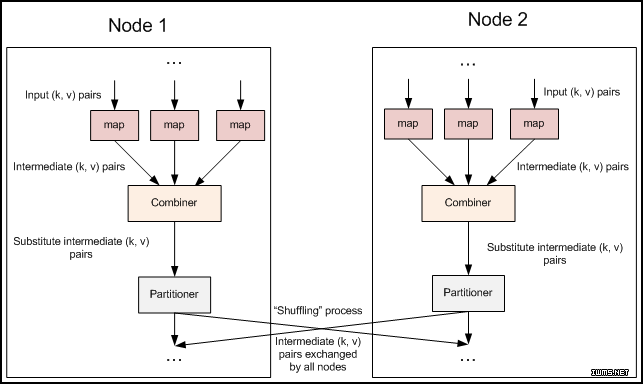
是不是一下子就明白了呀。
举个更直观的例子吧:还记得我们的 单词统计demo吗?假如现在在map阶段 mapreduce读取到下面这一行数据
hello hello hello hello world
直接使用了例子中的那种解决办法,那么在map阶段将生产如下数据
<hello,1> <hello,1> <hello,1> <hello,1> <world,1>
那么到了reduce阶段 mapreduce会将这些数据从各个节点上收集起来,那么每收集一次就需要一次网络传输,这个是不是也太奢侈了。
那么咋们的 combiner 就配上用场了,combiner的作用就是在map和reduce阶段加入了组合功能,那么应用上面的例子中,combiner会将上面产生的数据做如下整理
<hello,4> <world,1>
一下子清爽多了,是不是。这样可以大大提高网络传输效率。在理解combiner时,只需理解,combiner的整理(组合)发生在一个map task就已经将他摸清楚了。
2.comparable(比较)
comparable 的用途在于,对mapreduce中传输的数据做比较操作,我们可以使用它对mapreduce处理的数据做排序处理,在使用的过程中我们一般是继承 WritableComparable 类 来自定义我们自己的比较规则用法和我们在jdk中使用的 Comparable 接口一样,WritableComparable就是继承了该接口,此处不再累赘,直接上代码了。
public class Channel implements WritableComparable<Channel>{
private int id;
private String channel;
private String url;
private Date addTime;
private String ip;
private int glance;
private int regist;
private String mac;
、、、、set get
@Override
public void readFields(DataInput in) throws IOException {
this.id=in.readInt();
this.channel=in.readUTF();
this.url=in.readUTF();
this.addTime=new 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









