






#AI #GPU
最近在进行AI服务器配置,在预算有限情况下,A100/H100等皇卡买不起情况下,考虑选择A40/L40,结合可公开发售的L20,与上代皇卡V100进行性能比较。
以下是NVIDIA V100、A40、L40和L20 GPU的关键性能参数对比表:
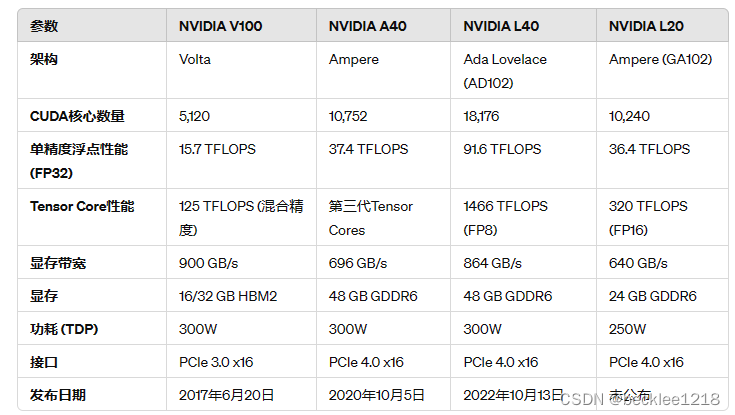
性能对比总结
- CUDA核心数量:L40 > A40 > L20 > V100
- 单精度浮点性能 (FP32):L40 > A40 > L20 > V100
- Tensor Core性能:L40 (FP8) > L20 (FP16) > A40 > V100
- 显存带宽:V100 > L40 > A40 > L20
- 显存容量:A40, L40 > L20 > V100
从中可以看出L40在多个方面的性能表现都优于其他型号,尤其适合高计算量的深度学习和大语言模型训练任务
二、多块GPU组成的AI服务器,NVlink与PCIe对性能影响非常大
例如比较8块NVIDIA A40、L40和L20 GPU在大语言模型训练中的算力性能时,考虑到GPU之间的PCIe 4.0和NVLink传输速率的影响非常重要。这些传输速率会直接影响到GPU之间的数据传输效率,从而影响到整体训练性能。
传输速率对比
PCIe 4.0
- 带宽: 每条PCIe 4.0通道的单向带宽为16 GT/s(大约2 GB/s)。
- 总带宽: x16配置下,双向总带宽为32 GB/s。
NVLink
- NVLink 2.0: 每个连接提供25 GB/s的单向带宽,双向为50 GB/s。
- NVLink 3.0: 每个连接提供50 GB/s的单向带宽,双向为100 GB/s。
- NVLink 4.0(如适用): 每个连接提供更高的带宽,具体数值依GPU型号而异。
各GPU的传输配置
- A40: 支持PCIe 4.0和第三代NVLink。
- L40: 支持PCIe 4.0和最新的NVLink(具体版本和带宽视实际情况而定,目前显示的数据是不支持)。
- L20: 支持PCIe 4.0,可能不支持NVLink。
综合影响
在大语言模型训练中,GPU之间的数据交换频繁,较高的传输速率能够有效减少数据传输瓶颈,从而提升整体计算效率。
性能估算
根据各GPU的配置及传输速率,我们可以对它们在多卡配置下的性能进行估算:
8块A40
- 总计算性能: 299.2 TFLOPS
- NVLink传输速率: 每两个GPU之间的传输速率可达200 GB/s(四个NVLink 3.0连接,每个50 GB/s)。
- PCIe传输速率: 每块卡在x16配置下的双向总带宽为32 GB/s。
8块L40
- 总计算性能: 732.8 TFLOPS
- NVLink传输速率: 每两个GPU之间的传输速率可能更高(视具体NVLink版本,假设为300 GB/s)。
- PCIe传输速率: 每块卡在x16配置下的双向总带宽为32 GB/s。
8块L20
- 总计算性能: 291.2 TFLOPS
- PCIe传输速率: 每块卡在x16配置下的双向总带宽为32 GB/s。
- NVLink传输速率: 不支持。
综合考虑
- NVLink的高带宽连接对于需要频繁数据交换的大语言模型训练来说非常重要。A40和L40在这方面的优势显著。
- PCIe 4.0的总带宽虽然高,但在大规模多GPU训练中可能成为瓶颈,尤其是在模型规模和数据量极大的情况下。
结论
- L40: 在总计算性能和NVLink传输速率上都有显著优势,非常适合大语言模型训练。
- A40: 计算性能和传输速率均较高,适合大规模模型训练,但性能略逊于L40。
- L20: 计算性能和传输速率相对较低,适合中等规模训练任务。
因此,在8卡配置下,L40的总体性能和训练效率最佳,其次是A40,L20相对较弱,但L40和A40的真实差距,还需要真实环境下进行测试。本文仅作参数对比。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









