







镜像集群模式(RabbitMQ的HA方案)
rabbitmq镜像集群依赖于普通集群,所以需要先搭建rabbitmq普通集群
镜像集群模式其实就是把需要的队列做成镜像队列,然后将镜像队列放在多个节点当中,这种镜像集群模式解决了普通集群模式没有做到的高可用性的缺点,镜像集群模式属于RabbitMQ的高可用性的集群部署方案。
普通队列进程及其内容仅仅维持在单个节点之上,所以一个节点的失效表现为其对应的队列不可用。
引入镜像队列(Mirror Queue)的机制,可以将队列镜像到集群中的其他Broker节点之上,如果集群中的一个节点失效了,队列能够自动切换到镜像中的另一个节点上以保证服务的可用性。
针对每个队列的(以下简称镜像队列)都包含一个主节点(master)和若干个从节点(slave)
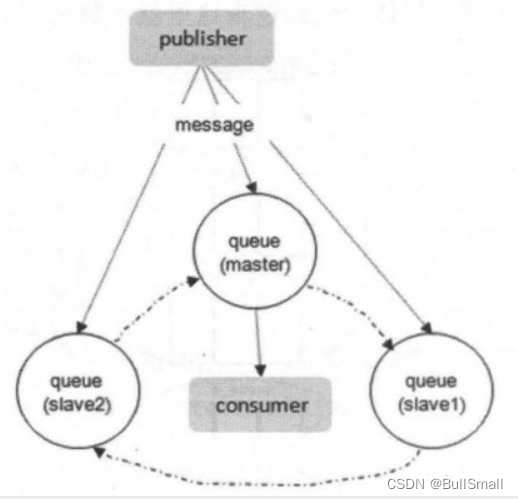
由图可知master和slave组成了一个链表结构。
slave会准确地按照maste执行命令地顺序进行动作,故slave和master上维护的状态应该是相同的。如果master由于某种原因失效,那么“资历最老”(基于slave加入cluster的时间排序)的slave会被提升为新的master。发送到镜像队列的所有消息会被同时发往 master和所有的slave上,如果此时master挂掉了,消息还会在slave上,这样slave提升为 master的时候消息也不会丢失
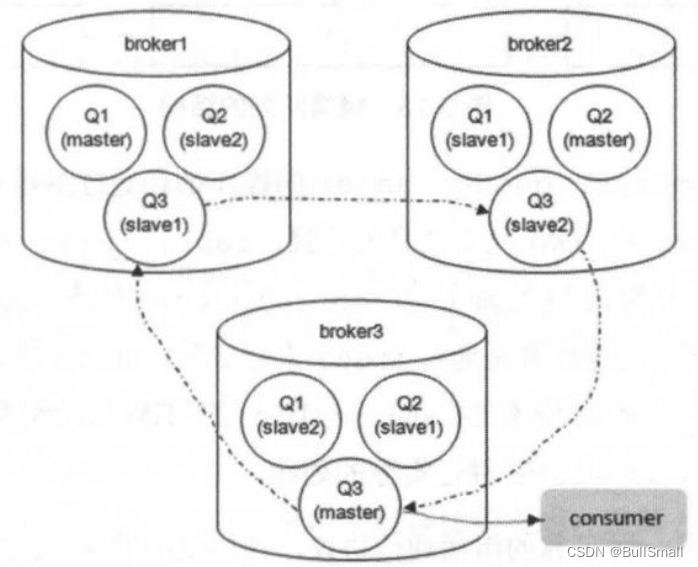
集群中的每个 Broker 节点都包含 1 个队列的 master 和 2 个队列的 slave, Q1 的负载大多都在 broker1 上,Q2 的负载大多都集中在 broker2 上,Q3 的负载大多都集中在 broker3 上,只要确保队列的 master 节点均匀散落在集群中的各个 Broker 节点即可确保很大程度的负载均衡。
master提供读写服务,在slave上的操作都会路由到master上,slave只做备份-主备切换
RabbitMQ 的镜像队列同时支持publisher confirm和事务两种机制
当slave挂掉之后,除了与slave相连的客户端连接全部断开,没有其他影响;
当master挂掉之后,会有以下影响:
- 与master连接的客户端连接全部断开;
- 选举最老的slave作为新的master,因为最老的slave与旧的master之间的同步状态应该是最好的。如果此时所有slave处于未同步状态,则未同步的消息会丢失;
- 新的master重新入队所有unack的消息,因为新的slave无法区分这些unack的消息是否己经到达客户端,或者是ack信息丢失在老的master链路上,再或者是丢失在老的master
组播ack消息到所有slave的链路上,所以出于消息可靠性的考虑,重新入队所有unack的消息,不过此时客户端可能会有重复消息; - 如果客户端连接着slave,并且Basic.Consume 消费时指定了x-cancel-on-ha-failover参数,那么断开之时客户端会收到一个Consumer Cancellation Notification的通知,消费者客户端中会回调Consumer接口的handleCancel方法。如果未指定x-cancel-on-ha-failover参数,那么消费者将无法感知master 宕机;
当所有slave都出现未同步状态,并且ha-prornote-on-shutdown设置为when-synced(默认)时,如果master因为主动原因停掉,比如通过rabbitrnqctl stop命令或者优雅关闭操作系统,那么slave不会接管master,也就是此时镜像队列不可用。但是如果master因为被动原因停掉,比如Erlang虚拟机或者操作系统崩溃,那么slave会接管master。这个配置项隐含的价值取向是保证消息可靠不丢失,同时放弃了可用性。如果ha-prornote-on-shutdown设置为always ,那么不论master因为何种原因停止,slave都会接管master,优先保证可用性,不过消息可能会丢失。
镜像队列中最后一个停止的节点会是master,启动顺序必须是master先启动。如果slave先启动,它会有30 秒的等待时间,等待master的启动,然后加入到集群中。如果30 秒内 master没有启动,slave会自动停止。当所有节点因故(断电等)同时离线时,每个节点都认为自己不是最后一个停止的节点,要恢复镜像队列,可以尝试在30秒内启动所有节点。
镜像队列间的消息流转
当消费者与master队列建立连接,消费者可以直接从master队列上获取信息,当消费者与slave队列建立连接呢?消费者是从slave队列直接获取数据的吗?当然不是的,消息的流转顺序如下所示:
- slave队列先将消费者的请求转发给master队列
- 然后再由master队列准备好数据返回给slave队列
- 最后由slave队列将消息返回给消费者
那这样就会有一个疑问?消费者的请求都是由master队列进行处理的,那么消息的负载是不是不能够做到有效的均衡呢?
负载均衡
Rabbit MQ的负载均衡是体现在物理机器层面上的,而不是体现在内存中的队列层面的。这样解释吧,现在有3台物理机,需要创建3个master队列和6个slave队列, 消息的请求负载都在3个master队列上,那么只需要将3个master队列和6个slave队列均匀的分布在3台物理机上,这样在很大程度上实现了每台机器的负载均衡。当然每个master队列消息请求的数量可能会有不同,无法保持绝对的负载均衡。
消息的可靠性
RabbitMQ的镜像队列使用 publisher confirm 和事务两种机制来保证其消息的可靠性。在事务机制中,只有当前事务在全部镜像中执行之后,客户端才会收到 Tx Commit-Ok 的消息。同样的,在 publisher confirm 机制中,生产者进行当前消息确认的前提是该消息被全部进行所接收了。
镜像集群模式总结
镜像队列的引入可以极大地提升 RabbitMQ 的可用性及可靠性,提供了数据冗余备份、避免单点故障的功能,因此推荐在实际应用中为每个重要的队列都配置镜像。
说了这么多的镜像队列的优点,那么镜像队列就没有缺点了吗?当然不是,那么镜像集群的缺点是什么呢?
首先镜像队列需要为每一个节点都要同步所有的消息实体,所以会导致网络带宽压力很大。 提供了数据的冗余备份,会导致存储压力变大,可能会出现IO瓶颈。
总结
普通集群模式增加了RabbitMq系统的吞吐量,但不能实现系统的高可用,如果磁盘节点崩溃可能会导致数据丢失,不能再对队列、交换器、绑定关系、用户进行更改,更改权限、添加或删除集群节点也不能操作。镜像集群模式是RabbitMq的HA部署方案,极大地提升 RabbitMQ 的可用性及可靠性,提供了数据冗余备份、避免单点故障的功能。但是镜像队列需要为每一个节点都要同步所有的消息实体,所以会导致网络带宽压力很大。 提供了数据的冗余备份,会导致存储压力变大,可能会出现IO瓶颈。具体怎样选择还需要使用者根据实际的业务场景选择合适的部署方案。















 1373
1373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









