






嵌套循环
哈希连接
因为oracle基于成本的优化器一般最长使用的就是这两种连接方式,而性能在这里也可以很好的调节。hash连接需要耗费大量的cpu和内存,而嵌套循环则会少很多。
在大数据量的双表连接中,哈希连接明显要有更好的性能。但是当一个小数量级的表和一个大数量级别的表连接的时候,优化就很难处理了。我在oracle这里现在最大的问题就
在这里。这是一个实例。
表信息:
pl_repay
记录数 15265146
索引 due_bill pl_repay_ind1
repay_dt pl_repay_ind2
repay_acct_type_cd pl_repay_ind3
cl_mid_ext_source
记录数 8604/16万
索引 due_bill ix_pl_mid_due_bill
脚本:
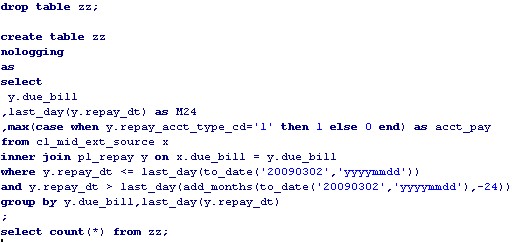
这是我写的一个测试sql,用来测试从pl_repay取到cl_mid_ext_source相关联的记录的集合的脚本。
这是最初始的执行计划
a:

这是删除掉where条件后的执行计划
b:

这是测试结果

分析a
监视服务器cpu占用情况,16万时保持在40%以上。
执行步骤
1.在pl_repay上的索引(repay_dt)pl_repay_ind2 的范围检索。事实上,这里需要检索的记录数是差不多700万。占表中数据的50%。
不知道是否限制索引会好些,有待测试。
2.在第一步结果集基础上,基于index rowid的全表扫描。
3.把cl_mid_ext_source全表扫描结果集放入内存,建立散列表。
4.在第二步的结果集上检索due_bill列和存入内存的表中相匹配的行。
分析b
执行步骤
1.嵌套循环,检索pl_repay表中和cl_mid_ext_source中记录符合的记录。
2.全表扫描pl_repay 根据 index rowid,找出匹配的记录。
测试结果证明在小数据量的情况下,嵌套循环会有最佳的性能。
而在大数据量的情况下哈希连接会有更好的性能。
这里的问题就是,如何才能把去掉where后的嵌套循环连接方法,做到自己可控制。
使用提示 use_nl 后,并未获得和b一样的执行计划。
性能和哈希无差别。
这是我现在的一个大的疑问。















 723
723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









