







导入本次实践过程中所需的包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score,\
confusion_matrix, f1_score, roc_curve, roc_auc_score
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
from sklearn.preprocessing import StandardScaler
%matplotlib inline
plt.rc('font', family='SimHei', size=14)
plt.rcParams['axes.unicode_minus']=False
%config InlineBackend.figure_format = 'retina'
准备数据
数据集下载
实践数据的下载地址 https://pan.baidu.com/s/1dtHJiV6zMbf_fWPi-dZ95g
说明:这份数据集是金融数据(非原始数据,已经处理过了),我们要做的是预测贷款用户是否会逾期。表格中 “status” 是结果标签:0表示未逾期,1表示逾期。
导入数据
从data_all.csv文件中导入原始数据,并查看数据相关信息:
data_origin = pd.read_csv('data_all.csv')
data_origin.head()
| low_volume_percent | middle_volume_percent | take_amount_in_later_12_month_highest | trans_amount_increase_rate_lately | trans_activity_month | trans_activity_day | transd_mcc | trans_days_interval_filter | trans_days_interval | regional_mobility | ... | consfin_product_count | consfin_max_limit | consfin_avg_limit | latest_query_day | loans_latest_day | reg_preference_for_trad | latest_query_time_month | latest_query_time_weekday | loans_latest_time_month | loans_latest_time_weekday | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.01 | 0.99 | 0 | 0.90 | 0.55 | 0.313 | 17.0 | 27.0 | 26.0 | 3.0 | ... | 2.0 | 1200.0 | 1200.0 | 12.0 | 18.0 | 0 | 4.0 | 2.0 | 4.0 | 3.0 |
| 1 | 0.02 | 0.94 | 2000 | 1.28 | 1.00 | 0.458 | 19.0 | 30.0 | 14.0 | 4.0 | ... | 6.0 | 22800.0 | 9360.0 | 4.0 | 2.0 | 0 | 5.0 | 3.0 | 5.0 | 5.0 |
| 2 | 0.04 | 0.96 | 0 | 1.00 | 1.00 | 0.114 | 13.0 | 68.0 | 22.0 | 1.0 | ... | 1.0 | 4200.0 | 4200.0 | 2.0 | 6.0 | 0 | 5.0 | 5.0 | 5.0 | 1.0 |
| 3 | 0.00 | 0.96 | 2000 | 0.13 | 0.57 | 0.777 | 22.0 | 14.0 | 6.0 | 3.0 | ... | 5.0 | 30000.0 | 12180.0 | 2.0 | 4.0 | 1 | 5.0 | 5.0 | 5.0 | 3.0 |
| 4 | 0.01 | 0.99 | 0 | 0.46 | 1.00 | 0.175 | 13.0 | 66.0 | 42.0 | 1.0 | ... | 2.0 | 8400.0 | 8250.0 | 22.0 | 120.0 | 0 | 4.0 | 6.0 | 1.0 | 6.0 |
5 rows × 85 columns
划分数据集
首先将status列作为数据标签y,其余列作为数据集X:
y = data_origin.status
X = data_origin.drop(['status'], axis=1)
模型正规化
scaler = StandardScaler()
X_scale = scaler.fit_transform(X)
再调用sklearn包将此金融数据集按比例7:3划分为训练集和数据集,随机种子2018:
X_train, X_test, y_train, y_test = train_test_split(X_scale, y, test_size=0.3, random_state=2018)
查看划分的数据集和训练集大小:
[X_train.shape, y_train.shape, X_test.shape, y_test.shape]
[(3327, 84), (3327,), (1427, 84), (1427,)]
模型调优
构建并训练本次需要用到的七个模型,包含四个集成模型:XGBoost,LightGBM,GBDT,随机森林,和三个非集成模型:逻辑回归,SVM,决策树。使用网格搜索法对7个模型进行调优(调参时采用五折交叉验证的方式)
逻辑回归
部分参数介绍:
- C : float, default: 1.0
C值越小,正则化强度越强,C必须是一个正的浮点数。
- fit_intercept : bool, default: True
指定决策方程中是否加入常数(偏置)项。
- class_weight : dict or ‘balanced’, default: None
指定每个类的权重,未指定时所有类都默认有同一权重。“平衡”模式使用y的值来自动调整与输入数据中的类频率成反比的权重,即n_samples / (n_classes * np.bincount(y)).
- solver : str, {‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default: ‘liblinear’.
优化时使用的算法,对于小数据集,'liblinear’是一个好选择,而‘sag’ 和 ‘saga’对大数据集训练更快。对于多分类问题,只有‘newton-cg’, ‘sag’, ‘saga’ 和 ‘lbfgs’能处理多元损失,‘liblinear’只能以one-versus-rest模式训练。
‘newton-cg’, ‘lbfgs’ 和 ‘sag’只能使用l2惩罚项,‘liblinear’ 和 ‘saga’可以使用l1惩罚项。
注意,“sag”和“saga”快速收敛仅在具有大致相同比例的特征上得到保证。可以使用sklearn.preprocessing中的scaler预处理数据。
- max_iter : int, default: 100
最大迭代次数
param_grid = {'C': [0.1, 1, 10],
'solver': ['liblinear', 'lbfgs'],
'class_weight': ['balanced', None],
'max_iter': [1000]
}
log_grid = GridSearchCV(LogisticRegression(random_state=2018), param_grid, cv=5)
log_grid.fit(X_train, y_train)
GridSearchCV(cv=5, error_score='raise',
estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=2018, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False),
fit_params=None, iid=True, n_jobs=1,
param_grid={'C': [0.1, 1, 10], 'solver': ['liblinear', 'lbfgs'], 'class_weight': ['balanced', None], 'max_iter': [1000]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
查看最佳参数和评分:
log_grid.best_estimator_
LogisticRegression(C=0.1, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=1000, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=2018, solver='lbfgs', tol=0.0001,
verbose=0, warm_start=False)
log_grid.best_score_
0.7914036669672377
SVM
- C: float, optional (default=1.0)
目标函数的惩罚系数C,用来平衡分类间隔margin和错分样本的
- kernel: string, optional (default=’rbf’)
参数选择有RBF, Linear, Poly, Sigmoid
- gamma:float, optional (default=’auto’)
核函数的系数(‘Poly’, ‘RBF’ 和 ‘Sigmoid’), 默认是gamma = 1 / n_features;
param_grid = {'C': [0.1, 1, 10],
'gamma': ['auto', 0.1]}
svc_grid = GridSearchCV(SVC(random_state=2018, probability=True), param_grid, cv=5)
svc_grid.fit(X_train, y_train)
GridSearchCV(cv=5, error_score='raise',
estimator=SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=True, random_state=2018, shrinking=True,
tol=0.001, verbose=False),
fit_params=None, iid=True, n_jobs=1,
param_grid={'C': [0.1, 1, 10], 'gamma': ['auto', 0.1]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
svc_grid.best_estimator_, svc_grid.best_score_
(SVC(C=1, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=True, random_state=2018, shrinking=True,
tol=0.001, verbose=False), 0.7905019537120529)
决策树
- max_depth : int or None, optional (default=None)
树的最大深度,如果设置为None则直到叶节点只剩一个或者少于min_samples_split时停止。
- max_features : int, float, string or None, optional (default=None)
在寻找最佳分割时考虑的特征数,设置为’auto’时max_features=sqrt(n_features)
- class_weight : dict, list of dicts, “balanced” or None, default=None
指定每个类的权重,未指定时所有类都默认有同一权重。“平衡” 模式使用 y 的值来自动调整与输入数据中的类频率成反比的权重,即 n_samples / (n_classes * np.bincount(y)).
param_grid = {'class_weight': ['balanced', None],
'max_features': ['auto', None],
'max_depth': range(3, 10, 1)
}
tree_grid = GridSearchCV(DecisionTreeClassifier(random_state=2018), param_grid, cv=5)
tree_grid.fit(X_train, y_train)
tree_grid.best_estimator_, tree_grid.best_score_
(DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=4,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=2018,
splitter='best'), 0.7670574090772467)
随机森林
- n_estimators : integer, optional (default=10)
n_estimators: 也就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。
- max_features : int, float, string or None, optional (default=”auto”)
在寻找最佳分割时考虑的特征数,设置为’auto’时 max_features=sqrt(n_features)
param_grid = {'n_estimators': [10, 50, 100, 150],
'max_features': ['auto', None]
}
forest_grid = GridSearchCV(RandomForestClassifier(random_state=2018), param_grid, cv=5)
forest_grid.fit(X_train, y_train)
forest_grid.best_estimator_, forest_grid.best_score_
(RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=1,
oob_score=False, random_state=2018, verbose=0,
warm_start=False), 0.7974150886684701)
GBDT
- n_estimators : integer, optional (default=10)
要执行的迭代次数。梯度增强对于过拟合强健性好,多以较大的值通常效果更好。
- learning_rate : float, optional (default=0.1)
通过learning_rate缩小每棵树的贡献,需要在learning_rate和n_estimators之间进行权衡。
param_grid = {'n_estimators': range(60, 121, 20),
'learning_rate': [0.1, 1]
}
gbdt = GridSearchCV(GradientBoostingClassifier(random_state=2018), param_grid, cv=5)
gbdt.fit(X_train, y_train)
gbdt.best_estimator_, gbdt.best_score_
(GradientBoostingClassifier(criterion='friedman_mse', init=None,
learning_rate=0.1, loss='deviance', max_depth=3,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=60,
presort='auto', random_state=2018, subsample=1.0, verbose=0,
warm_start=False), 0.7956116621581004)
XGBoost
param_grid = {'n_estimators': range(80, 121, 20),
'max_depth': range(3, 6, 1),
'learning_rate': [0.1, 1]
}
xgb = GridSearchCV(XGBClassifier(random_state=2018), param_grid, cv=5)
xgb.fit(X_train, y_train)
xgb.best_estimator_, xgb.best_score_
(XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0,
max_depth=3, min_child_weight=1, missing=None, n_estimators=80,
n_jobs=1, nthread=None, objective='binary:logistic',
random_state=2018, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,
seed=None, silent=True, subsample=1), 0.7941088067327923)
LightGBM
param_grid = {'n_estimators': range(80, 121, 20),
'max_depth': range(3, 6, 1),
'learning_rate': [0.1, 1]
}
lgbm = GridSearchCV(LGBMClassifier(random_state=2018), param_grid, cv=5)
lgbm.fit(X_train, y_train)
lgbm.best_estimator_, lgbm.best_score_
(LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=3,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=80, n_jobs=-1, num_leaves=31, objective=None,
random_state=2018, reg_alpha=0.0, reg_lambda=0.0, silent=True,
subsample=1.0, subsample_for_bin=200000, subsample_freq=0),
0.7944093778178539)
模型评估
对构建的七个模型进行评估
models = {'随机森林': forest_grid.best_estimator_,
'GBDT': gbdt.best_estimator_,
'XGBoost': xgb.best_estimator_,
'LightGBM': lgbm,
'逻辑回归': log_grid.best_estimator_,
'SVM': svc_grid.best_estimator_,
'决策树': tree_grid.best_estimator_}
assessments = {
'Accuracy': [],
'Precision': [],
'Recall': [],
'F1-score': [],
'AUC': []
}
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.legend()
plt.tight_layout()
for name, model in models.items():
test_pre = model.predict(X_test)
train_pre = model.predict(X_train)
test_proba = model.predict_proba(X_test)[:,1]
train_proba = model.predict_proba(X_train)[:,1]
acc_test = accuracy_score(test_pre, y_test) * 100
acc_train = accuracy_score(train_pre, y_train) * 100
accuracy = '训练集:%.2f%%;测试集:%.2f%%' % (acc_train, acc_test)
assessments['Accuracy'].append(accuracy)
pre_test = precision_score(test_pre, y_test) * 100
pre_train = precision_score(train_pre, y_train) * 100
precision = '训练集:%.2f%%;测试集:%.2f%%' % (pre_train, pre_test)
assessments['Precision'].append(precision)
rec_test = recall_score(test_pre, y_test) * 100
rec_train = recall_score(train_pre, y_train) * 100
recall = '训练集:%.2f%%;测试集:%.2f%%' % (rec_train, rec_test)
assessments['Recall'].append(recall)
f1_test = f1_score(test_pre, y_test) * 100
f1_train = f1_score(train_pre, y_train) * 100
f1 = '训练集:%.2f%%;测试集:%.2f%%' % (f1_train, f1_test)
assessments['F1-score'].append(f1)
fig = plt.figure(figsize=(8, 6))
fpr, tpr, thresholds = roc_curve(y_test, test_proba)
plot_roc_curve(fpr, tpr, label='测试集')
fpr, tpr, thresholds = roc_curve(y_train, train_proba)
plot_roc_curve(fpr, tpr, label='训练集')
plt.title(name)
auc_test = roc_auc_score(y_test, test_proba) * 100
auc_train = roc_auc_score(y_train, train_proba) * 100
auc = '训练集:%.2f%%;测试集:%.2f%%' % (auc_train, auc_test)
assessments['AUC'].append(auc)
fig = plt.figure(figsize=(8, 6))
for name, model in models.items():
proba = model.predict_proba(X_test)[:,1]
fpr, tpr, thresholds = roc_curve(y_test, proba)
plot_roc_curve(fpr, tpr, label=name)
fig = plt.figure(figsize=(8, 6))
for name, model in models.items():
proba = model.predict_proba(X_train)[:,1]
fpr, tpr, thresholds = roc_curve(y_train, proba)
plot_roc_curve(fpr, tpr, label=name)
ass_df = pd.DataFrame(assessments, index=models.keys())
ass_df
| AUC | Accuracy | F1-score | Precision | Recall | |
|---|---|---|---|---|---|
| 随机森林 | 训练集:100.00%;测试集:74.94% | 训练集:100.00%;测试集:78.21% | 训练集:100.00%;测试集:36.66% | 训练集:100.00%;测试集:25.07% | 训练集:100.00%;测试集:68.18% |
| GBDT | 训练集:89.01%;测试集:76.79% | 训练集:83.95%;测试集:78.21% | 训练集:58.02%;测试集:43.56% | 训练集:44.24%;测试集:33.43% | 训练集:84.25%;测试集:62.50% |
| XGBoost | 训练集:90.46%;测试集:77.11% | 训练集:84.31%;测试集:78.98% | 训练集:59.22%;测试集:45.45% | 训练集:45.44%;测试集:34.82% | 训练集:84.98%;测试集:65.45% |
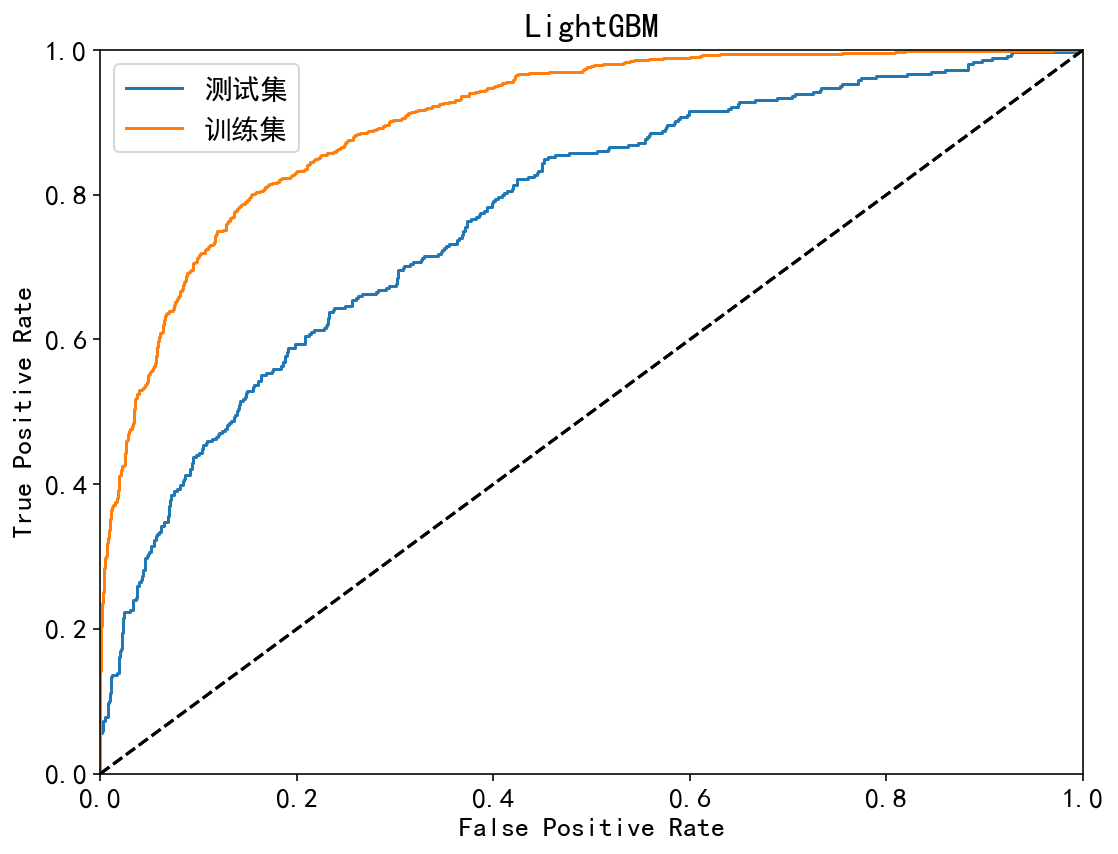
| LightGBM | 训练集:90.55%;测试集:77.28% | 训练集:84.49%;测试集:78.49% | 训练集:60.06%;测试集:44.88% | 训练集:46.52%;测试集:34.82% | 训练集:84.72%;测试集:63.13% |
| 逻辑回归 | 训练集:81.79%;测试集:76.96% | 训练集:80.43%;测试集:78.49% | 训练集:48.29%;测试集:41.97% | 训练集:36.45%;测试集:30.92% | 训练集:71.53%;测试集:65.29% |
| SVM | 训练集:92.05%;测试集:75.33% | 训练集:84.43%;测试集:78.28% | 训练集:57.26%;测试集:34.60% | 训练集:41.61%;测试集:22.84% | 训练集:91.80%;测试集:71.30% |
| 决策树 | 训练集:77.52%;测试集:69.54% | 训练集:80.55%;测试集:76.03% | 训练集:52.60%;测试集:43.38% | 训练集:43.05%;测试集:36.49% | 训练集:67.61%;测试集:53.47% |
ROC曲线:
| 集成模型 | 非集成模型 |
|---|---|
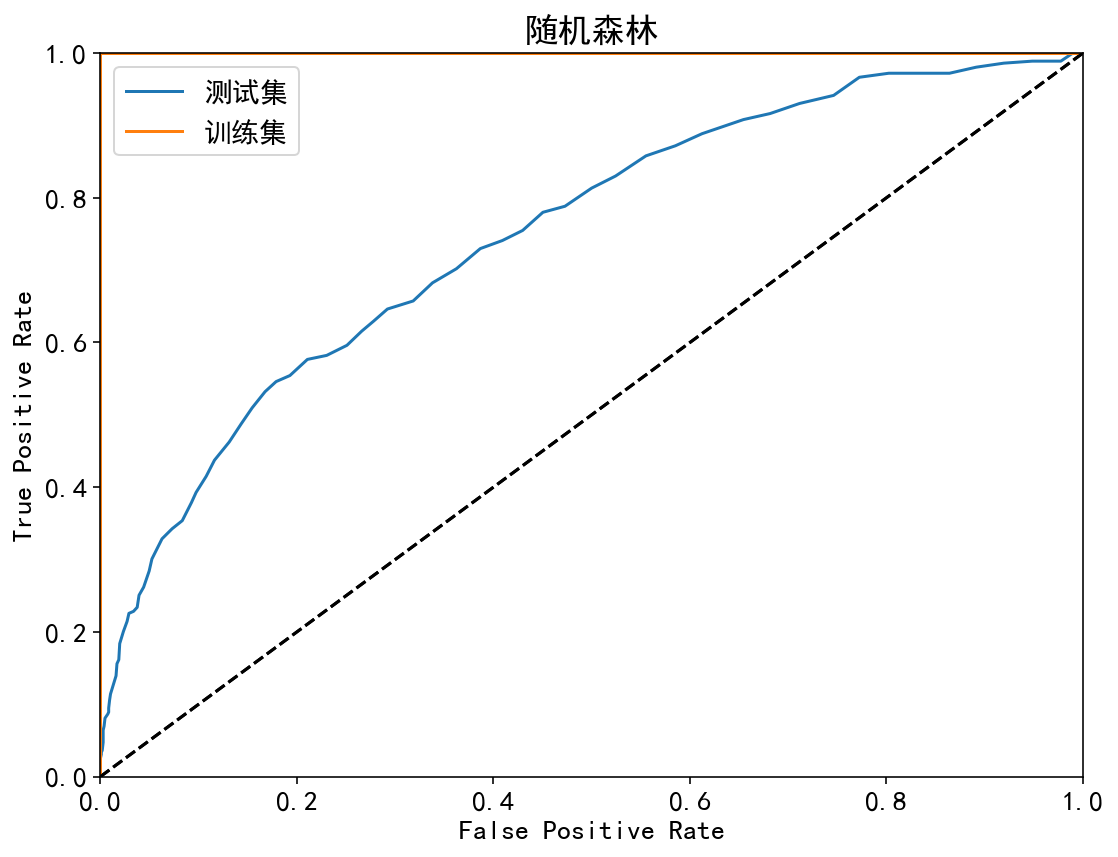 | 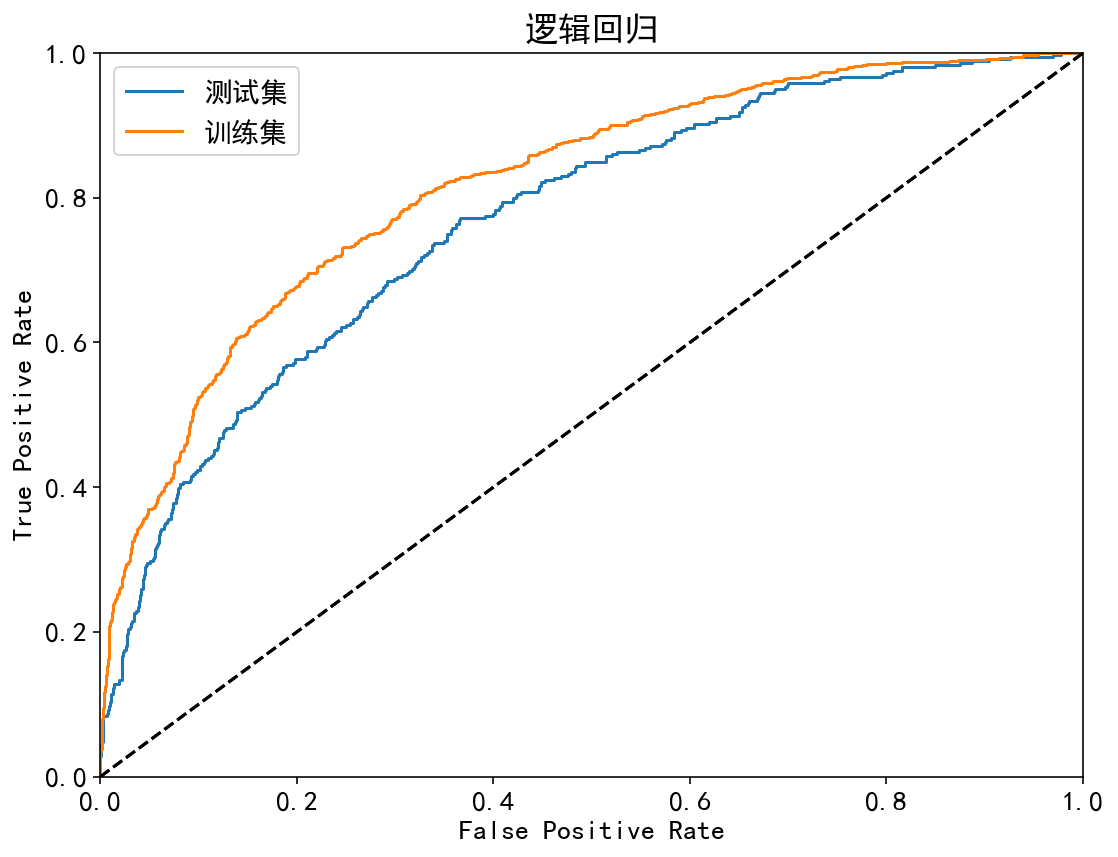 |
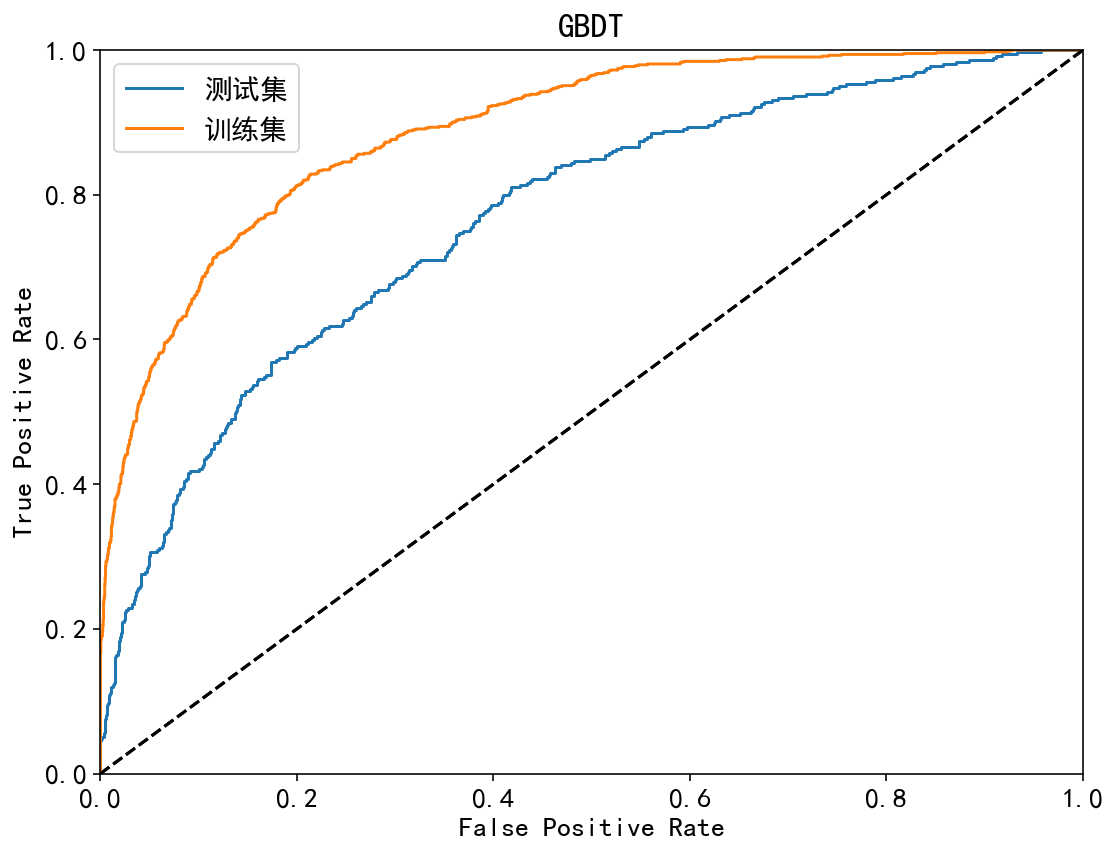 | 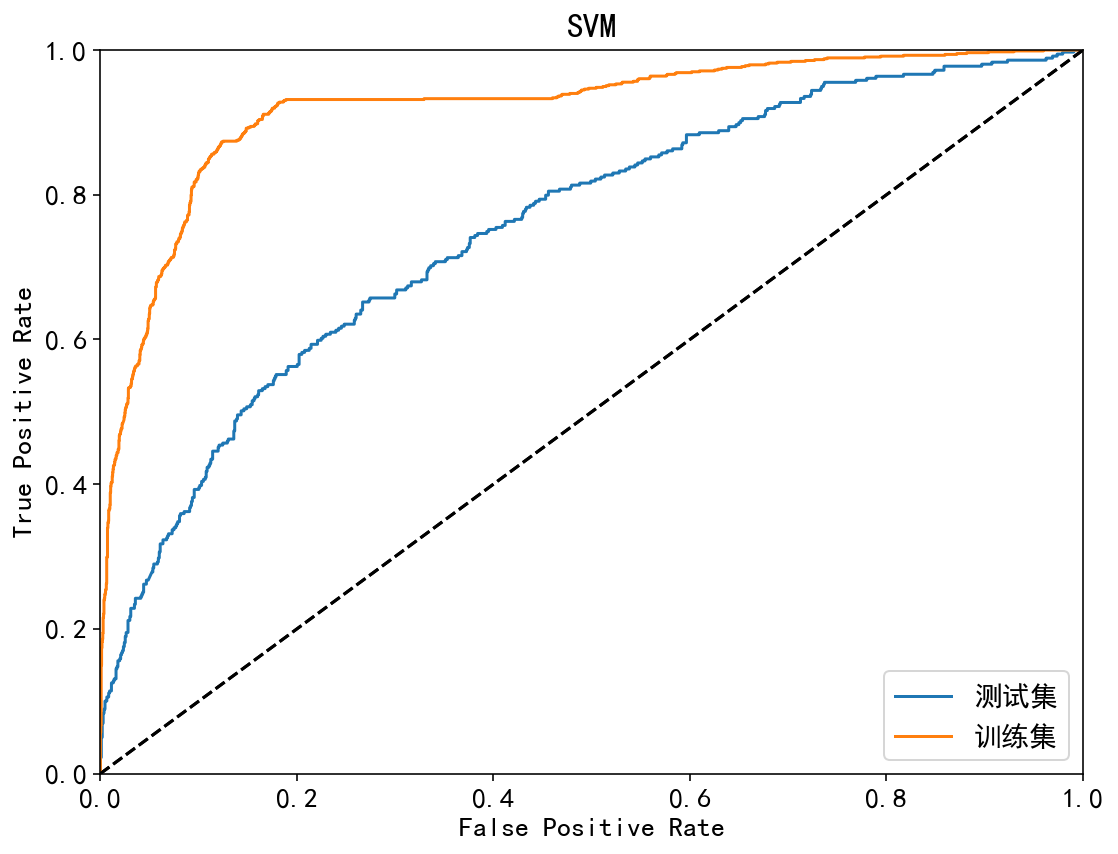 |
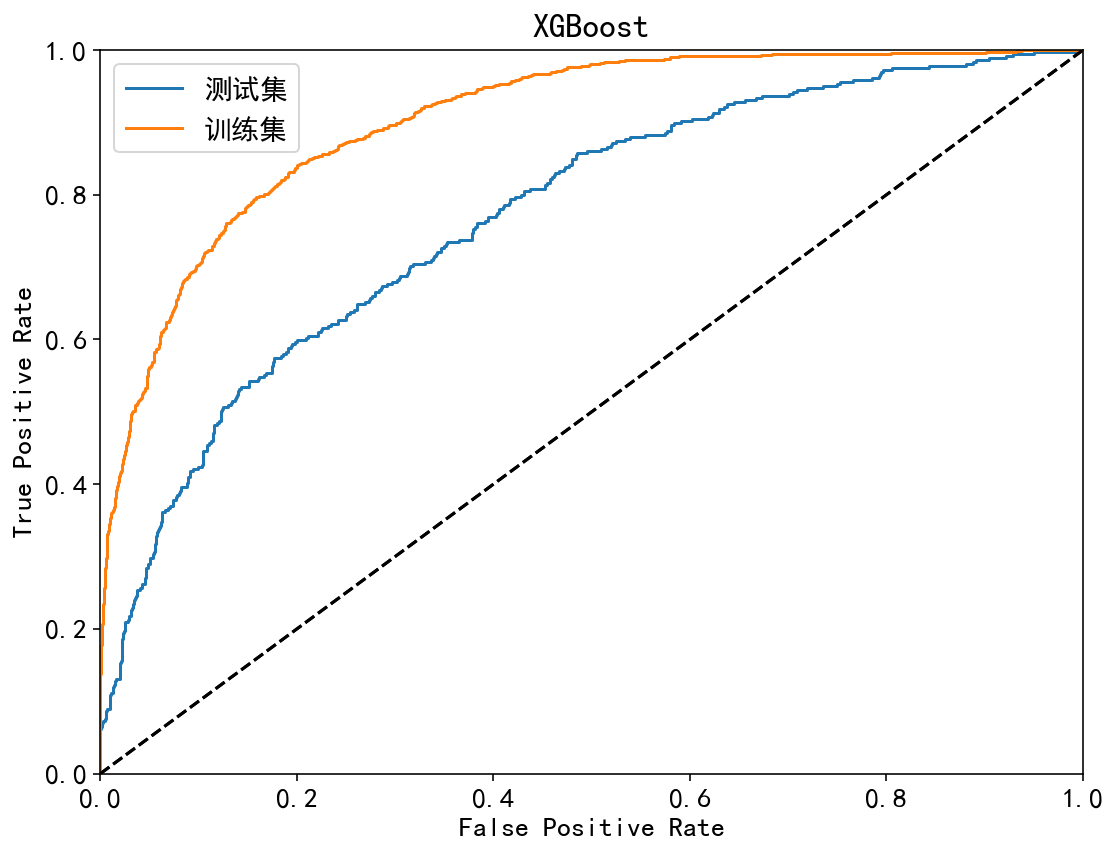 | 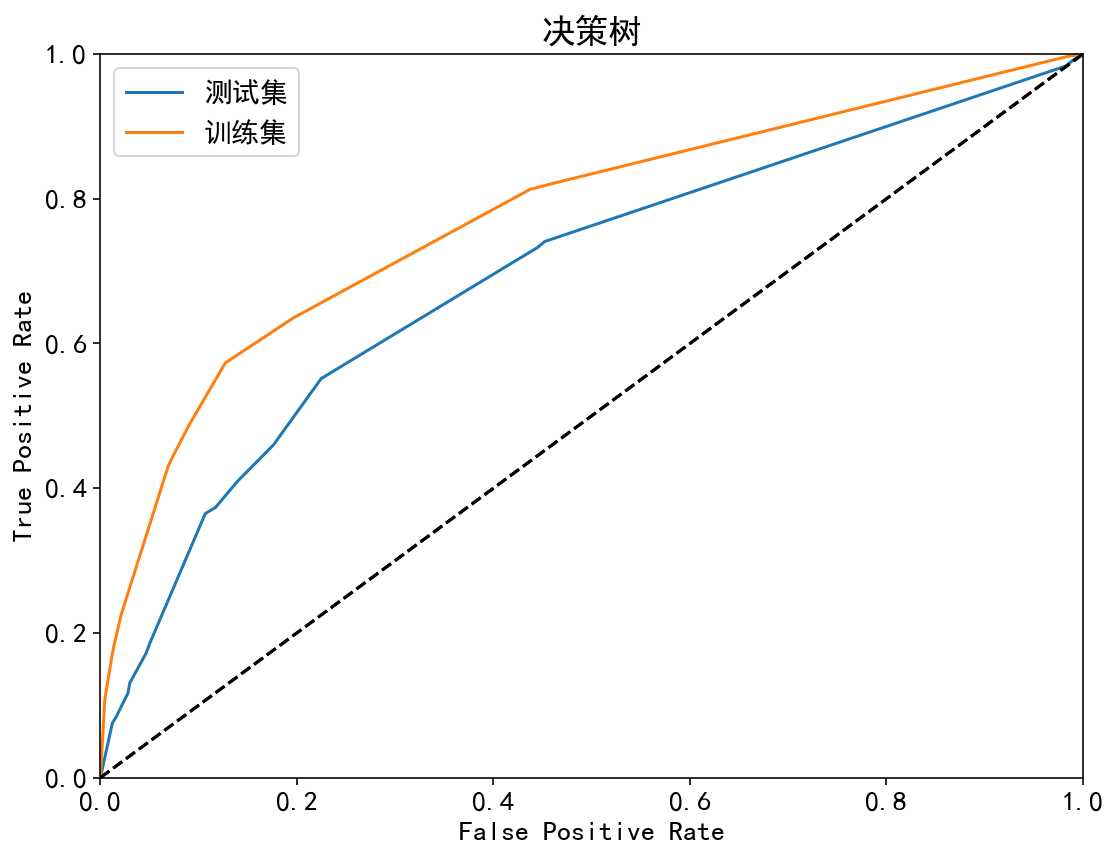 |
 |
综合比较ROC曲线:
| 训练集 | 测试集 |
|---|---|
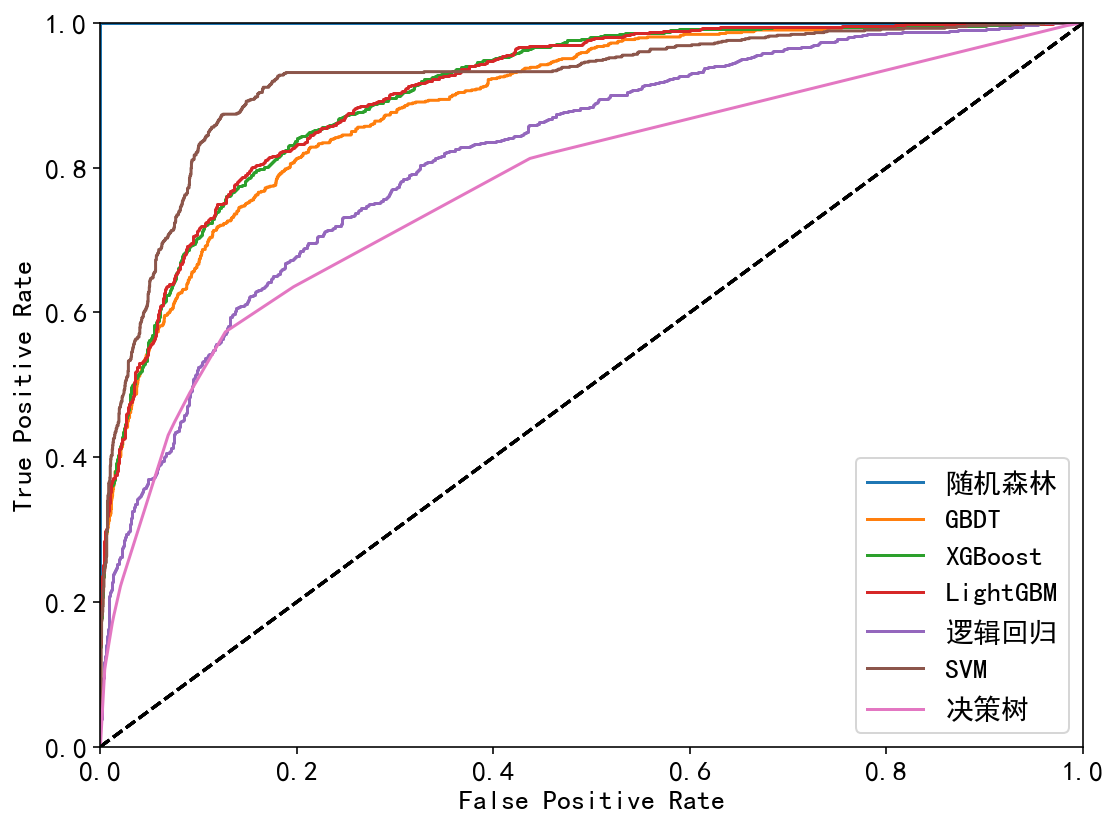 | 、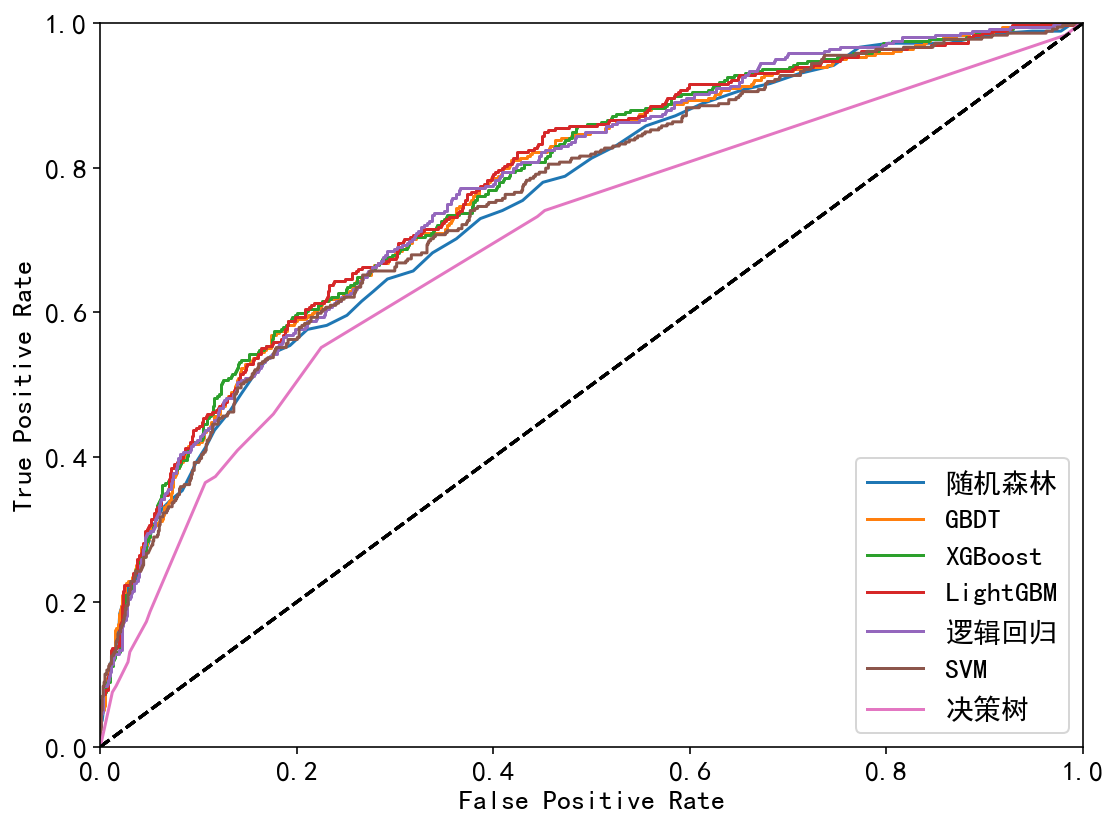 |














 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









