







 本文详细介绍如何使用Apache Spark处理复杂数据结构,将包含多种状态(如yes、maybe、invited、no)的数据转换为统一的(eventuseridstatus)格式,通过实例演示了数据过滤、映射及拼接过程。
本文详细介绍如何使用Apache Spark处理复杂数据结构,将包含多种状态(如yes、maybe、invited、no)的数据转换为统一的(eventuseridstatus)格式,通过实例演示了数据过滤、映射及拼接过程。
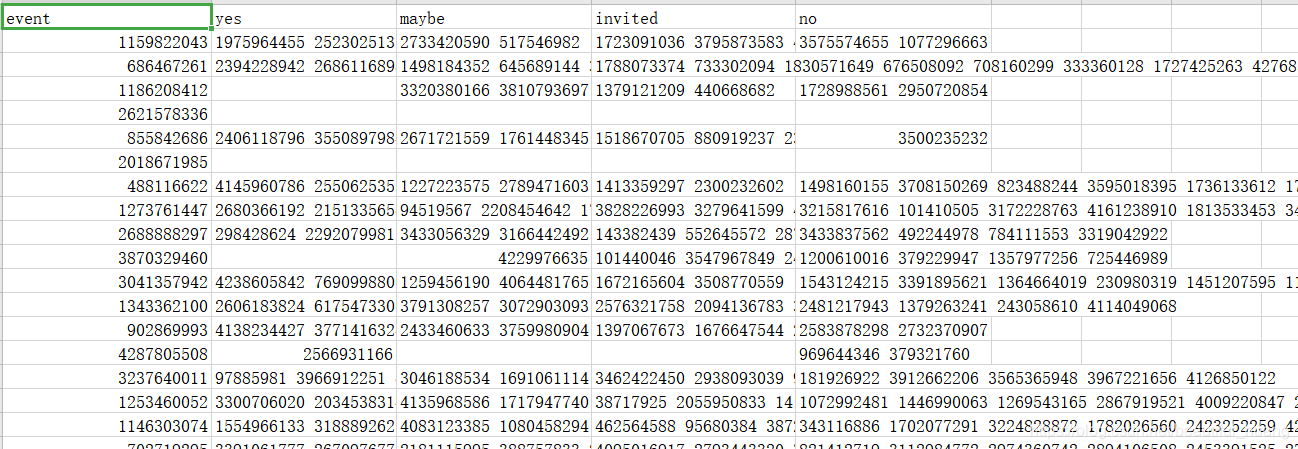
转换之前先看下数据结构
多行存在空值需要过滤,不同的状态(yes、maybe、invited、no)存在多个值,需要转换成(events userid status)的状态
首先考虑单独两行映射
val df = spark.read.format("csv").option("header","true").load("file:///opt/data/event_attendees.csv")
scala> df.printSchema
root
|-- event: string (nullable = true)
|-- yes: string (nullable = true)
|-- maybe: string (nullable = true)
|-- invited: string (nullable = true)
|-- no: string (nullable = true
df.filter(col("yes").isNotNull).select(col("event"),col("yes")).withColumn("userid",explode(split(col("yes")," "))).drop($"yes").withColumn("status",lit("yes")).show(3)
+----------+----------+------+
| event| userid|status|
+----------+----------+------+
|1159822043|1975964455| yes|
|1159822043| 252302513| yes|
|1159822043|4226086795| yes|
+----------+----------+------+
only showing top 3 rows
同理 将其余隔行依次映射
scala> val no = df.filter(col("no").isNotNull).select(col("event"),col("no")).withColumn("userid",explode(split(col("no")," "))).drop($"no").withColumn("status",lit("no"))
+----------+----------+------+
| event| userid|status|
+----------+----------+------+
|1159822043|3575574655| no|
|1159822043|1077296663| no|
|1186208412|1728988561| no|
+----------+----------+------+
only showing top 3 rows
no: Unit = ()
scala> val invited = df.filter(col("invited").isNotNull).select(col("event"),col("invited")).withColumn("userid",explode(split(col("invited")," "))).drop($"invited").withColumn("status",lit("invited")).show(3)
+----------+----------+-------+
| event| userid| status|
+----------+----------+-------+
|1159822043|1723091036|invited|
|1159822043|3795873583|invited|
|1159822043|4109144917|invited|
+----------+----------+-------+
only showing top 3 rows
invited: Unit = ()
scala> val maybe = df.filter(col("maybe").isNotNull).select(col("event"),col("maybe")).withColumn("userid",explode(split(col("maybe")," "))).drop($"maybe").withColumn("status",lit("maybe")).show(3)
+----------+----------+------+
| event| userid|status|
+----------+----------+------+
|1159822043|2733420590| maybe|
|1159822043| 517546982| maybe|
|1159822043|1350834692| maybe|
+----------+----------+------+
only showing top 3 rows
maybe: Unit = ()
进行拼接
scala> yes.union(no).union(maybe).union(invited).show()
+----------+----------+------+
| event| userid|status|
+----------+----------+------+
|1159822043|1975964455| yes|
|1159822043| 252302513| yes|
|1159822043|4226086795| yes|
|1159822043|3805886383| yes|
|1159822043|1420484491| yes|
|1159822043|3831921392| yes|
|1159822043|3973364512| yes|
| 686467261|2394228942| yes|
| 686467261|2686116898| yes|
| 686467261|1056558062| yes|
| 686467261|3792942231| yes|
| 686467261|4143738190| yes|
| 686467261|3422491949| yes|
| 686467261| 96269957| yes|
| 686467261| 643111206| yes|
| 686467261|1267277110| yes|
| 686467261|1602677715| yes|
| 686467261| 175167653| yes|
| 855842686|2406118796| yes|
| 855842686|3550897984| yes|
+----------+----------+------+
only showing top 20 rows
scala> yes.union(no).union(maybe).union(invited).count()
res15: Long = 11245010
补充 :超强合集 一遍打完收工
val dfResult = Seq("yes","maybe","invited","no").map(s =>dfAttendees.select($"event".as("event_id"),col(s)).withColumn("user_id",explode(split(col(s)," "))).withColumn("attend_type",lit(s)).drop(s)).reduce((df1,df2)=>df1.union(df2))

















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









