







5.1 API Design
Producer APIs
The Producer API that wraps the 2 low-level producers
Producer API封装了两个low-level的producers
- kafka.producer.SyncProducer and kafka.producer.async.AsyncProducer.
class Producer {
/* Sends the data, partitioned by key to the topic using either the */
/* synchronous or the asynchronous producer */
public void send(kafka.javaapi.producer.ProducerData<K,V> producerData);
/* Sends a list of data, partitioned by key to the topic using either */
/* the synchronous or the asynchronous producer */
public void send(java.util.List<kafka.javaapi.producer.ProducerData<K,V>> producerData);
/* Closes the producer and cleans up */
public void close();
}
The goal is to expose all the producer functionality through a single API to the client. The Kafka producer
目标是通过一个单独的API将所有producer功能暴露给客户端。kafka producer
- can handle queueing/buffering of multiple producer requests and asynchronous dispatch of the batched data:
kafka.producer.Producerprovides the ability to batch multiple produce requests (producer.type=async), before serializing and dispatching them to the appropriate kafka broker partition. The size of the batch can be controlled by a few config parameters. As events enter a queue, they are buffered in a queue, until eitherqueue.timeorbatch.sizeis reached. A background thread (kafka.producer.async.ProducerSendThread) dequeues the batch of data and lets thekafka.producer.EventHandlerserialize and send the data to the appropriate kafka broker partition. A custom event handler can be plugged in through theevent.handlerconfig parameter. At various stages of this producer queue pipeline, it is helpful to be able to inject callbacks, either for plugging in custom logging/tracing code or custom monitoring logic. This is possible by implementing thekafka.producer.async.CallbackHandlerinterface and settingcallback.handlerconfig parameter to that class.
可以处理多个producer请求的队列或者缓存,以及批量数据的异步调度。
kafka.producer.Producer 提供以下能力:在将多个produce请求序列化或者分发到合适的kafka broker partition之前,可以批量处理多个produce请求(producer.type=async)的能力。批量处理的尺寸可以由一些参数进行控制。当事件进入队列时,就缓存到队列中,直到queue.time或者batch.size达到为止。后台线程(kafka.producer.async.ProducerSendThread)会从队列中批量获取数据,并且使用kafka.producer.EventHandler将这些数据序列化并且发送到合适的的kafka broker partition。可以通过event.handler配置参数将用户事件句柄加入。在这种多级的producer队列管道中,注入回调函数或者加入用户日志、跟踪代码或者用户级别的监控逻辑来说,很有帮助。以上用户级代码注入可以通过实现kafka.producer.async.CallbackHandler接口以及设置callback.handler配置参数到这个接口类。
- handles the serialization of data through a user-specified
Encoder:通过用户特定的Encoder来处理数据的序列化:interface Encoder<T> { public Message toMessage(T data); }The default is the no-op
kafka.serializer.DefaultEncoder - provides software load balancing through an optionally user-specified
Partitioner:通过可选的用户特定的partitioner来提供软件负载均衡The routing decision is influenced by the
kafka.producer.Partitioner.interface Partitioner<T> { int partition(T key, int numPartitions); }The partition API uses the key and the number of available broker partitions to return a partition id. This id is used as an index into a sorted list of broker_ids and partitions to pick a broker partition for the producer request. The default partitioning strategy ishash(key)%numPartitions. If the key is null, then a random broker partition is picked. A custom partitioning strategy can also be plugged in using thepartitioner.classconfig parameter. partition API使用key和可用的broker partitions的数字进行数据分区发送。partition用作一个索引,作为从一组排序的broker_ids和partitions中挑选出一个broker partition处理producer 请求。默认partitioning策略是hash(key)%numPartitions。如果key是null,那么选择随机的broker partition。用户partitioning策略可以使用partitioner.class配置参数
Consumer APIs
We have 2 levels of consumer APIs. The low-level "simple" API maintains a connection to a single broker and has a close correspondence to the network requests sent to the server. This API is completely stateless, with the offset being passed in on every request, allowing the user to maintain this metadata however they choose.
The high-level API hides the details of brokers from the consumer and allows consuming off the cluster of machines without concern for the underlying topology. It also maintains the state of what has been consumed. The high-level API also provides the ability to subscribe to topics that match a filter expression (i.e., either a whitelist or a blacklist regular expression).
我们有两个级别的consumer APIs。低水位的简单API维护了与单个broker的链接,与发送到server的网络请求与密切的关系。这种API是完全无状态的,可以在每次请求中传递offset,允许用户维护元数据。
高水位的API对consumer隐藏了brokers的细节,允许从集群消费消息而不用关心潜在的策略。它同样维护了已经消费信息的状态。高水位的API痛痒提供了订阅某些符合过滤表达式的topics的能力(例如:白名单或者是黑名单的正则表达式)。
Low-level API
class SimpleConsumer {
/* Send fetch request to a broker and get back a set of messages. */
public ByteBufferMessageSet fetch(FetchRequest request);
/* Send a list of fetch requests to a broker and get back a response set. */
public MultiFetchResponse multifetch(List<FetchRequest> fetches);
/**
* Get a list of valid offsets (up to maxSize) before the given time.
* The result is a list of offsets, in descending order.
* @param time: time in millisecs,
* if set to OffsetRequest$.MODULE$.LATEST_TIME(), get from the latest offset available.
* if set to OffsetRequest$.MODULE$.EARLIEST_TIME(), get from the earliest offset available.
*/
public long[] getOffsetsBefore(String topic, int partition, long time, int maxNumOffsets);
}
The low-level API is used to implement the high-level API as well as being used directly for some of our offline consumers which have particular requirements around maintaining state.
低水位API用来实现高水位API,也可以直接用于某些对维护状态有特殊需求的离线consumers。
High-level API
/* create a connection to the cluster */
ConsumerConnector connector = Consumer.create(consumerConfig);
interface ConsumerConnector {
/**
* This method is used to get a list of KafkaStreams, which are iterators over
* MessageAndMetadata objects from which you can obtain messages and their
* associated metadata (currently only topic).
* Input: a map of <topic, #streams>
* Output: a map of <topic, list of message streams>
*/
public Map<String,List<KafkaStream>> createMessageStreams(Map<String,Int> topicCountMap);
/**
* You can also obtain a list of KafkaStreams, that iterate over messages
* from topics that match a TopicFilter. (A TopicFilter encapsulates a
* whitelist or a blacklist which is a standard Java regex.)
*/
public List<KafkaStream> createMessageStreamsByFilter(
TopicFilter topicFilter, int numStreams);
/* Commit the offsets of all messages consumed so far. */
public commitOffsets()
/* Shut down the connector */
public shutdown()
}
This API is centered around iterators, implemented by the KafkaStream class. Each KafkaStream represents the stream of messages from one or more partitions on one or more servers. Each stream is used for single threaded processing, so the client can provide the number of desired streams in the create call. Thus a stream may represent the merging of multiple server partitions (to correspond to the number of processing threads), but each partition only goes to one stream.
API围绕着迭代器,通过KafkaStream类实现的。每个KafkaStream表示了来自一个或者更多servers上的partitions的消息流。每个流用于单线程处理,因此客户端可以在创建调用中提供所需数据流的数量。这样一个流可以表示多个server partitions(以对应处理线程的数量)的集合,但是每个partition只能进入一个流。
The createMessageStreams call registers the consumer for the topic, which results in rebalancing the consumer/broker assignment. The API encourages creating many topic streams in a single call in order to minimize this rebalancing. The createMessageStreamsByFilter call (additionally) registers watchers to discover new topics that match its filter. Note that each stream that createMessageStreamsByFilter returns may iterate over messages from multiple topics (i.e., if multiple topics are allowed by the filter).
createMessageStreams调用注册topic的consumer的使用者,可以用于重新调整consumer/broker分配的负载均衡。API鼓励单个调用者中创建很多topic数据流,主要是为了减少重新负载均衡。createMessageStreamsByFilter调用(可选的)注册观察者以用来发现匹配过滤规则的新topics。注意:createMessageStreamByFilter返回的每个流都可能包含来自不同topics的消息(如果过滤规则中包含多个topics)。
5.2 Network Layer
The network layer is a fairly straight-forward NIO server, and will not be described in great detail. The sendfile implementation is done by giving the MessageSet interface a writeTo method. This allows the file-backed message set to use the more efficient transferTo implementation instead of an in-process buffered write. The threading model is a single acceptor thread and N processor threads which handle a fixed number of connections each. This design has been pretty thoroughly tested elsewhere and found to be simple to implement and fast. The protocol is kept quite simple to allow for future implementation of clients in other languages.
网络层是相当直接的NIO server,此处不会详细描述。sendfile实现是通过MessageSet接口的writeTo方法实现的。这允许了文件备份的消息集合来使用更有效的transferTo实现,以替代进程内缓存的写数据。线程模型是单独的接收者线程以及N个处理者线程,每个处理线程用来处理确定数目的链接。这种设计已经在其他地方进行了彻底测试,发现实现简单快速。协议保持很简单,以允许将来实现其他语言的客户端。
5.3 Messages
Messages consist of a fixed-size header, a variable length opaque key byte array and a variable length opaque value byte array. The header contains the following fields:
消息包含固定长度的信息头部,可变长度不透明key字节组和可变长度不透明value字节组。头部包含以下字段:
- A CRC32 checksum to detect corruption or truncation. CRC32的校验码用于检测错误
- A format version. 格式版本
- An attributes identifier 特征标识符
- A timestamp 时间戳
Leaving the key and value opaque is the right decision: there is a great deal of progress being made on serialization libraries right now, and any particular choice is unlikely to be right for all uses. Needless to say a particular application using Kafka would likely mandate a particular serialization type as part of its usage. The MessageSet interface is simply an iterator over messages with specialized methods for bulk reading and writing to an NIO Channel.
保留key和value不透明是正确的选择:目前序列化库上有很大的进步,任何特定的选择都不可能适用于所有场景。不用说,适用Kafka的特定应用程序可能将实现特定的序列化作为应用的一部分。MessageSet接口只是一个迭代器,它具有批量读写NIO通道的专门方法的消息。
5.4 Message Format
/**
* 1. 4 byte CRC32 of the message
* 2. 1 byte "magic" identifier to allow format changes, value is 0 or 1
* 3. 1 byte "attributes" identifier to allow annotations on the message independent of the version
* bit 0 ~ 2 : Compression codec.
* 0 : no compression
* 1 : gzip
* 2 : snappy
* 3 : lz4
* bit 3 : Timestamp type
* 0 : create time
* 1 : log append time
* bit 4 ~ 7 : reserved
* 4. (Optional) 8 byte timestamp only if "magic" identifier is greater than 0
* 5. 4 byte key length, containing length K
* 6. K byte key
* 7. 4 byte payload length, containing length V
* 8. V byte payload
*/
5.5 Log
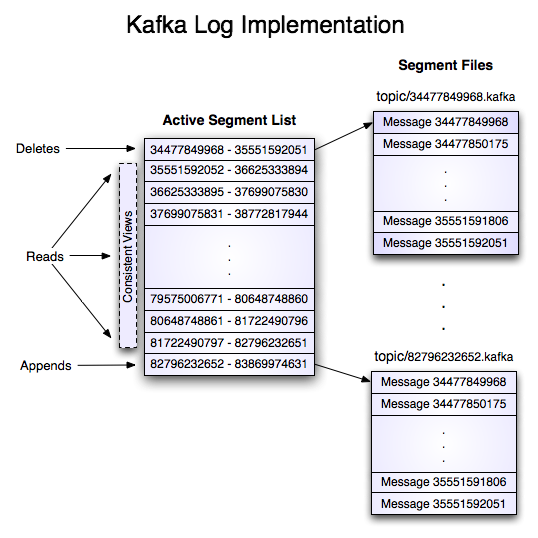
A log for a topic named "my_topic" with two partitions consists of two directories (namely my_topic_0 and my_topic_1) populated with data files containing the messages for that topic. The format of the log files is a sequence of "log entries""; each log entry is a 4 byte integer N storing the message length which is followed by the N message bytes. Each message is uniquely identified by a 64-bit integer offset giving the byte position of the start of this message in the stream of all messages ever sent to that topic on that partition. The on-disk format of each message is given below. Each log file is named with the offset of the first message it contains. So the first file created will be 00000000000.kafka, and each additional file will have an integer name roughly Sbytes from the previous file where S is the max log file size given in the configuration.
名为“my_topic”的topic,包含两个partition时,那么会有两个目录存储日志,即my_topic_0和my_topic_1。日志文件的格式是一系列日志项目;每个日志项目都是4字节整型N,存储着消息长度。每条消息都是使用64bit的offset进行唯一标识,代表在本partition中所有消息中从头开始到此消息位置。每条消息在磁盘上的格式在下面给出。每个日志文件以所存储的第一条消息的offset命名。这样,第一个文件的名字就是00000000000.kafka,想第一个文件一样,每个其他的文件都会有一个类似整型名字,并且大概S字节,其中S时最大日志尺寸,可以在配置中配置。
The exact binary format for messages is versioned and maintained as a standard interface so message sets can be transferred between producer, broker, and client without recopying or conversion when desirable. This format is as follows:
On-disk format of a message
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes
The use of the message offset as the message id is unusual. Our original idea was to use a GUID generated by the producer, and maintain a mapping from GUID to offset on each broker. But since a consumer must maintain an ID for each server, the global uniqueness of the GUID provides no value. Furthermore, the complexity of maintaining the mapping from a random id to an offset requires a heavy weight index structure which must be synchronized with disk, essentially requiring a full persistent random-access data structure. Thus to simplify the lookup structure we decided to use a simple per-partition atomic counter which could be coupled with the partition id and node id to uniquely identify a message; this makes the lookup structure simpler, though multiple seeks per consumer request are still likely. However once we settled on a counter, the jump to directly using the offset seemed natural—both after all are monotonically increasing integers unique to a partition. Since the offset is hidden from the consumer API this decision is ultimately an implementation detail and we went with the more efficient approach.
消息offset用作消息id是非同寻常的。我们最初的想法是使用生产者产生的GUID作为消息id,然后每个broker维护一份GUID到offset之间的映射表。但是因为每一个consumer必须维护这样一份映射表,这样全局唯一的GUID不能提供任何价值。而且,维护随机id到offset之间映射的复杂度要求很重的索引结构,同时必须同步到磁盘,也需要完全持久化的随机访问的数据结构。这样一来,为了简化查询结构,我们决定使用简单的、每个partition独有的原子计数器,同时使用partition id以及节点id就可以唯一的标识一条消息。这样就使得查询变得非常简单,因此每个consumer请求需要的多个查询就成为可能。因此,一旦我们设置计数器,使用offset进行跳转就似乎变得很自然-毕竟对每个partition只需要单调的增加offset就可以了。因为在consumer API中隐藏了offset,因此offset最终成为一个实现细节,我们也就可以获得更有效的使用。
Writes
The log allows serial appends which always go to the last file. This file is rolled over to a fresh file when it reaches a configurable size (say 1GB). The log takes two configuration parameters: M, which gives the number of messages to write before forcing the OS to flush the file to disk, and S, which gives a number of seconds after which a flush is forced. This gives a durability guarantee of losing at most M messages or S seconds of data in the event of a system crash.
日志允许在最后的文件进行顺序追加。文件可以周期性的滚动到新文件:当文件大小到达配置大小(比如说1GB)。日志持久化到硬盘由两个参数控制:M,强制OS将数据刷到硬盘前的消息条数;S,OS刷数据到硬盘的时间间隔。如果系统崩溃的话,可能会丢失最多M条消息或者S秒内的数据。
Reads
Reads are done by giving the 64-bit logical offset of a message and an S-byte max chunk size. This will return an iterator over the messages contained in the S-byte buffer. S is intended to be larger than any single message, but in the event of an abnormally large message, the read can be retried multiple times, each time doubling the buffer size, until the message is read successfully. A maximum message and buffer size can be specified to make the server reject messages larger than some size, and to give a bound to the client on the maximum it needs to ever read to get a complete message. It is likely that the read buffer ends with a partial message, this is easily detected by the size delimiting.
读数据行为可以通过给定64比特的offset值以及S字节的最大消息块尺寸。这将返回包含S字节的消息集合的迭代器。S一般要比任何单个消息要大,但是如果遇到异常大的消息,读行为可以重试多次,每次都会让缓存尺寸*2,直到消息可以成功读取。最大尺寸的消息以及缓存大小可以使得server拒绝某些过大的消息同时有可以给客户端一个有效的最大值,以方便客户端可以读取完整的消息。似乎读缓存会以一个不完整的消息结束,但是这很容易通过尺寸界定来判断是否完整(消息头部有消息大小等信息)。
The actual process of reading from an offset requires first locating the log segment file in which the data is stored, calculating the file-specific offset from the global offset value, and then reading from that file offset. The search is done as a simple binary search variation against an in-memory range maintained for each file.
从offset请求读取消息的实际过程是:首先定位日志中消息的存储位置,通过全局的offset来确定这个offset属于那一个特定的文件,然后从这个文件读取。搜索过程是简单的二分查找。
The log provides the capability of getting the most recently written message to allow clients to start subscribing as of "right now". This is also useful in the case the consumer fails to consume its data within its SLA-specified number of days. In this case when the client attempts to consume a non-existent offset it is given an OutOfRangeException and can either reset itself or fail as appropriate to the use case.
The following is the format of the results sent to the consumer.
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
Deletes
Data is deleted one log segment at a time. The log manager allows pluggable delete policies to choose which files are eligible for deletion. The current policy deletes any log with a modification time of more than N days ago, though a policy which retained the last N GB could also be useful. To avoid locking reads while still allowing deletes that modify the segment list we use a copy-on-write style segment list implementation that provides consistent views to allow a binary search to proceed on an immutable static snapshot view of the log segments while deletes are progressing.
每次删除一个日志文件。日志管理允许增加其他的删除策略已选择哪个文件优先删除。当前的策略是基于过期时间删除的,任何日志都有一个可以调节的保存时间,还可以保留最新的N GB数据。为了避免锁定读取,我们使用copy-on-write方式对日志块进行删除,它提供不变的视图,这样就允许二分查找并进行删除。
Guarantees
The log provides a configuration parameter M which controls the maximum number of messages that are written before forcing a flush to disk. On startup a log recovery process is run that iterates over all messages in the newest log segment and verifies that each message entry is valid. A message entry is valid if the sum of its size and offset are less than the length of the file AND the CRC32 of the message payload matches the CRC stored with the message. In the event corruption is detected the log is truncated to the last valid offset.
Note that two kinds of corruption must be handled: truncation in which an unwritten block is lost due to a crash, and corruption in which a nonsense block is ADDED to the file. The reason for this is that in general the OS makes no guarantee of the write order between the file inode and the actual block data so in addition to losing written data the file can gain nonsense data if the inode is updated with a new size but a crash occurs before the block containing that data is written. The CRC detects this corner case, and prevents it from corrupting the log (though the unwritten messages are, of course, lost).
5.6 Distribution
Consumer Offset Tracking
The high-level consumer tracks the maximum offset it has consumed in each partition and periodically commits its offset vector so that it can resume from those offsets in the event of a restart. Kafka provides the option to store all the offsets for a given consumer group in a designated broker (for that group) called the offset manager. i.e., any consumer instance in that consumer group should send its offset commits and fetches to that offset manager (broker). The high-level consumer handles this automatically. If you use the simple consumer you will need to manage offsets manually. This is currently unsupported in the Java simple consumer which can only commit or fetch offsets in ZooKeeper. If you use the Scala simple consumer you can discover the offset manager and explicitly commit or fetch offsets to the offset manager. A consumer can look up its offset manager by issuing a GroupCoordinatorRequest to any Kafka broker and reading the GroupCoordinatorResponse which will contain the offset manager. The consumer can then proceed to commit or fetch offsets from the offsets manager broker. In case the offset manager moves, the consumer will need to rediscover the offset manager. If you wish to manage your offsets manually, you can take a look at these code samples that explain how to issue OffsetCommitRequest and OffsetFetchRequest.
高水位consumer追踪它所消耗的partition的最大offset,并且周期性的提交它们的offset,因此当重启时可以从这些提交的offset开始消费消息。Kafka提供选项:为给定的consumer group存储所有offsets的offset管理器。例如,任何consumer组中consumer实例应该发送它自己的offset提交以及抓取(消耗)到offset管理器。高水位的consumer可以自动处理这些事情。如果你使用简单的consumer,你需要手动管理这些offsets。这在当前java的简单consumer中是不支持的,它只能通过zookeeper提交或者抓取offsets。如果你使用Scala简单版本的consumer,你会发现offset管理器以及显式的提交或者抓取offsets到offset管理器。consumer查询它的offset管理器通过提交GroupCoordnatorRequest到任何一个kafka broker,并且读取GroupCoordinatorResponse,回馈里有offset管理器。consumer接着可以继续从offset管理器提交或者抓取offset。当offset管理器变动时,consumer将需要重新查找offset管理器。如果你想自己管理offset,你可以查看一下例程是如何使用OffsetCommitRequest以及OffsetFetchRequest。
When the offset manager receives an OffsetCommitRequest, it appends the request to a special compacted Kafka topic named __consumer_offsets. The offset manager sends a successful offset commit response to the consumer only after all the replicas of the offsets topic receive the offsets. In case the offsets fail to replicate within a configurable timeout, the offset commit will fail and the consumer may retry the commit after backing off. (This is done automatically by the high-level consumer.) The brokers periodically compact the offsets topic since it only needs to maintain the most recent offset commit per partition. The offset manager also caches the offsets in an in-memory table in order to serve offset fetches quickly.
当offset管理器收到OffsetCommitRequest时,他会把请求追加到特定的压缩的Kafka topic: __consumer_offsets。offset管理器在所有offset topic备份都收到这个offsets之后才会发送成功的offset提交回馈。如果在超时时间之内没有备份成功,则offset提交就是失败了,consumer需要等待之后的重试。(高水位的consumer可以自动实现)。broker周期性的压缩offsets topic,因为它只需要保存每个partition最近提交的offset即可。offset管理器也需要在内存中缓存offsets,以满足快速的抓取offset。
When the offset manager receives an offset fetch request, it simply returns the last committed offset vector from the offsets cache. In case the offset manager was just started or if it just became the offset manager for a new set of consumer groups (by becoming a leader for a partition of the offsets topic), it may need to load the offsets topic partition into the cache. In this case, the offset fetch will fail with an OffsetsLoadInProgress exception and the consumer may retry the OffsetFetchRequest after backing off. (This is done automatically by the high-level consumer.)
当offset管理器接收到offset抓取请求时,它可以简单的返回缓存的最新提交的offset。当offset管理器启动时或者如果broker变为新consumer groups的offset管理器时(通过变成某个offset topic partition的leader),它可能需要加载topic partition的offset到缓存中,这种情况下,offset 抓取可能会失败,因为OffsetLoadInProgress异常出现,consumer则需要重试OffsetFetchRequest(这也可以由高水位的consumer自动完成)。
Migrating offsets from ZooKeeper to Kafka
Kafka consumers in earlier releases store their offsets by default in ZooKeeper. It is possible to migrate these consumers to commit offsets into Kafka by following these steps:
- Set
offsets.storage=kafkaanddual.commit.enabled=truein your consumer config. - Do a rolling bounce of your consumers and then verify that your consumers are healthy.
- Set
dual.commit.enabled=falsein your consumer config. - Do a rolling bounce of your consumers and then verify that your consumers are healthy.
A roll-back (i.e., migrating from Kafka back to ZooKeeper) can also be performed using the above steps if you set offsets.storage=zookeeper.
Kafka消费者在以前的版本中是采用Zookeeper管理它们的offsets。可以将这些consumers通过以下步骤迁移到Kafka来管理offsets:
ZooKeeper Directories
The following gives the ZooKeeper structures and algorithms used for co-ordination between consumers and brokers.
下面给出Zookeeper结构以及在消费者和brokers之间进行协作的算法。
Notation
When an element in a path is denoted [xyz], that means that the value of xyz is not fixed and there is in fact a ZooKeeper znode for each possible value of xyz. For example /topics/[topic] would be a directory named /topics containing a sub-directory for each topic name. Numerical ranges are also given such as [0...5] to indicate the subdirectories 0, 1, 2, 3, 4. An arrow -> is used to indicate the contents of a znode. For example /hello -> world would indicate a znode /hello containing the value "world".
Broker Node Registry
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)
This is a list of all present broker nodes, each of which provides a unique logical broker id which identifies it to consumers (which must be given as part of its configuration). On startup, a broker node registers itself by creating a znode with the logical broker id under /brokers/ids. The purpose of the logical broker id is to allow a broker to be moved to a different physical machine without affecting consumers. An attempt to register a broker id that is already in use (say because two servers are configured with the same broker id) results in an error.
Since the broker registers itself in ZooKeeper using ephemeral znodes, this registration is dynamic and will disappear if the broker is shutdown or dies (thus notifying consumers it is no longer available).
这是一个所有活跃broker节点列表。每个节点都有一个唯一的broker id,用来标识自己(配置文件中有)。启动时,broker节点自己注册,通过创建名为/brokers/ids/id的znode。逻辑的broker id目的在于允许broker可以迁移到不同物理机上而不会影响consumers。尝试注册一个已经在使用的broker id会导致错误(即因为两个server有相同的broker id)
因为broker在Zookeeper中使用临时节点的模式注册自己,这种注册时动态的,如果broker宕机的话,节点就会消失。
Broker Topic Registry
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)
Each broker registers itself under the topics it maintains and stores the number of partitions for that topic.
每个broker在topics下面注册自己,它维护和存储topic的partition数目
Consumers and Consumer Groups
Consumers of topics also register themselves in ZooKeeper, in order to coordinate with each other and balance the consumption of data. Consumers can also store their offsets in ZooKeeper by setting offsets.storage=zookeeper. However, this offset storage mechanism will be deprecated in a future release. Therefore, it is recommended to migrate offsets storage to Kafka.
topics的消费者也在Zookeeper中注册了信息,为了彼此之间协作,并且均衡数据消费。consumer可以通过设置offsets.storage=zookeeper来在zookeeper中存储offsets。然而,这种offset存储机制会在未来的发布版中抛弃。因此,考虑迁移offsets存储到Kafka吧。
Multiple consumers can form a group and jointly consume a single topic. Each consumer in the same group is given a shared group_id. For example if one consumer is your foobar process, which is run across three machines, then you might assign this group of consumers the id "foobar". This group id is provided in the configuration of the consumer, and is your way to tell the consumer which group it belongs to.
The consumers in a group divide up the partitions as fairly as possible, each partition is consumed by exactly one consumer in a consumer group.
多个consumers可以组成一个组,共同消费某个topic。每个consumer都共享同一个groupid。例如,如果一个consumer是foobar进程,需要在三台机子上运行,那么需要分配名为foobar的消费组。这个groupid可以在consumer的配置中设定,用来设定consumer属于哪一个consumer group。
消费组里的consumer会尽可能公平的分配partitions,每个partition只能由一个consumer消费。
Consumer Id Registry
In addition to the group_id which is shared by all consumers in a group, each consumer is given a transient, unique consumer_id (of the form hostname:uuid) for identification purposes. Consumer ids are registered in the following directory.
所有consumer组里的consumer共享同一个groupid,每个消费者都会有一个唯一的consumer_id(格式:hostname:uuid)用来标识。consumer ids使用下面的方式注册:
/consumers/[group_id]/ids/[consumer_id] --> {"version":...,"subscription":{...:...},"pattern":...,"timestamp":...} (ephemeral node)
Each of the consumers in the group registers under its group and creates a znode with its consumer_id. The value of the znode contains a map of <topic, #streams>. This id is simply used to identify each of the consumers which is currently active within a group. This is an ephemeral node so it will disappear if the consumer process dies.
消费组中的每个消费者都会在它的组下创建consumer_id标识的znode。znode的值包括<topic, #streams>的映射。这个id简单的用来确认每个活跃的consumers。这也是临时节点,当consumer进程死掉的时候会消失。
Consumer Offsets
Consumers track the maximum offset they have consumed in each partition. This value is stored in a ZooKeeper directory if offsets.storage=zookeeper.
consumer追踪所消费的每个partition的最大offset。如果选择offset.storage=zookeeper的话,这个值存储在Zookeeper目录中。
/consumers/[group_id]/offsets/[topic]/[partition_id] --> offset_counter_value (persistent node)
Partition Owner registry
Each broker partition is consumed by a single consumer within a given consumer group. The consumer must establish its ownership of a given partition before any consumption can begin. To establish its ownership, a consumer writes its own id in an ephemeral node under the particular broker partition it is claiming.
每个broker partition只能被每个consumer 组中单独的consumer消费。consumer必须建立自己对partition的所有权,以防止其他consumer抢占。为了建立这种所有权,consumer在临时节点写入自己的id,格式如下:
/consumers/[group_id]/owners/[topic]/[partition_id] --> consumer_node_id (ephemeral node)
Cluster Id
The cluster id is a unique and immutable identifier assigned to a Kafka cluster. The cluster id can have a maximum of 22 characters and the allowed characters are defined by the regular expression [a-zA-Z0-9_\-]+, which corresponds to the characters used by the URL-safe Base64 variant with no padding. Conceptually, it is auto-generated when a cluster is started for the first time.
Implementation-wise, it is generated when a broker with version 0.10.1 or later is successfully started for the first time. The broker tries to get the cluster id from the /cluster/id znode during startup. If the znode does not exist, the broker generates a new cluster id and creates the znode with this cluster id.
集群id是唯一的并且是不可变的标识符。集群id可以最多有22个字符表示,允许使用正则表达式定义[a-zA-Z0-9_\-]+,这个和URL-safe Base64用的字符相关。一般来说,它在集群首次启动时自动生成。
在0.10.1或者更新的版本中出现的集群id。broker在启动时尝试从/cluster/id节点上获取cluster id,如果znode不存在,broker产生一个新的cluster id。
Broker node registration
The broker nodes are basically independent, so they only publish information about what they have. When a broker joins, it registers itself under the broker node registry directory and writes information about its host name and port. The broker also register the list of existing topics and their logical partitions in the broker topic registry. New topics are registered dynamically when they are created on the broker.
broker 节点基本上是独立的,因此他们只能发布他们自己的信息。当一个broker加入时,它在broker 节点注册目录下注册自己的信息,然后写入hostname和port。broker也需要注册存在topics和它们的逻辑上的partitions。新topic当创建时可以动态的注册。
Consumer registration algorithm
When a consumer starts, it does the following:
- Register itself in the consumer id registry under its group.
- Register a watch on changes (new consumers joining or any existing consumers leaving) under the consumer id registry. (Each change triggers rebalancing among all consumers within the group to which the changed consumer belongs.)
- Register a watch on changes (new brokers joining or any existing brokers leaving) under the broker id registry. (Each change triggers rebalancing among all consumers in all consumer groups.)
- If the consumer creates a message stream using a topic filter, it also registers a watch on changes (new topics being added) under the broker topic registry. (Each change will trigger re-evaluation of the available topics to determine which topics are allowed by the topic filter. A new allowed topic will trigger rebalancing among all consumers within the consumer group.)
- Force itself to rebalance within in its consumer group.
当consumer启动时,会像下面一样:
Consumer rebalancing algorithm
The consumer rebalancing algorithms allows all the consumers in a group to come into consensus on which consumer is consuming which partitions. Consumer rebalancing is triggered on each addition or removal of both broker nodes and other consumers within the same group. For a given topic and a given consumer group, broker partitions are divided evenly among consumers within the group. A partition is always consumed by a single consumer. This design simplifies the implementation. Had we allowed a partition to be concurrently consumed by multiple consumers, there would be contention on the partition and some kind of locking would be required. If there are more consumers than partitions, some consumers won't get any data at all. During rebalancing, we try to assign partitions to consumers in such a way that reduces the number of broker nodes each consumer has to connect to.
consumer重新负载均衡算法需要所有同组consumer对哪些consumers正在消费哪些partitions达成共识。每次增加或者删除broker节点或者其他consumer都会引发consumer重新负载均衡。对于一个给定的topic和给定的consumer组,broker partitions在consumers组里进行分配。一个partition只能由一个consumer消费。这种设计简化了实现。如果我们允许多个consumers可以同时消费同一个partition,那将会需要在partition的一致性以及某种加锁。如果consumers个数大于partitions个数,一些consumers会完全得不到数据。在重新负载过程中,我们尝试以减少每个消费者连接到的代理节点数量的方式为消费者分配分区。
Each consumer does the following during rebalancing:
1. For each topic T that Ci subscribes to
2. let PT be all partitions producing topic T
3. let CG be all consumers in the same group as Ci that consume topic T
4. sort PT (so partitions on the same broker are clustered together)
5. sort CG
6. let i be the index position of Ci in CG and let N = size(PT)/size(CG)
7. assign partitions from i*N to (i+1)*N - 1 to consumer Ci
8. remove current entries owned by Ci from the partition owner registry
9. add newly assigned partitions to the partition owner registry
(we may need to re-try this until the original partition owner releases its ownership)
When rebalancing is triggered at one consumer, rebalancing should be triggered in other consumers within the same group about the same time.
每个consumer在重新负载均衡过程中都会做以下事情:















 340
340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









