







oozie安装好了之后,需要测试oozie的功能是否完整好使,官方已经给自带带了各种测试案例,可以通过官方提供的各种案例来学习oozie的使用,后续也可以把这些案例作为模板在企业实际中使用。
先把官方提供的各种案例给解压出来:
cd /export/servers/oozie4.1.0
tar -zxvf oozie-examples.tar.gz
创建统一的工作目录,便于集中管理oozie。企业中可任意指定路径。这里直接在oozie的安装目录下面创建工作目录
cd /export/servers/oozie4.1.0
mkdir oozie_works
下面的资源:
链接:https://pan.baidu.com/s/1a4G2bA8_CJd2S51062_nAg
提取码:g61y
1. 优化更新hadoop相关配置
1.1. yarn容器资源分配属性
yarn-site.xml:
<!--节点最大可用内存,结合实际物理内存调整 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
<!--每个容器可以申请内存资源的最小值,最大值 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3072</value>
</property>
<!--修改为Fair公平调度,动态调整资源,避免yarn上任务等待(多线程执行) -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!--Fair调度时候是否开启抢占功能 -->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<!--超过多少开始抢占,默认0.8-->
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>1.0</value>
</property>
1.2. mapreduce资源申请配置
设置mapreduce.map.memory.mb和mapreduce.reduce.memory.mb配置
否则Oozie读取的默认配置 -1, 提交给yarn的时候会抛异常Invalid resource request, requested memory < 0, or requested memory > max configured, requestedMemory=-1, maxMemory=8192
mapred-site.xml
<!--单个maptask、reducetask可申请内存大小 -->
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
</property>
1.3. 更新hadoop配置重启集群
重启hadoop集群:
sbin/stop-dfs.sh
sbin/stop-yarn.sh
sbin/mr-jobhistory-daemon.sh stop historyserver
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
重启oozie服务:
bin/oozied.sh stop
bin/oozied.sh start
2. Oozie调度shell脚本
2.1. 准备配置模板
cd /export/servers/oozie4.1.0
cp -r examples/apps/shell/ oozie_works/
准备待调度的shell脚本文件:
cd /export/servers/oozie4.1.0
vim oozie_works/shell/hello.sh
#!/bin/bash
echo "hello world" >> /export/servers/hello_oozie.txt
2.2. 修改配置模板
修改job.properties
cd /export/servers/oozie4.1.0/oozie_works/shell
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/shell
EXEC=hello.sh
- jobTracker:在hadoop2当中,jobTracker这种角色已经没有了,只有
resourceManager,这里给定resourceManager的IP及端口即可。 - queueName:提交mr任务的队列名;
- examplesRoot:指定oozie的工作目录;
- oozie.wf.application.path:指定oozie调度资源存储于hdfs的工作路径;
- EXEC:指定执行任务的名称。
修改workflow.xml
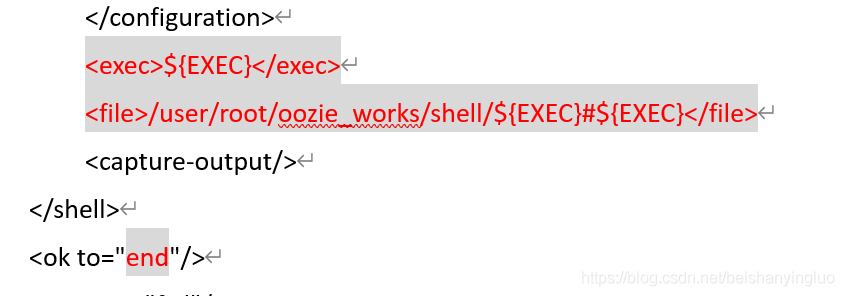
具体内容:
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>/user/root/oozie_works/shell/${EXEC}#${EXEC}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
2.3. 上传调度任务到hdfs
注意:上传的hdfs目录为/user/root,因为hadoop启动的时候使用的是root用户,如果hadoop启动的是其他用户,那么就上传到/user/其他用户
cd /export/servers/oozie4.1.0/
hdfs dfs -put oozie_works/ /user/root
2.4. 执行调度任务
通过oozie的命令来执行调度任务
cd /export/servers/oozie4.1.0/
bin/oozie job -oozie http://node-1:11000/oozie -config oozie_works/shell/job.properties -run
异常: 执行完后,在oozie控制台发现,失败了,查看日志:
cd /export/servers/oozie4.1.0/logs
cat oozie.log
显示:
org.apache.oozie.action.ActionExecutorException: JA017: Could not lookup launched hadoop Job ID
具体内容为:
Running bundle status service from last instance time = 2020-04-12T10:12+0800
2020-04-12 10:13:23,038 INFO StatusTransitService$StatusTransitRunnable:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[-] ACTION
[-] Released lock for [org.apache.oozie.service.StatusTransitService]
2020-04-12 10:13:23,113 INFO CallbackServlet:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[0000000-200412101008486-oozie-root-W
] ACTION[0000000-200412101008486-oozie-root-W@shell-node] callback for action [0000000-200412101008486-oozie-root-W@shell-node]
2020-04-12 10:13:23,127 INFO PauseTransitService:520 - SERVER[node01.hadoop.com] Acquired lock for [org.apache.oozie.service.PauseTransitService]
2020-04-12 10:13:23,141 WARN CompletedActionXCommand:523 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[] APP[-] JOB[0000000-200412101008486-oozie
-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] Received early callback for action still in PREP state; will wait [10,000]ms and reque
ue up to [5] more times
2020-04-12 10:13:23,156 INFO PauseTransitService:520 - SERVER[node01.hadoop.com] Released lock for [org.apache.oozie.service.PauseTransitService]
2020-04-12 10:13:28,621 WARN ShellActionExecutor:523 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-200412101008486
-oozie-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] Exception in check(). Message[JA017: Could not lookup launched hadoop Job ID [jo
b_local1191208584_0001] which was associated with action [0000000-200412101008486-oozie-root-W@shell-node]. Failing this action!]
org.apache.oozie.action.ActionExecutorException: JA017: Could not lookup launched hadoop Job ID [job_local1191208584_0001] which was associated with a
ction [0000000-200412101008486-oozie-root-W@shell-node]. Failing this action!
at org.apache.oozie.action.hadoop.JavaActionExecutor.check(JavaActionExecutor.java:1483)
at org.apache.oozie.action.hadoop.JavaActionExecutor.start(JavaActionExecutor.java:1412)
at org.apache.oozie.command.wf.ActionStartXCommand.execute(ActionStartXCommand.java:232)
at org.apache.oozie.command.wf.ActionStartXCommand.execute(ActionStartXCommand.java:63)
at org.apache.oozie.command.XCommand.call(XCommand.java:286)
at org.apache.oozie.service.CallableQueueService$CompositeCallable.call(CallableQueueService.java:332)
at org.apache.oozie.service.CallableQueueService$CompositeCallable.call(CallableQueueService.java:261)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.oozie.service.CallableQueueService$CallableWrapper.run(CallableQueueService.java:179)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2020-04-12 10:13:28,628 WARN ActionStartXCommand:523 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-200412101008486
-oozie-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] Error starting action [shell-node]. ErrorType [FAILED], ErrorCode [JA017], Messa
ge [JA017: Could not lookup launched hadoop Job ID [job_local1191208584_0001] which was associated with action [0000000-200412101008486-oozie-root-W@s
hell-node]. Failing this action!]
org.apache.oozie.action.ActionExecutorException: JA017: Could not lookup launched hadoop Job ID [job_local1191208584_0001] which was associated with a
ction [0000000-200412101008486-oozie-root-W@shell-node]. Failing this action!
at org.apache.oozie.action.hadoop.JavaActionExecutor.check(JavaActionExecutor.java:1483)
at org.apache.oozie.action.hadoop.JavaActionExecutor.start(JavaActionExecutor.java:1412)
at org.apache.oozie.command.wf.ActionStartXCommand.execute(ActionStartXCommand.java:232)
at org.apache.oozie.command.wf.ActionStartXCommand.execute(ActionStartXCommand.java:63)
at org.apache.oozie.command.XCommand.call(XCommand.java:286)
at org.apache.oozie.service.CallableQueueService$CompositeCallable.call(CallableQueueService.java:332)
at org.apache.oozie.service.CallableQueueService$CompositeCallable.call(CallableQueueService.java:261)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.oozie.service.CallableQueueService$CallableWrapper.run(CallableQueueService.java:179)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2020-04-12 10:13:28,632 WARN ActionStartXCommand:523 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-200412101008486
-oozie-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] Failing Job due to failed action [shell-node]
2020-04-12 10:13:28,641 WARN LiteWorkflowInstance:523 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-20041210100848
6-oozie-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] Workflow Failed. Failing node [shell-node]
2020-04-12 10:13:28,724 INFO WorkflowNotificationXCommand:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[0000000-200412101008486
-oozie-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] No Notification URL is defined. Therefore nothing to notify for job 0000000-2004
12101008486-oozie-root-W@shell-node
2020-04-12 10:13:28,749 INFO KillXCommand:520 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-200412101008486-oozie-
root-W] ACTION[] STARTED WorkflowKillXCommand for jobId=0000000-200412101008486-oozie-root-W
2020-04-12 10:13:28,767 INFO KillXCommand:520 - SERVER[node01.hadoop.com] USER[root] GROUP[-] TOKEN[] APP[shell-wf] JOB[0000000-200412101008486-oozie-
root-W] ACTION[] ENDED WorkflowKillXCommand for jobId=0000000-200412101008486-oozie-root-W
2020-04-12 10:13:28,771 INFO WorkflowNotificationXCommand:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[0000000-200412101008486
-oozie-root-W] ACTION[] No Notification URL is defined. Therefore nothing to notify for job 0000000-200412101008486-oozie-root-W
2020-04-12 10:13:33,165 ERROR CompletedActionXCommand:517 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[] APP[-] JOB[0000000-200412101008486-oozie
-root-W] ACTION[0000000-200412101008486-oozie-root-W@shell-node] XException,
org.apache.oozie.command.CommandException: E0800: Action it is not running its in [FAILED] state, action [0000000-200412101008486-oozie-root-W@shell-no
de]
at org.apache.oozie.command.wf.CompletedActionXCommand.eagerVerifyPrecondition(CompletedActionXCommand.java:92)
at org.apache.oozie.command.XCommand.call(XCommand.java:257)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.apache.oozie.service.CallableQueueService$CallableWrapper.run(CallableQueueService.java:179)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2020-04-12 10:14:23,555 INFO StatusTransitService$StatusTransitRunnable:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[-] ACTION
[-] Acquired lock for [org.apache.oozie.service.StatusTransitService]
2020-04-12 10:14:23,557 INFO StatusTransitService$StatusTransitRunnable:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[-] ACTION
[-] Running coordinator status service from last instance time = 2020-04-12T10:13+0800
2020-04-12 10:14:23,583 INFO StatusTransitService$StatusTransitRunnable:520 - SERVER[node01.hadoop.com] USER[-] GROUP[-] TOKEN[-] APP[-] JOB[-] ACTION
[-] Running bundle status service from last instance time = 2020-04-12T10:13+0800
另外:historyserver也没有内容!!!
解决办法:
在hadoop的 mapred-site.xml中,添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
重启hadoop集群,
再次执行,成功!!
3. Oozie调度Hive
3.1. 准备配置模板
cd /export/servers/oozie4.1.0/
cp -ra examples/apps/hive2/ oozie_works/
3.2. 修改配置模板
修改job.properties
cd /export/servers/oozie4.1.0/oozie_works/hive2
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
jdbcURL=jdbc:hive2://node01:10000/default
examplesRoot=oozie_works
oozie.use.system.libpath=true
# 配置我们文件上传到hdfs的保存路径 实际上就是在hdfs 的/user/root/oozie_works/hive2这个路径下
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/hive2
workflow.xml - 无修改!!!
编辑hivesql文件
vim script.q
DROP TABLE IF EXISTS test;
CREATE EXTERNAL TABLE test (a INT) STORED AS TEXTFILE LOCATION '${INPUT}';
insert into test values(10);
insert into test values(20);
insert into test values(30);
3.3. 上传调度任务到hdfs
cd /export/servers/oozie4.1.0/oozie_works/
hdfs dfs -put hive2/ /user/root/oozie_works/
遇到的问题:
界面上执行,一直处于 Running状态,过段时间, history其实已经显示成功,而且hive中查询到了新增的test数据,但此时,页面上的执行状态变为了Kiled:
初步认定,是因为执行时间太长,导致Oozie自身给kill了,具体原因未知
3.4. 执行调度任务
首先确保已经启动hiveServer2服务
cd /export/servers/apache-hive-2.1.1-bin
bin/hive --service hiveserver2
cd /export/servers/oozie4.1.0
bin/oozie job -oozie http://node01:11000/oozie -config oozie_works/hive2/job.properties -run
4. Oozie调度MapReduce
4.1. 准备配置模板
准备mr程序的待处理数据。用hadoop自带的MR程序来运行wordcount。
准备数据上传到HDFS的/oozie/input路径下去
hdfs dfs -mkdir -p /oozie/input
hdfs dfs -put wordcount.txt /oozie/input
拷贝MR的任务模板:
cd /export/servers/oozie4.1.0
cp -ra examples/apps/map-reduce/ oozie_works/
删掉MR任务模板lib目录下自带的jar包:
cd /export/servers/oozie4.1.0/oozie_works/map-reduce/lib
rm -rf oozie-examples-4.1.0-cdh5.14.0.jar
拷贝官方自带mr程序jar包到对应目录:
cp
/export/servers/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
/export/servers/oozie4.1.0/oozie_works/map-reduce/lib
4.2. 修改配置模板
修改job.properties
cd /export/servers/oozie4.1.0/oozie_works/map-reduce
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/map-reduce/workflow.xml
outputDir=/oozie/output
inputdir=/oozie/input
修改workflow.xml
cd /export/servers/oozie4.1.0/oozie_works/map-reduce
vim workflow.xml
<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.5" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!--
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
</property>
-->
<!-- 开启使用新的API来进行配置 -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定MR的输出key的类型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定MR的输出的value的类型-->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定输入路径 -->
<property>
<name>mapred.input.dir</name>
<value>${nameNode}/${inputdir}</value>
</property>
<!-- 指定输出路径 -->
<property>
<name>mapred.output.dir</name>
<value>${nameNode}/${outputDir}</value>
</property>
<!-- 指定执行的map类 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定执行的reduce类 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<!-- 配置map task的个数 -->
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
4.3. 上传调度任务到hdfs
cd /export/servers/oozie4.1.0/oozie_works/
hdfs dfs -put map-reduce/ /user/root/oozie_works/
4.4. 执行调度任务
cd /export/servers/oozie4.1.0
bin/oozie job -oozie http://node01:11000/oozie -config oozie_works/map-reduce/job.properties -run
错误:
Invalid sub-command: Missing required option: [-suspend suspend a job, -resume resume a job, -dryrun Dryrun a workflow (since
[root@node01 oozie4.1.0]# bin/oozie job -oozie http://node01:11000/oozie -config oozie_works/map-reduce/job.properties –run
Invalid sub-command: Missing required option: [-suspend suspend a job, -resume resume a job, -dryrun Dryrun a workflow (since 3.3.2) or coordinator (since 2.0) job without actually executing it, -submit submit a job, -log job log, -change change a coordinator or bundle job, -start start a job, -update Update coord definition and properties, -run run a job, -poll poll Oozie until a job reaches a terminal state or a timeout occurs, -kill kill a job (coordinator can mention -action or -date), -configcontent job configuration, -rerun rerun a job (coordinator requires -action or -date, bundle requires -coordinator or -date), -ignore change status of a coordinator job or action to IGNORED (-action required to ignore coord actions), -definition job definition, -info info of a job]
执行命令中出现了中文!!
5. Oozie任务串联
在实际工作当中,肯定会存在多个任务需要执行,并且存在上一个任务的输出结果作为下一个任务的输入数据这样的情况,所以我们需要在workflow.xml配置文件当中配置多个action,实现多个任务之间的相互依赖关系。
需求:首先执行一个shell脚本,执行完了之后再执行一个MR的程序,最后再执行一个hive的程序。
5.1. 准备工作目录
cd /export/servers/oozie4.1.0/oozie_works
mkdir -p sereval-actions
5.2. 准备调度文件
将之前的hive,shell, MR的执行,进行串联成到一个workflow当中。
cd /export/servers/oozie4.1.0/oozie_works
cp hive2/script.q sereval-actions/
cp shell/hello.sh sereval-actions/
cp -ra map-reduce/lib sereval-actions/
5.3. 修改配置模板
cd /export/servers/oozie4.1.0/oozie_works/sereval-actions
vim workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>/user/root/oozie_works/sereval-actions/${EXEC}#${EXEC}</file>
<capture-output/>
</shell>
<ok to="mr-node"/>
<error to="fail"/>
</action>
<action name="mr-node">
<map-reduce>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<!-- 开启使用新的API来进行配置 -->
<property>
<name>mapred.mapper.new-api</name>
<value>true</value>
</property>
<property>
<name>mapred.reducer.new-api</name>
<value>true</value>
</property>
<!-- 指定MR的输出key的类型 -->
<property>
<name>mapreduce.job.output.key.class</name>
<value>org.apache.hadoop.io.Text</value>
</property>
<!-- 指定MR的输出的value的类型-->
<property>
<name>mapreduce.job.output.value.class</name>
<value>org.apache.hadoop.io.IntWritable</value>
</property>
<!-- 指定输入路径 -->
<property>
<name>mapred.input.dir</name>
<value>${nameNode}/${inputdir}</value>
</property>
<!-- 指定输出路径 -->
<property>
<name>mapred.output.dir</name>
<value>${nameNode}/${outputDir}</value>
</property>
<!-- 指定执行的map类 -->
<property>
<name>mapreduce.job.map.class</name>
<value>org.apache.hadoop.examples.WordCount$TokenizerMapper</value>
</property>
<!-- 指定执行的reduce类 -->
<property>
<name>mapreduce.job.reduce.class</name>
<value>org.apache.hadoop.examples.WordCount$IntSumReducer</value>
</property>
<!-- 配置map task的个数 -->
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
</configuration>
</map-reduce>
<ok to="hive2-node"/>
<error to="fail"/>
</action>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/hive2"/>
<mkdir path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
<param>INPUT=/user/${wf:user()}/${examplesRoot}/input-data/table</param>
<param>OUTPUT=/user/${wf:user()}/${examplesRoot}/output-data/hive2</param>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>
job.properties配置文件
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
EXEC=hello.sh
outputDir=/oozie/output
inputdir=/oozie/input
jdbcURL=jdbc:hive2://node01:10000/default
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/sereval-actions/workflow.xml
5.4. 上传调度任务到hdfs
cd /export/servers/oozie4.1.0/oozie_works/
hdfs dfs -put sereval-actions/ /user/root/oozie_works/
5.5. 执行调度任务
cd /export/servers/oozie4.1.0/
bin/oozie job -oozie http://node01:11000/oozie -config oozie_works/sereval-actions/job.properties -run
6. Oozie定时调度
在oozie当中,主要是通过Coordinator 来实现任务的定时调度, Coordinator 模块主要通过xml来进行配置即可。
Coordinator 的调度主要可以有两种实现方式
第一种:基于时间的定时任务调度:
oozie基于时间的调度主要需要指定三个参数,第一个起始时间,第二个结束时间,第三个调度频率;
第二种:基于数据的任务调度, 这种是基于数据的调度,只要在有了数据才会触发调度任务。
6.1. 准备配置模板
第一步:拷贝定时任务的调度模板
cd /export/servers/oozie4.1.0/
cp -r examples/apps/cron oozie_works/cron-job
第二步:拷贝我们的hello.sh脚本
cd /export/servers/oozie4.1.0/oozie_works
cp shell/hello.sh cron-job/
6.2. 修改配置模板
修改job.properties
cd /export/servers/oozie4.1.0/oozie_works/cron-job
vim job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=oozie_works
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/coordinator.xml
#start:必须设置为未来时间,否则任务失败
start=2020-04-12T19:20+0800
end=2020-04-22T19:20+0800
EXEC=hello.sh
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/cron-job/workflow.xml
修改coordinator.xml
vim coordinator.xml
<!--
oozie的frequency 可以支持很多表达式,其中可以通过定时每分,或者每小时,或者每天,或者每月进行执行,也支持可以通过与linux的crontab表达式类似的写法来进行定时任务的执行
例如frequency 也可以写成以下方式
frequency="10 9 * * *" 每天上午的09:10:00开始执行任务
frequency="0 1 * * *" 每天凌晨的01:00开始执行任务
-->
<coordinator-app name="cron-job" frequency="${coord:minutes(1)}" start="${start}" end="${end}" timezone="GMT+0800"
xmlns="uri:oozie:coordinator:0.4">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>jobTracker</name>
<value>${jobTracker}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
修改workflow.xml
vim workflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.5" name="one-op-wf">
<start to="action1"/>
<action name="action1">
<shell xmlns="uri:oozie:shell-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<!-- <argument>my_output=Hello Oozie</argument> -->
<file>/user/root/oozie_works/cron-job/${EXEC}#${EXEC}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="end"/>
</action>
<end name="end"/>
</workflow-app>
6.3. 上传调度任务到hdfs
cd /export/servers/oozie4.1.0/oozie_works
hdfs dfs -put cron-job/ /user/root/oozie_works/
6.4. 执行调度
cd /export/servers/oozie4.1.0/
bin/oozie job -oozie http://node01:11000/oozie -config oozie_works/cron-job/job.properties –run
七、 Oozie任务查看、杀死
查看所有普通任务
oozie jobs
查看定时任务
oozie jobs -jobtype coordinator
杀死某个任务oozie可以通过jobid来杀死某个定时任务
oozie job -kill [id]
oozie job -kill 0000085-180628150519513-oozie-root-C














 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









