









全面剖析《自己动手写操作系统》第四章--FAT12文件系统 http://blog.csdn.net/zgh1988/article/details/7284834
1、突破512字节的限制
2、加载Loader进入内存
一、突破512字节的限制
一个操作系统从开机到开始运行,大致经历"引导—》加载内核入内存—》跳入保护模式—》开始执行内核"这样一个过程。也就是说,在内核开始执行之前不但要加载内核,还要准备保护模式等一系列工作,如果全部交给引导扇区来做,512字节很可能不够用,所以,不放把这个过程交给另外的模块来完成,我们把这个模块叫做Loader。引导扇区负责把Loader加载如内存并且把控制权交它,其他的工作放心地交给 Loader来做,因为它没有512字节的限制,将会灵活很多。
二、加载Loader进入内存
上一节我们已经详细介绍了FAT12文件系统的数据结构,下面我们需要思考的是两个问题:1、引导扇区通过怎样的步骤才能找到文件;2、如何能够把文件内容全都读出来并加载进入内存。
下面我们先解决第一个问题:
1、 如何读取软盘?
(1) 我们需要使用BIOS中断int 13h来读取软盘。它的用法如下表所示:
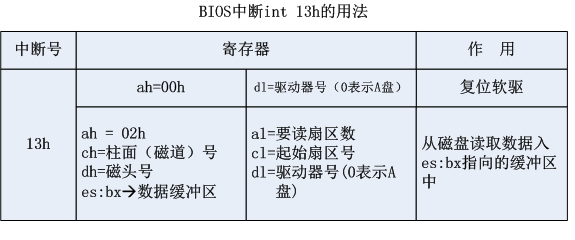
在这里我们只介绍了2种工作方式,中断int 13h还有其他的工作方式,如果需要可以自行查看内容。
(2) 由上表我们可以知道:当读取某些扇区时,需要柱面(磁道)号(ch),起始扇区号(cl),磁头号(dh)。我们如何通过计算得到这些数据呢?

(3) 现在万事俱备只欠东风了,下面我们就书写读取软盘扇区的函数ReadSector。
首先我们要知道该函数需要什么参数,这些参数存储在什么位置?
参数1:扇区号,存储在ax中
参数2:要读取扇区的个数,存储在cl中
参数3:数据缓冲区,即读取扇区数据后,将其存储在什么位置,用es:bx指向该缓冲区。
即函数的作用:从第ax个Sector开始,将cl个Sector读入es:bx中。
;-----------------------------------------------------------------------
;函数名:ReadSector
;------------------------------------------------------
;作用:从第ax个Sector开始,将cl个Sector读入es:bx中
ReadSector:
;---------------------------------------------
;怎样由扇区号求扇区在磁盘中的位置(扇区号->柱面号,起始扇区,磁头号)
;---------------------------------------------
;设扇区号为x
; ┌ 柱面号 = y >> 1
; x ┌ 商 y ┤
; -------------- => ┤ └ 磁头号 = y & 1
; 每磁道扇区数 │
; └ 余 z => 起始扇区号 = z + 1
;辟出两个字节的堆栈区间保存要读取的扇区数:byte[bp-2]
push bp
mov bp, sp
sub esp, 2
mov byte[bp-2], cl ;将参数cl,存储在byte[bp-2],将要读取扇区的个数。
push bx ;保存bx,因为下面要使用bx进行计算。
mov bl, [BPB_SecPerTrk] ;bl:除数=18
;ax存储的是扇区号,bl是每磁道扇区数,执行ax/bl=al----ah,
;即商y在al中,商z在ah中。
div bl
inc ah ;ah(z)++,即起始扇区号=z+1,
mov cl, ah ;将ah值赋值给cl,中断int 13h中,cl保存的恰好是起始扇区号
mov dh, al ;将al(y),赋值给dh
shr al, 1 ;对al(y)进行右移一位,即得到柱面号=y>>1,
mov ch, al ;然后将al赋值给ch,在中断int 13h中,ch保存着柱面(磁道)号
and dh, 1 ;将dl(y)进行&1运算,即得到磁头号=y&1,在中断int 13h中,dh保存着
;磁头号
pop bx ;恢复bx值
;到此为止,“柱面(磁道)号(ch),起始扇区号(cl),磁头号(dh),缓冲地址(es:bx)”全部准备就绪
mov dl, [BS_DrvNum] ;在中断int 13中,dl保存着驱动器号。此时dl=[BS_DrvNum]=0
.GoOnReading:
;下面对ah,al进行赋值,ah=2,al=要读取的扇区数,前面将参数cl存储在byte[bp-2],现在从这里重新获取
;并赋值给al。
mov ah, 2
mov al, byte[bp-2]
;中断int 13一切准备就绪,然后执行int 13
int 13h
jc .GoOnReading ;如果读取错误,CF会被置为1,这时就不停地读,直到正确为止。
add esp, 2 ;恢复堆栈
pop bp
ret
2、 如何在软盘中寻找Loader.bin文件
(1) 结合上一节所介绍的FAT12数据结构,从中我们可以知道,要寻找一个文件,首先需要在根目录区中寻找该文件的根目录条目;然后根据根目录条目获取文件开始簇数(也就是在数据区中存储的扇区);最后读取文件内容到内存。
(2) 嗯,是的,下面就让我们来完成第一步-----在根目录区中寻找该文件的根目录条目。
让我们开始思考这个问题,
首先要知道根目录区的开始扇区号是19,也就是说从第19扇区开始,根目录区占用扇区总数为14,也就是说,如果不能发现Loader.bin,需要将14个扇区都进行查找,于是需要一个大的循环在外围,控制着扇区的读取。
紧接着,我们每读取一个扇区,一个扇区是512个字节,一个根目录条目占32个字节,故一个扇区中存在512/32=16个根目录条目,所以需要添加一个循环,控制根目录条目的变化,从0—16进行循环。
最后,针对每一个根目录条目,我们只是要比较文件名,一个根目录条目的文件名占用11个字节,所以需要对每一个字节与"LOADER BIN"中的每一个字节进行比较,所以还是要添加一个循环,来控制字符的变化,即从0—11.
用C语言来表示该问题就是:
for( i = 根目录区的起始扇区号(19); i < 根目录区占有的扇区数(14); i++) {
for( j = 0;j < 一个扇区内存储的根目录条目个数(512/32=16); j++) {
for(k =0; k < 根目录条目中文件名占用的空间(11个字符); k++) {
if(k=10)jmp LABEL_FILENAMEFOUND
if(ds:si= es:di) si++; di++;
else break;
}
}
}
(3) 下面让我们来分析代码:
首先需要介绍下面可能需要用到的几个变量值:
BaseOfLoader equ 09000h ;LOADER.BIN被加载到的位置---段地址
OffsetOfLoader equ 0100h ;LOADER.BIN被加载到的位置---偏移地址
RootDirSectors equ 14 ;根目录占用空间(BPB_RootEntCnt*32+511)/512
SectorNoOfRootDirectory equ 19 ;Root Directory 的第一个扇区号
;变量
wRootDirSizeForLoop dw RootDirSectors ;Root Directory占用的扇区数,在循环中会递减至0
wSectorNo dw 0 ;要读取的扇区号
bOdd db 0 ;奇数还是偶数
;字符串
LoaderFileName db "LOADER BIN", 0 ;LOADER.BIN之文件名
;调用中断int 13h,实现软驱复位
xor ah, ah
xor dl, dl
int 13h
;下面在A盘的根目录中寻找LOADER.BIN
;wSectorNo表示要读取的扇区号,SectorNoOfRootDirectory
;表示根目录区的开始扇区号=19
mov word[wSectorNo], SectorNoOfRootDirectory
LABEL_SEARCH_IN_ROOT_DIR_BEGIN:
;wRootDirSizeForLoop=RootDirSectors,表示根目录占用的扇区数,即表示要读取的扇区数;也就是
;最外部循环中的控制变量(相当于i)。
;判断根目录区所有扇区是不是已经读取完毕,如果读完表示没有找到LOADER.BIN,
;跳入到LABEL_NO_LOADERBIN,否则,减1。
cmp word[wRootDirSizeForLoop], 0
jz LABEL_NO_LOADERBIN
dec word[wRootDirSizeForLoop]
;为ReadSector函数准备参数,从第ax个Sector开始读,将cl个Sector读入es:bx中
mov ax, BaseOfLoader
mov es, ax ;es<-BaseOfLoader
mov bx, OffsetOfLoader ;bx<-OffsetOfLoader,于是es:bx=BaseOfLoader:OffsetOfLoader
mov ax, [wSectorNo] ;ax<-Root Directory中的某Sector号,表示要读取的扇区号
mov cl, 1 ;cl表示要读取扇区个数=1
call ReadSector
;调用ReadSector函数之后,es:bx将存储该扇区数据。
mov si, LoaderFileName ;ds:si->"LOADER BIN"
mov di, OffsetOfLoader ;es:di->BaseOfLoader:OffsetOfLoader=es:bx
;即es:di指向存储的该扇区数据
cld
;一个扇区是512个字节,一个根目录项占32个字节,故512/32=16,因此需要比较16个根目录项的文件名,
;故赋值dx=16,由dx来控制循环次数
mov dx, 10h
LABEL_SEARCH_FOR_LOADERBIN:
;判断dx是否为0,0意味着这个扇区内的所有根目录项进行比较完毕,然后跳入到下一个扇区,继续进行比较,
;dx=0,则跳入LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR;否则,dx--
cmp dx, 0
jz LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR
dec dx
;一个根目录项的文件名占用11个字节,故必须对其每个字节与"LOADER BIN"一一对比
;故赋值cx=11,由cx来控制循环次数
mov cx, 11
LABEL_CMP_FILENAME:
cmp cx, 0
jz LABEL_FILENAME_FOUND ;如果cx=0,意味着11个字符都相等,表示找到,跳转到LABEL_FILENAME_FOUND
dec cx ;否则,cx--
lodsb ;ds:si->al,ds:si指向的是字符串"LOADER BIN"
cmp al, byte[es:di] ;进行一个字符的比较,如果相等,则比较下一个字符,
jz LABEL_GO_ON ;跳入到LABEL_GO_ON
jmp LABEL_DIFFERENT ;只要发现有一个不相等的字符就表明本Directory Entry不是我们要
;找的LOADER.BIN,跳转到LABEL_DIFFERENT,进如下一个Directory Entry比较。
LABEL_GO_ON:
inc di ;将di++,进行一个字符的比较。
jmp LABEL_CMP_FILENAME ;跳转到LABEL_CMP_FILENAME,继续进行文件名比较。
LABEL_DIFFERENT:
;di&=E0是为了让它指向本条目开头,di初始化为某个条目开头,
;在比较过程中,会将它不断增1,当失败之后,必须进行重新初始化
;因为一个条目占用32个字节,故and di,0FFE0h add di, 20h
;之后,di就指向了下一个条目
and di, 0FFE0h
add di, 20h
;重新初始化si,使其指向"LOADER BIN"的开始位置
mov si, LoaderFileName
jmp LABEL_SEARCH_FOR_LOADERBIN ;跳转到LABEL_SEARCH_FOR_LOADERBIN
LABEL_GOTO_NEXT_SECTOR_IN_ROOT_DIR:
add word[wSectorNo], 1 ;将要读取的扇区号+1,进行下一个扇区的比较
jmp LABEL_SEARCH_IN_ROOT_DIR_BEGIN ;跳转到LABEL_SEARCH_IN_ROOT_DIR_BEGIN,开始一个扇区的比较
;如果最后没有找到"LOADER BIN",则显示“NO LOADER”字符串来表示。
LABEL_NO_LOADERBIN:
mov dh, 2 ;"NO LOADER"
call DispStr ;显示字符串
%ifdef _BOOT_DEBUG_
mov dh, 2 ;"NO LOADER"
call DispStr ;显示字符串
mov ax, 4C00h
int 21h ;没有找到LOADER.BIN,返回到DOS
%else
jmp $ ;没有找到LOADER.BIN,死循环在这里
%endif
;如果找到"LOADER BIN",则跳转到LABEL_FILENAME_FOUNT,然后进行第二步骤,从
;Directory Entry中读取文件在数据区的开始簇号。
LABEL_FILENAME_FOUND:
(4) 对上面这段代码画出它的简易流程图如下:

3、 如何将Loader.bin文件加载到内存?
现在我们已经有了Loader.bin的起始扇区号,我们需要用这个扇区号来做两件事情:一件是把起始扇区装入内存,另一件则是通过它找到FAT中的项,从而找到Loader占用的其余所有扇区。
此时装入一个扇区对我们来说已经是很轻松的事了,可从FAT中找到一个项还是多少有些麻烦,下面我们就根据扇区号去FAT表中找到相应的项。在这里,将要写一个函数GetFATEntry,函数的输入就是扇区号(ax),输出则是其对应的FAT项的值(ax)。
我们一起来思考这个函数如何去实现,我们知道了扇区号x,然后我们去FAT1中寻找x所对应的FATEntry,我们已经知道一个FAT项占1.5个字节。所以我们用x*3/2=y………z,y为商(偏移量)(字节),相对于FAT1的初始位置的偏移量;Z为余数(0或者1),是判断FATEntry是奇数还是偶数,0表示偶数,1表示奇数。然后我们让y/512=m………n,m为商,n为余数,此时m为FATEntry所在的相对扇区,n为在此扇区内的偏移量(字节)。因为FAT1表前面还有1个引导扇区,所以FATEntry所在的实际扇区号为m+1。然后读取m+1和m+2两个扇区,然后在偏移n个字节处,取出FATEntry,相当于读取两个字节。此时再利用z,如果z为0的话,此FAT项为前一个字节和后一个字节的后4位,如果z为1的话,此FATEntry取前一个字节的前4位和后一个字节。
下面我们实现GetFATEntry函数,函数的输入就是扇区号,输出则是其对应的FATEntry的值。
;-----------------------------------------------------
;函数名:GetFATEntry
;-----------------------------------------------------
;作用: 找到序号为ax的Sector在FAT中的条目,结果放在ax中,需要注意的是,中间需要读FAT的扇区es:bx处,
; 所以函数一开始保存了es和bx
GetFATEntry:
push es
push bx
push ax
;在BaseOfLoader后面留出4K空间用于存放FAT
mov ax, BaseOfLoader
sub ax,0100h
mov es, ax ;此时es-> (BaseOfLoader - 100h)
pop ax ;ax存储的是要读取的扇区号
mov byte[bOdd], 0
;ax是要读取的扇区号,如何获得该扇区号在FAT1中的FATEntry
;因为每个FATEntry占有1个半字节,所以计算ax*3/2,找到该FATEntry所在FAT1中的偏移量
mov bx, 3
mul bx
mov bx, 2
div bx
;ax*3/2=ax...dx,商为ax表示该FATEntry在FAT1中的偏移量,dx的值为(0或者1),
;0表示该FATEntry为偶数,1表示该FATEntry为奇数,
cmp dx, 0
jz LABEL_EVEN
;我们使用byte[bOdd]来保存dx的值,也就是该FATEntry是奇数项还是偶数项。
mov byte[bOdd], 1
LABEL_EVEN:
xor dx, dx
;此时ax中保存着FATEntry在FAT1中的偏移量,下面来计算FATEntry
;在哪个个扇区中(FAT1占用9个扇区)。
;ax/BPB_BytsPerSec=ax/512=ax...dx,商ax存储着该FATEntry所在FAT1表的第几个扇区,
;余数dx保存着该FATEntry在该扇区内的偏移量。
mov bx, [BPB_BytsPerSec]
div bx
push dx ;将dx存储在堆栈中.
mov bx, 0 ;es:bx=(BaseOfLoader-100):00=(BaseOfLoader-100h)*10h
;我们知道ax是FATEntry所在FAT1中的相对扇区,而FATEntry所在的实际扇区,需要加上
;FAT1表的开始扇区号,即加1,之后ax就是FATEntry所在的实际扇区
add ax, SectorNoOfFAT1
mov cl, 2
;读取FATEntry所在的扇区,一次读2个,避免在边界发生错误,
;因为一个FATEntry可能跨越两个扇区
call ReadSector
;从堆栈中弹出dx,FATEntry所在扇区的偏移量,将其与bx相加,此时es:bx指向的是该FATEntry所占用
;的两个字节空间
pop dx
add bx, dx
;读取该FATEntry
mov ax, [es:bx]
;下面是对bOdd进行判断,如果其为0,则表示FATEntry为偶数,此时需要取byte1和byte2的后4位,
;由于在80x86下,从内存中读取数据之后,byte2在前,byte1在后。
;所以当FATEntry为偶数时,需要将ax&0FFF,将byte2的前4位置0.
;反之,如果bOdd为1,则表示FATEntry为奇数,此时需要取得byte1中的前4位和byte2.
;所以,需要将ax右移4位,将byte1的后四位移除。
cmp byte[bOdd], 1
jnz LABEL_EVEN_2
shr ax, 4
LABEL_EVEN_2:
and ax, 0FFFh
;此时ax存储的是FATEntry的值
LABEL_GET_FAT_ENTRY_OK:
pop bx
pop es
ret
;--------------------------------------------------------------------
下面我们开始加载Loader.bin进入内存。
首先我们从根目录区中的Loader.bin的条目,获取文件的起始扇区号,然后加上BPB_RsrvSecCnt+BPB_FATSz16*2-2+RootDirSectors=1+(9*2)+14-2=31,,其中DeltaSectorNo=BPB_RsrvSecCnt+BPB_FATSz16*2-2=17。得到的结果才是文件的实际的起始扇区。获得起始扇区后,我们就可以调用ReadSector来读取扇区了。然后从FAT1表中获取FATEntry的值,判断是否为0FFFh,如果是,结束加载;如果不为0FFFh,意味着该文件没有读取完成,需要读取下一个扇区,此时的FATEntry的值,就是下一个扇区号,再将其转换为实际扇区号,再进行读取。
下面是函数的实现和注释
LABEL_FILENAME_FOUND: ;找到了LOADER.BIN后便来到这里继续
mov ax, RootDirSectors ;根目录区所占用扇区数=14
and di, 0FFE0h ;di->当前Directory Entry的开始位置
add di, 01Ah ;di->此条目对应的开始簇号,DIR_FstClus
mov cx, word[es:di] ;将开始簇号存储在寄存器cx中
push cx ;将cx入栈
;实现cx+RootDirSectors+DeltaSectorNo之后,此时cx保存着文件的实际开始扇区号,
;即数据区内的扇区
add cx, ax
add cx, DeltaSectorNo
mov ax, BaseOfLoader
mov es, ax
mov bx, OffsetOfLoader ;es:bx=BaseOfLoader:OffsetOfLoader
mov ax, cx ;ax表示要读取的扇区号
LABEL_GOON_LOADING_FILE:
push ax
push bx
mov ah, 0Eh
mov al, '.'
mov bl, 0Fh
int 10h
pop bx
pop ax
;每读一个扇区就在”Booting “后面打一个点,形成这样的效果:Booting......
;继续为ReadSector函数的参数做准备,cl=1,表示要读取一个扇区
mov cl, 1
call ReadSector
pop ax ;读完一个扇区之后,然后重新读取此Sector在FAT中的序号
call GetFATEntry
cmp ax, 0FFFh
jz LABEL_FILE_LOADED
;如果读取的FAT值为FFF,表示该扇区为该文件的最后一个扇区,
;因此结束加载,也就是加载成功
;如果读取的FAT表中的值不是FFF,则表示还有扇区,故保存下一个扇区序号
push ax
mov dx, RootDirSectors
add ax, dx
add ax, DeltaSectorNo
add bx, [BPB_BytsPerSec]
;为call ReadSector的参数做准备,es:bx表示要缓存的地址,
;ax表示要读取的扇区号=DirEntry中的开始Sector号+根目录占用Sector数目+DeltaSectorNo
;进入下一次循环。
jmp LABEL_GOON_LOADING_FILE
LABEL_FILE_LOADED:
mov dh, 1 ;"Ready."
call DispStr ;显示字符串
《自己动手写操作系统》读后感 http://blog.csdn.net/zgh1988/article/details/7059936
全面剖析《自己动手写操作系统》第一章 http://blog.csdn.net/zgh1988/article/details/7060032
全面剖析《自己动手写操作系统》第二章 http://blog.csdn.net/zgh1988/article/details/7062065
全面剖析《自己动手写操作系统》第三章1 http://blog.csdn.net/zgh1988/article/details/7098981
全面剖析《自己动手写操作系统》--“实模式--保护模式--实模式” http://write.blog.csdn.net/postedit/7256254
全面剖析《自己动手写操作系统》--堆栈段的工作方式 http://blog.csdn.net/zgh1988/article/details/7256254
全面剖析《自己动手写操作系统》---特权级 以及 不同特权级代码段之间的跳转规则 http://blog.csdn.net/zgh1988/article/details/7262901
全面剖析《自己动手写操作系统》--分页机制 http://blog.csdn.net/zgh1988/article/details/7270748
全面剖析《自己动手写操作系统》--中断机制 http://blog.csdn.net/zgh1988/article/details/7276259














 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









