






一.下载并安装mongodb
详情见其他帖子这里就不加以叙述
二.在settings中打开PIPELINES并把数据库相应配置写入
ITEM_PIPELINES = {
'<spider_name>.pipelines.DouluodaluPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
# 端口号,默认27017
MONGODB_PORT = 27017
# 设置数据库名称
MONGODB_DBNAME = 'douluodalu'
# 存放本数据的表名称
MONGODB_DOCNAME = 'douluodalu'
三.修改pipelines文件
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class DouluodaluPipeline(object):
def __init__(self):
# 获取setting主机名、端口号和数据库名称
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbname = settings['MONGODB_DBNAME']
# 创建数据库连接
client = pymongo.MongoClient(host=host,port=port)
# 指向指定数据库
mdb = client[dbname]
# 获取数据库里面存放数据的表名
self.post = mdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
data = dict(item)
# 向指定的表里添加数据
self.post.insert(data)
return item
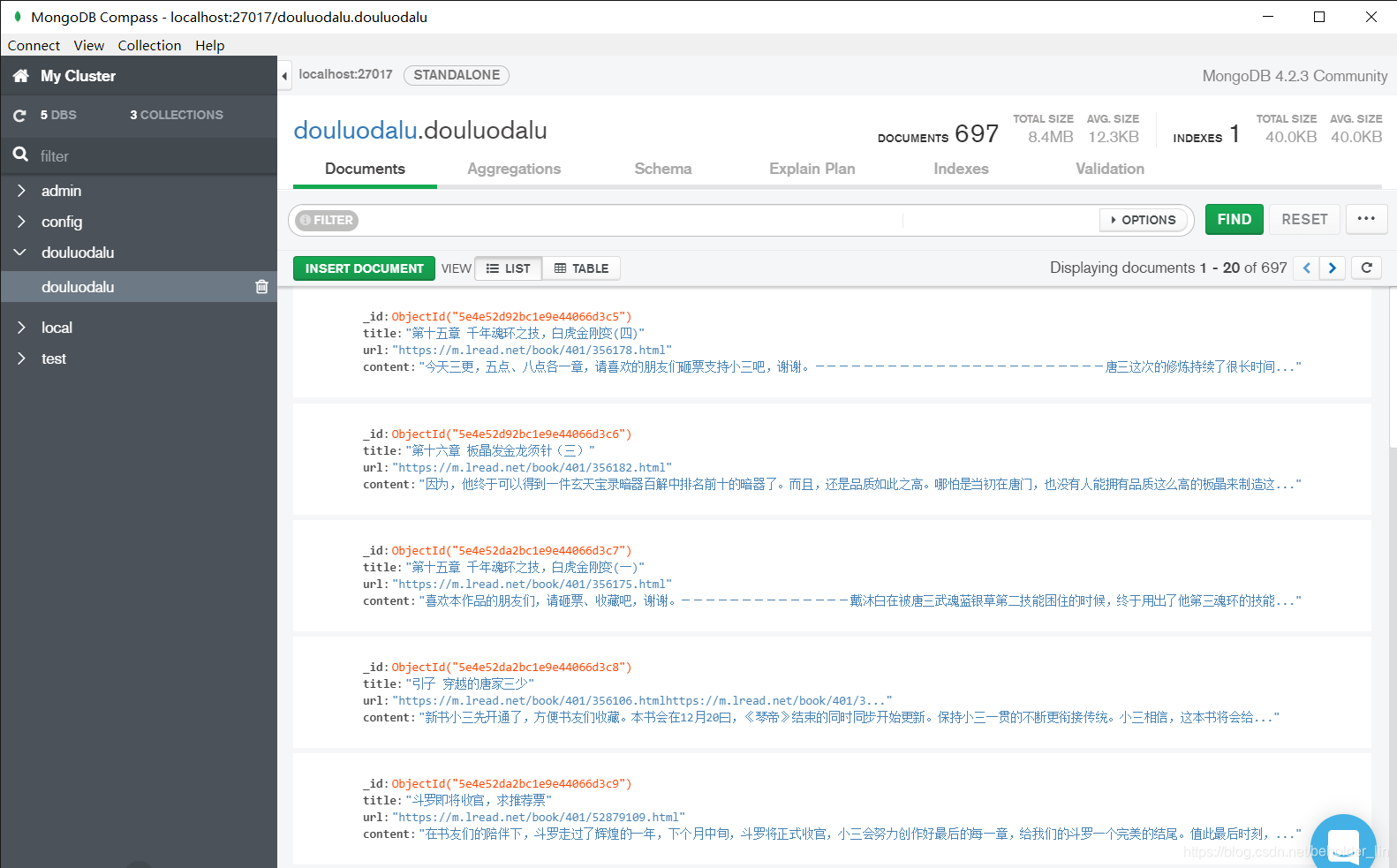
之后运行爬虫,在命令行中或其他 MongoDB GUI中查看数据是否入库















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









