









一、序
<c专家编程>应该是每位程序员的第二本学习的C语言的书;
但是确实我第五本;
1、几个问题:

这五个问题,我只明白三个,有一个是模糊,一个是不懂,希望看完本书我能都明白;
2、为了避免在需要进行比较时误用赋值符号,最好在比较式中先写常数,如:
if(3 == i)
这样,如果不小心误用了赋值符号,编译器就会发出“attempted assighnment to literal”的错误信息;
3、time_t是long型的typedef形式;
ctime()函数把参数转换为当地时间;
gmtime()函数取得最大的UTC时间值,但是则个函数并不返回一个可打印的字符串,所以要采用asctime()函数获取这样一个字符串;
二、穿越时空的迷雾
1、编译器设计者的金科玉律:效率就是一切;
编译器效率包括两方面:
运行效率:代码的运行速度
编译效率:产生可执行代码的速度
2、C语言的许多特性是为了方便编译器设计者而建立的:
(1)类型系统:保护程序员,防止他们在数据上进行无效的操作;
(2)数组下标从0而不是1开始:因为偏移量
(3)C语言的基本数据类型直接与底层硬件相对应
(4)auto关键字显然是摆设:这个关键字只对创建符号表入口的编译器设计者有意义:进入程序块时自动进行内存分配;
(5)表达式中数组名可以看做指针
(6)float被自动扩展成double
(7)不允许嵌套函数:函数内部包含另一个函数的定义
(8)register关键字:简化了编译器,却把包袱丢给了程序员;
3、标准I/O库和C预处理
(1)C语言中,绝大多数库函数或辅助程序都需要显式调用
(2)C预处理器:
字符串替换
头文件包含:一般性的声明可以被分离到头文件中,并且可以被许多源文件使用
通用代码模板的扩展:宏
4、Steve Bourne在编写UNIX第七版SHELL时,建立了很多预处理定义:


注:宏最好只用于命名常量,并为一些适当的结构提供简捷的记法,宏名应该大写,这样便很容易与函数调用区分开来;
每一个ANSI C编译器能够支持:
在函数定义中形参数量的上限至少可以达到31个;
函数调用中实参数量的上限至少可以达到31个;
一条源代码行里至少可以有509个字符;
在表达式中至少可以支持32层嵌套的括号;
long int 的最大值不得少于2 147 483 647

以下为解释:
(1)实参和形参不相容,这要看参数传递的约束条件:
每个实参都应该具有自己的类型,这样它的值就可以赋值给与它所对应的形参类型的对象(该对象的类型不能含有限定符);
这就说,参数传递过程类似于赋值;
(2)因此,接下来看赋值的约束条件:
两个操作数都是指向有限定符或无限定符的相容类型的指针,左边指针所指向的类型必须具有右边指针所指向类型的全部限定符;
这就是说,左边指针可以具有右边指针没有的限定符,同时包含右边指针所有的限定符;
这个条件使得函数调用中实参char*能够与形参const char*匹配;
合法的原因就是:
char* cp;
const char *ccp;
ccp = cp;
左操作数是一个指向有const限定符的char的指针;
右操作数是一个指向没有限定符的char的指针;
char类型与char类型是相容的,左操作数所指向的类型具有右操作数所指向类型的限定符(无),再加上自身的限定符;
反过来,就是错误的,因为cp = ccp时,左边操作数cp不包含右边操作数ccp所具有const限定符,所以是错误的;
(3)类似的,const char**也是一个没有限定符的指针类型,它的类型是指向有const限定符的char类型的指针的指针;由于char**和const char**都是没有限定符的指针类型,但它们所指向的类型不一样,前者指向char*,后者指向const char*,因此它们是不相容的。因此类型为char**的实参与类型为const char**形参是不相容的;
这是《C编程专家-英文版》上的原话:

这是《C编程专家-中文版》上对应的话:

我认为这句话翻译错了,应该是:
除非一个const char**类型的对象可以被一个char**类型的对象所赋值,否则......
注:const并不能把变量变成常量,在一个符号前加上const限定符只是表示这个符号不能被赋值;也就是说它的值对于这个符号来说是只读的,但它并不能防止通过程序的内部(甚至是外部)的方法来修改这个值;
const最有用之处就是用它来限定函数的形参,这样该函数就不会修改实参指针所指的数据,但是如果其他函数形参不带const限定符的话,还是有可能修改实参指针指向的数据;
举例:
int a = 3,b = 4;
const int *p = &a;
printf("*p is %d \n",*p);//此时*p = 3
p = &b;
printf("now *p is %d \n",*p);//此时*p = 4
也就是说,尽管使用const将*p限定,此时*p =3,我们不可以直接修改*p,但是我们却可以修改p,这样p就指向了不同的地址,对p进行解引用得到*p时,发现此时*p =4,即这样就间接的修改了*p;
5、类型转换:
ANSI C:
(1)字符和整形
char、short int或者int型位段,包括它们的有符号或无符号变型、以及枚举类型,可以使用在int或者unsigned int的表达式中,如果int可以完整表示源类型的所有值,那么该类型就转换为int,否则转换为unsigned int,这成为整形升级;
(2)寻常算术转换
char、short int、int(bit-field)----》int------》unsigned int-----》long int-----》unsigned long int------》float-----double----》long double
当执行算术运算时,操作数的类型如果不同,就会发生转化,转换的方向一般是朝着浮点精度更高、长度更长,整形数如果转换为signed不会丢失信息,就会转换为signed,否则转换为unsigned;
sizeof()的返回类型是无符号数;

这段程序中if表达式为假,因为TOTAL_ELEMENTS所定义的值时unsigned int 类型,因为sizeof()的返回类型是无符号数,if语句在signed int和
unsigned int 之间测试相等性,所以d被升级为unsigned int类型,-1转换成unsigned int 的结果将是一个非常巨大的正整数,致使表达式的值为假。
要修正这个问题,只要对TOTAL_ELEMENTS强制类型转换即可:
if( d <= (int)TOTAL_ELEMENTS -2)
对无符号类型的建议:
尽量不要再你的代码中使用无符号类型;
尽量使用int那样的有符号类型,这样在涉及到混合类型的复杂细节时,不必担心边界情况,如-1被翻译成非常大的整数;
只有在使用位段和二进制掩码时,才可以用无符号数;应该在表达式中使用强制类型转换,使操作数均为有符号数或者无符号数,这样就不必由编译器来选择结果的类型;
#define TOTAL_ELEMENTS (sizeof(array)/sizeof(array[0]))
而不是
#define TOTAL_ELEMENTS (sizeof(array)/sizeof(int))
因为前者可以在不修改#define语句的情况下改变数组的基本类型(比如,把int变成char)
#pragma用于向编译器提示一些信息,诸如希望把某个特定的函数扩展为内联函数,或者是忽略边界检查;
*****************************************************************************************************************************************************************************************
2013年3月27日更新
*****************************************************************************************************************************************************************************************
第二章、这不是BUG,而是语言特性
1、strlen()函数计算字符串的长度,遇到'\0'截止,但是不包括'\0',返回值是unsigned int型所以为字符串分配存储空间时,要将最后的字符串结束符考虑在内;
malloc(strlen(str))一般是错误的,这个就没有考虑字符串末尾的'\0';
而是:
malloc(strlen(str)+1);
2、NUL和NULL区别
(1)NUL用于表示结束一个ASCII字符串
(2)NULL用于表示什么也不指向,即空指针;
ASCII字符串中0的位模式被称为NUL,表示哪里也不指向的特殊的指针则是NULL,指针声明时一般指向NULL,防止野指针出现;
这两个术语不可互换;
3、switch语句:

default可以出现在case列表的任何位置,它在其他的case均无法匹配时被选中执行,如果没有default,而且所有的case均不匹配,那条整条switch语句便什么也不做;
在C语言中,几乎从来不进行运行时错误检查-----对进行解除引用操作的指针进行有效性检查大概是唯一的例外;
一个遵循标准的C编译器至少允许一条switch语句中有257个case标签,这是为了允许switch满足一个8bit字符的所有情况,256个可能的值加上EOF;
也许switch语句最大的缺点是它不会在每个case标签后面的语句执行完毕后自动终止;一旦执行某个case语句,程序将会依次执行后面所有的case,除非遇到break语句,例如:

所以,最好在每条case语句后面加上break;
例如:
switch(a){
case 1: printf(" case 2\n");
break;
case 2: printf(" case 3\n");
break;
case 3: printf(" case 4\n");
break;
case 4: printf(" case 5\n");
break;
case 5: printf(" case 6\n");
break;
case 6: printf(" case 7\n");
break;
default: printf("default \n");
break;
}
switch中-----break中断了什么:

break语句实际上跳出的是最近的那层循环语句或switch语句,在这里,break跳出了switch语句,所以,这种情况下,switch中要慎用break语句,我能记住吗?
4、无效指针
在所有虚拟内存体系结构里,一旦一个指针进行解除引用操作时所引用的内存地址超出了虚拟内存的地址空间,操作系统就会终止这个进程。
5、lint:
lint是最著名的C语言工具之一,一般由UNIX系统提供,与大多数C语言编译器相比,lint可以对程序进行更加广泛的错误分析:
lint检查C程序中潜在的错误,包括可疑的类型组合、未使用的变量、不可达的代码以及不可移植的代码;lint会产生一系列程序员有必要从头到尾仔细阅读的诊断信息;使用lint的好处,可以检查出被编译器漏掉的错误;
6、字符串连接方式容易出现的错误:
(1) 过去书写多行信息时可以在行末添加 \ 的做法,后续的字符串出现在每行的开头;
printf("It is time to \
go to school \
,or I'll be late.\n");
上边的即:printf("It is time to go to school, or I'll be late \n");
(2)现在由于一连串相邻的字符串可以合并为同一个字符串;除了最后一个字符串之外,其余每个字符串末尾的'\0'都会被自动删除;
然而,这种自动合并意味着字符串数组在初始化时,如果不小心漏掉了一个逗号,编译时将不会发出错误信息,而悄无声息的将两个字符串连接在一起;
char *arr[] = {
"how are you",
"and you"
"ok"
}
在and you和ok之间没有逗号,所以按照字符串连接的性质,实际上arr[1] = "and youok"
看一下下面的小程序:
char *arr[] = {
"how are you",
"and you"
"ok"
};
printf("%s\n",arr[1]);
char **p;
p = arr;
printf("%s,%s\n",*p,*(p+1));
char a[][4] = {"nih","aoa","niz"};
char ( * q)[4];
q = a;
//p = a;
printf("%s,%s,%s\n",*q,*(q+1),*(q + 2));
其中:q的数据类型是char[4]*,是数组指针,即行指针,从右向左读即,指向包含4个char型数据的数组的指针,4就是q的步长,即q+1时要跨过4个char型数据;
arr的数据类型是char*[2],是指针数组,包含指向char型数据的指针的数组;
a的数据类型是char[3][4],是二维数组,包含3行4列的数组,即数组的数组,即包含3个“变量”的数组,每一个“变量”都是包含4个char型数据的数组;
p的数据类型是char**,是二级指针,指向“指向char型的指针”的指针;
其中p = a是错误的,因为p和a的数据类型不同,不相容;
7、定义C函数时,在缺省情况下函数的名字是全局可见的,可以再函数名前加extern关键字,也可以不加,效果是一样的;这个函数对于链接到他所在的目标文件的任何东西都是可见的,如果想限制对这个函数的访问,就必须加个static关键字;
当然,如果你想调用这些全局可见的函数,需要在调用前对所调用的函数进行声明;
根据实际经验,这种缺省的全局可见型多次被证明是个错误,这已是盖棺定论;
软件对象在大多数情况下应该对缺省的采用有限可见性;
当程序员需要让它全局可见时,应该采用显式的手段;
在C语言中,一个符号要么全局可见,要么对其他文件都不可见;
8、C语言中的符号重载
static:在函数内部,表示该变量是静态变量,具有内部链接,每次调用变量的值都是上一次用完该变量之后的值;
对于函数来说,表示该函数是静态函数,只对本文件可见
extern:用于函数定义,表示该函数是全局可见的,但是不加也无妨
用于变量,表示声明该变量是全局变量,该变量的定义在别的文件
void:用于函数的返回类型时,表示无返回值;
用于函数的参数时,表示无参数
用于定义指针变量时,表示是通用型指针,即无类型指针变量,可以强制转化为任何类型的指针变量
*:乘法运算符
声明一个指针变量
对指针变量进行解引用
&:位的AND操作符
取地址操作符
p = sizeof * q;这里,编译器会将*当成对指针变量q的解引用,假设q是个指针变量的话,尽管*两边都有空格,这时就会返回q所指向的类型的字节数;如果q不是指针变量,那就是非法引用了;
apple = sizeof(int) * p;对于这个语句来说,要看p的类型了:
如果p是个指针变量,即 int *p,那么会报错:“*”: 非法,右操作数包含“int *”类型
如果p是个整形变量,且已经进行初始化,则是正确的,此处*为乘号,结果就是sizeof(int)乘以p;
或者是这样理解:
按照运算符的优先级来,先执行()执行完(int)后,(int)就相当于一个值,如果是间接访问符则编译错误,因为间接访问符会与p结合产生一个新值,两个值之间不能没有运算符,因此()后的*应该为乘号,根据优先级,sizeof先执行,得到sizeof(int)新值再与p相乘

逗号表达式:先执行逗号前面的内容,并且作为逗号后面表达式的条件,如果逗号后面的计算不需要逗号前面的结果,则将逗号前面的计算结果丢弃,直接计算逗号后面的表达式,最终结果就是逗号后面表达式的计算结果;
==和!=的优先级高于位运算&;
==和!=的优先级高于赋值符=;
算术运算符高于移位运算符;
逗号运算符优先级最低;
&和|优先级一样
优先级的顺序一直是个头疼的问题,还是按照经验来吧,除了加减乘除之外,其他操作符一律加上括号;
所有赋值运算符(包括符合赋值运算符)都具有右结合性,就是说表达式中最右边的操作最先执行,然后 从右到左依次执行:
a = b =c;c先赋值给b,b再赋值给a;
具有左操作性的操作符&和|则是从左至右依次执行;
结合性只用于出现两个以上相同优先级的操作符的情况;
9、gets()函数的缺陷:
char* gets(char* buffer)
任务是从流中读入一个字符串,存放在缓存buffer中,但是gets函数并不检查缓冲区的空间,如果函数调用者提供了一个指向堆栈的指针,并且gets()函数读入的字符数量超过了缓冲区的空间,gets()函数将会将多出来的字符继续写到堆栈中,这样就覆盖了堆栈原先的内容;
建议使用fgets()函数代替gets()函数,因为fgets()函数对读入的字符数设置了一个 限制,这样就不会超出缓冲区的范围了;
char* fgets(char*buffer,int bufsize,FILE* stream)
我以后就只用fgets()函数;
10、 sizeof(数组名):是整个数组的长度,即使数组只进行了部分初始化或者没有初始化,因为数组不管有没有初始化,都分配了内存空间,这和指针不同,除非指针进行初始化,否则,指针变量没有指向确定的位置,就是野指针,
int apple;
char *ch = "nihao";
int *p;
int *q = (int *)malloc(3*sizeof(int));
int ar[6] = {142,13,45,62,86,45};
int arr[7] = {142,13,45,62,86,45};
int arra[8];
apple = sizeof(p);结果为4,因为无论指向任何类型的指针变量,都是占4个字节
apple = sizeof(ch);结果为4,和上面原因相同
apple = sizeof(ar);结果为6
apple = sizeof(arr);结果为7,即使进行部分初始化,但是空间已经分配
apple = sizeof(arra);结果为8,没有进行初始化,但是空间已经分配完毕
apple = sizeof(q);结果为4,即使q指向的空间为12个字节
10、使用"\"字符可以对一些字符进行转义,包括Enter回车键,被转义的回车键在逻辑上把下一行当做当前行的延续,它可用于连接长字符串;
但是在"\"和回车键之间不小心留上一两个空格就会出现问题,即\ Enter和\Enter不一样,这个错误很难发现;
经验证,确实如此,如果我输入"\"之后,直接按回车键,即使下一行可以自动缩进,但是编译器依然把两行当成一个字符串处理;
但是,如果我在输入"\"之后,多输入一个空格键,然后再按回车键,则下一行不会被编译器当成当前行的延续;
11、空格不能省略:
ratio = *x/*y;
编译器会报错:fatal error C1071: 在注释中遇到意外的文件结束;
出错的原因:当/和*之间缺少空格,紧贴在一起时,就会被编译器理解成注释的开始部分,并把它与下一个*/之间所有的代码都变成注释的内容;
解决方法就是在/和*之间加上空格;
12、编译器日期被破坏:涉及到局部变量作用域、返回值的传递

这个程序打印出来的时间是错误的乱码;
问题出现在哪呢?
问题出现在函数的最后一行,也就是返回buffer的那行;buffer是一个自动分配内存的数组,是该函数的局部变量;当控制流离开声明自动变量(即局部变量)的范围时,自动变量便自动失效,这就意味着即使返回一个指向局部变量的指针,当函数结束时,由于该变量已经销毁,谁也不知道这个指针所指向的地址的内容是什么;
因为当包含自动变量的函数或代码块退出时,它们所占用的内存便被收回,它们的内容肯定会被下一个所调用的函数覆盖,这一切取决于堆栈中先前的自动变量位于何处,活动函数声明了什么变量,写入了什么内容;原先自动变量地址的内容可能立即被覆盖,也许稍后才能覆盖,这就是日期破坏问题难以发现的原因;
解决方案:
(1)返回一个指向字符串常量的指针:
char* func(){ return “only can return char string.”}
缺点是:如果字符串常量存储于只读内存区但以后需要改写它时,就会有麻烦;
(2)使用全局声明的数组:
#define MAXSIZE 50
char* my_global_array[MAXSIZE];
char* func(){
my_global_array[i] = ....
.........
return my_global_array[i]
}
适用于自己创建字符串的情况;
缺点是其他函数也能修改这个全局数组,而且该函数下一次调用也会覆盖该数组的内容;
(3)使用静态数组
char*func(){
static char buffer[20];
....................
return buffer;
}
这样就可以防止其他函数修改这个数组,只有拥有指向该数组的指针的函数才能修改这个静态数组;但是,该函数的下一次调用将覆盖这个数组的内容,所以调用者必须在使用之前使用或者备份数组的内容;和全局数组一样,大型缓冲区如果闲置不用是非常浪费内存空间的;
(4)显式分配一些内存、保存返回的值
char* func(){
char*s = (char*)malloc(120);
、、、
return s;
}
这个方法具有静态数组的优点,而且在每次调用时都创建一个新的缓冲区,所以该函数以后的调用不会覆盖以前的返回值,它适用于多线程的代码;它的缺点在于程序员必须承担内存管理的责任,根据程序的复杂度,这项任务可能很不容易,也可能很复杂;如果内存尚在使用就释放或者内存泄露,就会产生bug,因为人们很容易忘记释放已分配但不再使用的内存;
(5)也许最好的解决方案就是要求调用者分配内存来保存函数的返回值,为了提高安全性,调用者应该同时制定缓冲区的大小;
void func( char* result, int size){
strncpy(result,“that's all”,size);
}
buffer = malloc(size);
func(buffer,size);
、、、
free(buffer);
如果程序员可以在同一代码块中同时进行“malloc”和“free”操作,内存管理是最为轻松的;这个解决方案就可以实现这一点;
注:lint程序
lint程序能够检测到问题,并向你发出警告;Unix早期c语言设计中,把所有编译器中所有的语义检查措施都分离出来,错误检查由一个单独的程序完成,这个程序被称为“lint”;当把lint程序分离出来,是一个巨大的错误,尽管编译器变得很小,但是代价是:代码中混入了大量的bug和不可靠的编码风格,许多程序员缺省情况下在每次编译时并不适用lint程序;
作者项目中的绝大多数lint程序的错误信息原因只是需要一个显式的类型转换或lint注释:
(1)实参的类型在函数和调用之间发生了转变;
(2)一个期望接受3个参数的函数实际上只传递了它一个参数,该函数将从堆栈中再抓出两个参数;
(3)变量在设置前使用;
*****************************************************************************************************************************************************************************************
2013年3月28日更新
*****************************************************************************************************************************************************************************************
第三章 分析C语言的声明
1、数据类型
(1)volatile和const关键字,只能用在声明中,不能用在使用中;
(2)强制类型转换:
char(*a)[20];
a = (char (*)[20])malloc(20*sizeof(char));
这说明,a的数据类型就是char (*)[20];
如果把星号两边的括号拿掉,代码就会变成非法;
(3)声明确定了数据的基本类型和初始值(如果有的话)
2、合法的声明存在限制:
(1)函数的返回值不能是一个函数,即func()()是错误的
(2)函数的返回值不能是一个数组,即func()[]是错误的
(3)数组里面不能有函数,所以func[]()是错误的
3、这样的声明时合法的:
(1)函数允许返回值是一个函数指针:int (*func())();
(2)函数的返回值允许是一个指向数组的指针:int (*func())[];
(3)数组里面允许有函数指针:int (*func[])()
(4)数组里面允许有其他数组:int func[][];
4、结构
结构就是一种把一些数据项组合在一起的数据结构;
结构的成员变量可以是任何其他数据声明:单个数据项、数组、其他结构、指针等;
注意:位段的类型必须是:int、unsigned int、signed int(或加上限定符),至于int位段的值可不可以取负值取决于编译器;
(1)结构的声明
结构类型的声明与变量的声明最好分开,这样程序更具有可读性;
参数在传递时首先尽可能的存放在寄存器中,这是为追求速度考虑的;
一个int型参数一般会被传递到寄存器中,而结构参数则很可能被传递到堆栈中;
5、联合
(1)联合一般是作为大型结构的一部分存在的;在有些大型结构中,存在一些与实际信息表示有关的隐式或显式的信息,如果存储数据时是一种类型,但在提取该数据时却成了另外一种类型,这显然存在明显的类型不安全性。
(2)联合一般被用来节省空间,因为有些数据项是不可能同时出现,如果同时存储他们,显然浪费。
(3)联合也可以把同一个数据解释成两种不同的东西,而不是把两个不同的数据解释为同一种东西:
union bits32_tag
{
int whole;//一个32位的值
struct
{
char c0;
char c1;
char c2;
char c3;
} byte;//4个8位的字节
} value:
这个联合允许程序员提取整个32位值(int),也可以提取单独的字节字段,如value.byte.c0等,采用其他的办法也能达到这个问题(利用强制类型转换,就可以截取低八位,或者是采用位的与运算);
在实际工作中结构的次数将远远多于联合;
6、枚举
枚举通过一种简单的途径,把一串名字与一串整形的值联系在一起;
enum 可选标签 { 内容 }......可选变量定义;
缺省情况下,整型值从0开始,如果列表中的某个标识符进行了赋值,那么紧接其后的那个标识符的值就比所赋的值大1,然后类推;
枚举有一个优点:#define定义的名字一般在编译时被丢弃,而枚举名字则通常一直在调试器中可见,可以在调试代码时使用它们;
7、typedef
普通的声明表示:这个名字是一个指定类型的变量;
而typedef关键字并不 创建一个变量,而是宣称这个名字是指定类型的同义词;
typedef为数据类型创建别名,而不是创建新的数据类型,可以对任何类型进行typedef声明;
typedef和宏文本替换之间存在一个关键性的区别:把typedef看成是一种彻底的“封装类型”--在声明它之后不能再往里面增加别的东西;
主要是体现在两个方面:
(1)首先可以用其他类型说明符对宏类型名进行扩展,但是对typedef所定义的类型名却不能这样做:
#define peach int
unsigned peach a;//正确
typedef peach int;
unsigned peach a;//错误
(2)在连续几个变量的声明中,用typedef定义的类型能够保证声明中所有的变量均为同一类型,而用#define定义的类型则无法保证:
#define int_ptr int*
int_ptr pt,qt;
经过宏扩展:
int* pt,qt;
结果是pt为指向整型的指针变量,而qt是整型变量
typed int* int_ptr;
int_ptr pt,qt;
则pt,qt都是指向整型的指针变量。
8、C语言存在多种名字空间:
标签名label name
标签tag:这个名字空间用于所有的结构、枚举和联合
成员名:每个结构或联合都有自身的名字空间
其他
(1)在同一个名字空间内,任何名字都必须具有惟一性,但是在不同的名字空间里可以存在相同的名字;由于每个结构和联合具有自己的名字空间,所以同一个名字可以出现在许多不同的结构内;
(2)由于在不同的名字空间内使用同一个名字是合法的,所以:
struct foo{ int foo ;}foo;//这个语句声明了结构标签foo以及变量foo;
实际效果: 可以使用结构标签foo定义新的变量:struct foo foo1;这样就定义了新变量foo1
但是 : foo foo2;这样使用是错误的,相当于:int i;i j;
typedef struct foo{ int foo;} foo;//这个语句声明了结构标签foo以及typedef声明的结构类型“foo”,
实际效果: 可以使用结构标签foo定义新的变量:struct foo foo1;定义了新变量foo1
也可以使用结构类型foo定义新的变量:foo foo2;定义了新变量 foo2
注:当你用两个不同的东西时,在计算机科学中有一个比较好的原则是用不同的名字来称呼它们;这样做就减少了混淆的危险;如果有可能搞不清哪个名字是结构标签,久违它去一个以“_tag”结尾的名字;
*****************************************************************************************************************************************************************************************
2013年3月29日更新
*****************************************************************************************************************************************************************************************
四、令人震惊的事实:数组和指针并不相同
1、热身:
注意一下声明的区别:
extern int *x;
extern int y[];
第一条语句是声明x是一个指向int型数据的指针变量;第二条语句是声明y为整型数组,长度未定,
2、数组并非指针:
例子:
文件1:
int mango[100];
文件2:
extern int *mango;
.......................
/*一些引用mango[i]的代码*/
文件1定义了数组mango,文件2声明它为指针,但是这是错误的,它将数组定义等同于指针的外部声明;
(1)声明和定义
C语言中的对象必须有且只有一个定义,但它可以有多个extern声明;
定义是一种特殊的声明,它创建了一个对象;
声明简单的说明了在其他地方创建的对象的名字,它允许你使用这个名字;
| 定义 | 只能出现在一个地方 | 确定对象的类型并分配内存,用于创建新的对象。例如int arr[100]; |
| 声明 | 可以多次出现 | 描述对象的类型,用于指代其他地方定义的对象(例如在其他文件里)例如:extern int arr[] |
区分定义和声明:
声明相当于普通的声明:它所说明的并非自身,而是描述其他地方的创建的对象;
定义相当于特殊的声明:它为对象分配内存;
extern对象声明告诉编译器对象的类型和名字,对象的内存分配在别处进行;
由于并未在声明中为数组分配内存,所以并不需要提供关于数组长度的信息;
对于多维数组,需要提供除最左边一维之外其他维的长度---这就给编译器足够的信息产生相应的代码;
(2)数组和指针时如何访问

关键之处在于每个符号的地址在编译时可知,所以如果编译器需要一个地址(可能还需要加上偏移量)来执行某种操作,它就可以直接进行操作,并不需要在这之前先取得具体的地址;相反,对于指针,必须首先在运行时取得它的当前值,然后才能对他进行解除引用操作

这就是为什么extern char a[]和extern char a[100]等价的原因:这两个声明都提示a是一个数组,也就是一个内存地址,数组内的字符可以从这个地址找到,编译器并不需要知道数组总共有多长,因为它只产生偏离起始地址的偏移地址,从数组中提取一个字符,只要简单的从符号表显式的a的地址加上下标,需要的字符就位于这个地址中;

相反,如果声明extern char*p,它将告诉编译器p是一个指针变量,它指向的对象是一个字符,为了取得这个字符,必须得到地址p的内容,把它作为字符的地址并从这个地址中取得这个字符,指针的访问灵活,但是需要增加一次额外的提取,即从p从取得地址这一步;
(3)定义为指针,但是以数组方式引用,会发生什么?
现在看一下,当一个外部数组的实际定义是一个指针,但是却以数组的方式对其引用时,会引起什么问题;

对照图C的访问方式:
char *p = "abcdefgh";.........p[3]
和图A的访问方式:
char a[] = "abcdefgh";.......a[3]
这两种情况下,都可以取得字符'd',但两者的途径非常不一样;
当书写了extern char *p,然后用p[3]来引用其中的元素时,其实质是图A和图B访问方式的组合;首先,进行图B所示的间接引用,然后,如图A所示用下标作为偏移量进行直接访问,编译器会:
第一步:取得符号表中p代表的地址,提取存储于此处的指针;
第二步:把下标所表示的偏移量与指针的值相加,产生一个地址;
第三步:访问上面这个地址,取得字符。
编译器已被告知p是一个指向字符的指针(相反,数组定义告诉编译器p是一个字符序列);p[i]表示“从p所指的地址开始,前进i步,每步都是一个字符(即每个元素的长度为一个字节)”;如果是其他类型的指针,其步长为该数据类型的所占空间;
既然把p声明为指针,那么不管p原先是定义为指针还是数组,都会按照上面所示的三个步骤进行操作,但是只有当p原来定义为指针时这个方法才正确;
原先的定义却是char p[10]这种情形,用p[i]这种形式提取这个数组的内容时,实际得到的是一个字符,按照数组的方式来访问就是;
第一步:p是数组名,即指向数组首地址,将下标i表示的偏移量i*1,与指针相加,即p+1
第二部:取地址(p+1)的内容,即*(p+1) = p[i];
但是现在将它声明为指针,按上边步骤来说:
第一步:p就是指向数组首地址的指针,先对&p进行解引用得到p,p实际上是p[0],也就是一个字符,但是此处却将它当成地址p;
第二步:然后将下标i所表示的偏移量i*1(乘以1是因为char型数据占一个字节),与指针相加,即p + i,而实际上是p[0]+i;
第三步,访问上边的地址,取得字符,即*(p[0] + 1),显然这是错误的
对比一下:

黑色即代表,当采用数组引用时,直接对指针p进行偏移,然后取p+i的内容,即p[i]
红色即代表,当采用指针引用时,先对p的地址解引用得到p,然后对p进行偏移,然后再取p+i的内容,即p[i]
指针引用时,将p当成&p,将*p当成p,将*(*p+i)当成*(p+i)
当数组引用时,由于数组时连续分配内存,此时指针a直接指向数组的首地址,即直接指向数组的第一个元素
当指针引用时,不是连续分配内存,此时指针p虽然也是指向数组的首地址,但是指针
3、再说指针引用和数组引用的不同:
由于每个符号的地址在编译时可知,即编译器会为每个符号分配一个空间,或者说分配一个地址(左值):
即
int a;尽管没有对a进行初始化,但是编译器为变量a分配了空间,即编译器为变量a分配了一个地址(左值),变量a在运行时一直保存于这个地址,相反存储于变量中的值只有运行时才可知;对于float、char、double型数据也是如此;
int a[10];尽管没有对数组a进行初始化(我为什么不说数组a[10]呢,其实数组定义本来应该是int [10] a,这样即表明a是包含10个int型数据的变量,这就是所谓的数组),但是编译器为变量a分配了空间,即为变量a分配了地址(左值),那么这个空间有多大,即10*sizeof(int)= 40个字节的空间;
int*p:尽管没有对指针变量p进行初始化,即此刻p的值是不可预测的,可能指向任意处,但是编译器仍然为变量p分配的一个地址,即引用&p是合法的但是引用p是不合法的;
针对以上三种情况,编译器符号表对于三种数据类型分别存储什么呢?
其实存储的是每个符号的地址:
对于int a;来说,符号表存放的是&a
对于int a[10];来说,符号表存放的是a
对于int*p;来说,符号表存放的是&p;
当对数组下标引用时,例如对于c = a[i]来说,编译器需要一个地址执行取数组元素,这里需要加上偏移量,由于编译器符号表中直接就有a的地址,所以可以直接操作,不必解引用,具体如下:
第一步:由于编译器符号表中直接就有数组a的首地址,那么取下标i,将i+首地址a,即(a + i),即(&a[0] + i *步长);
第二步:取地址(i*步长 +&a[0])的内容,这样就把a[i]给取出来了
当对指针来说,必须首先在运行时取得它的当前值(因为右值只有在运行时才知道,编译时只知道左值),然后才能对它进行解引用操作:
例如对于char *p = “abcdefgh”;来说,编译器符号表中其实只存放了p的地址,即&p而不是存放p,这一点一定要清楚,至于p到底是何值,编译器并不关心,这是程序员的事,首先,要在运行取得p的值,然后对p进行解引用*p,具体如下:
第一步:在编译器符号表中有一个符号p,它的地址&p已知,但是p却未知,先取地址&p的内容,就是p;
第二步:取得下标i的值,并将它与p相加,得到偏移地址p+i*步长
第三步:取地址[p+i*步长]的内容

4、使声明与定义相匹配
指针的外部声明与数组定义不匹配的问题很容易修正,只要修改声明,使之与定义相匹配,如下所示:
文件一:
int mango[100];
文件二:
extern int mango[];
5、数组和指针的其他区别:
| 指针 | 数组 |
| 保存数组的地址 | 保存数据 |
| 间接访问数据,首先取得指针的内容,把它作为地址,然后从这个地址提取数据 如果指针有一个下标[i],就把指针的内容加上i作为地址,从中提取数据 | 直接访问数据,a[i]只是简单的以a+i为地址取得数据 |
| 通常用于动态数据结构 | 隐式分配和删除 |
| 相关的函数malloc(),free() | 隐式分配和删除 |
| 通常指向匿名数据 | 自身即为数据名 |
数组和指针都可以在它们的定义中用字符串常量进行初始化,尽管看上去一样,底层的机制却不相同:
定义指针时,编译并不为指针所指向的对象分配空间,它只是分配指针本身的空间,除非在定义时同时赋给指针一个字符串常量进行初始化;例如:
char*p = “abcdefg”;
注意,只能对字符串常量才是如此;不能指望为浮点数之类的常量分配空间,如:
float* pt = 3.141;这样就是错误的;
在ANSI C中,初始化指针所创建的字符串常量被定义为只读,如果试图通过指针修改这个字符串的值,程序就会发现未定义的行为;在有些编译器中,字符串常量被存放在只允许读取的文本段中,以防止它被修改;
数组也可以用字符串常量进行初始化:
char a[] = "gooseberry";
与指针相反,由字符串常量初始化的数组是可以修改的,其中的单个字符在以后可以改变,就如:strncpy(a,"black",5);就将数组的值修改为:“blackberry”
*****************************************************************************************************************************************************************************************
2013年4月1日更新
*****************************************************************************************************************************************************************************************
五、对链接的思考
1、链接器:编译器创建一个输出文件,这个文件包含了可重定位的对象,这些对象就是与源程序对应的数据和机器指令;
编译器中分离出来的单独程序包括:预处理器(preprocessor)、语义和语法检查器(syntactic and semantic)、代码生成器(code generator)、汇编程序(assembler)、优化器(optimizer)、链接器(linker),当然还包括一个调用所有程序并向各个程序传递正确选项的驱动器程序(driver program);优化器可以加到上边所有阶段后面:

之所以分成几个独立的程序,是因为在程序中如果每个具有特定功能的部分自身都是一个完整的程序,就会更容易 设计和维护。
代价是花费的时间更长;
-#:查看编译过程的各个独立阶段
-V:提供版本信息
-W:向各个阶段传递选项信息,“W”后面跟一个字符(提示哪个阶段),一个逗号,然后就是具体的选项
目标文件并不能直接执行,它需要载入到链接器中,链接器确认main函数为初始进入点(程序开始执行的地方),把符号引用(symbolic reference)绑定到内存地址,把所有的目标文件集中在一起,再加上库文件,从而产生可执行文件。
2、静态链接和动态链接
静态链接:如果函数库的一份拷贝是可执行文件的物理组成部分,那么我们称之为静态链接
动态链接:如果可执行文件只是包含了文件名,让载入器在运行时能够寻找程序所需要的函数库,那么我们称之为动态链接;
收集模块准备执行的三个阶段的规范名称是:链接-编辑(link-editing)、载入(loading)和运行时链接(runtime linking)。
静态链接的模块被链接-编辑并载入以便运行;
动态链接的模块被链接-编辑然后载入,并在运行时进行链接以便运行;
程序执行时,在main()函数被调用之前,运行时载入器把共享的数据对象载入到进程的地址空间;外部函数被真正调用之前,运行时载入器并不解析它们,所以即使练级了函数库,如果并没有实际调用,也不会带来额外开销;

即使是静态链接中,整个libc.a文件也没有全部载入到可执行文件中,所装入的只是需要的函数。
3、动态链接的优点
动态链接是一种更为现代的方法:它的优点是可执行文件的体积可以非常小,虽然运行速度慢一些,但是动态链接能够更有效的利用磁盘空间,而且链接-编辑阶段的时间也会缩短(因为链接器的有些工作被推迟到载入时);
动态链接的目的之一是ABI(application binary interface )
动态链接的主要目的就是把程序与它们使用的特定的函数库版本中分离出来的,取而代之的是,我们约定由系统向程序提供一个接口,该接口保持稳定,不随时间和操作系统的后续版本发生变化。
程序可以调用接口所承诺的服务,而不必担心这些功能是怎样提供或者它们的底层实现是否改变;由于它是介于应用程序和函数库二进制可执行文件所提供的服务之间的接口,所以称它为应用程序二进制接口(ABI);
尽管单个可执行文件的启动速度稍受影响,但动态链接可以从两个方面提高性能:
(1)动态链接可执行文件比功能相同的静态链接可执行文件的体积小,它能够节省磁盘空间和虚拟内存,因为函数库只有在需要时才被映射到进程中。以前,避免函数库的拷贝绑定到每个可执行文件的唯一方法就是把服务置于内核中而不是函数库中,这就带来了可怕的内核膨胀问题。
(2)所有动态连接到某个特定函数库的可执行文件在运行时共享该函数库的一个单独拷贝。操作系统内核保证映射到内存中的函数库可以被所有使用它们的进程共享。这就提供了更好的I/O和交换空间利用率,节省了物理内存,从而提高了系统的整体性能,如果可执行文件时静态链接的,每个文件都将拥有一份函数库的拷贝,显然极为浪费。
优点还有:
(1)动态链接使得函数库的版本升级更为容易,新的函数库可以随时发布,只要安装到系统中,旧的程序就能够自动获得新版本函数库的优点而无需重新链接。
(2)动态链接允许用户在运行时选择需要执行的函数库,这就使为了提高速度或提高内存使用效率或包含额外的调试信息而创建新版本的函数库是完全可能的,用户可以根据自己的喜好,在程序执行时用一个库文件取代另一个库文件。
注:动态链接是一种“just-in-time(JIT)”链接,这意味着程序在运行时必须能够找到他们需要的函数库;链接器通过把库文件名或路径名植入可执行文件中来做到这一点,这就意味着,函数库的路径不能随意移动,除非在链接器中进行特别说明,否则,当调用该函数库的函数时,就会发生:
运行时导致错误,can't open file:
当在一台机器上编译完程序后,把它拿到另一台不同的机器上运行时,也可能出现这种情况;执行程序的机器必须具有所有该程序需要连接的函数库。
使用共享函数库的主要原因就是获得ABI的好处---使得你的软件不必因新版函数库或操作系统的发布而重现链接;附带的好处,提高系统的总体性能。
任何人都可以创建静态或动态的函数库,只需简单的编译一些不包含main函数的代码,并把编译所生的.o文件用正确的实用工具进行处理---如果是静态库,使用ar,如果是动态库,使用ld。
使用静态链接的最大危险在于将来版本的操作系统可能与可执行文件所绑定的系统函数库不兼容。
动态链接库由链接编辑器ld创建,根据约定,动态库的文件扩展名为“.so”,表示“shared object(共享对象)”----每个链接到该函数库的程序都共享它的同一份拷贝。而静态链接库则相反,每个对象都拥有一份该函数库内容的拷贝,显得浪费。
动态链接库的最简单形式可以通过在cc命令上加上-G选项来创建;
-L/home/linden选项告诉链接器在链接时从哪个目录寻找需要链接的函数库;
-R/home/linden选项告诉链接器在运行时从哪个目录寻找需要链接的函数库;
-K pic来为函数库产生与位置无关的代码;
与位置无关的代码表示用这种方式产生的代码保证对于任何全局数据的访问都是通过额外的间接方法完成的;这使它很容易对数据进行重新定位,只要简单的修改全局偏移量表的其中一个值就可以了;类似的,每个函数调用的产生就像是通过过程链接表的某个间接地址所产生的一样;这样,文本可以很容易的重新定位到任何地方,只要修改一下偏移量表就可以了;所以,当代码在运行时被映射进来时,运行时链接器可以直接把它们放在任何空闲的地方,而代码本身并不需要修改。
在缺省情况下,编译器并不产生与位置无关的代码,因为额外的指针解除引用操作将使程序在运行时稍稍变慢;然而,如果不使用与位置无关的代码,所产生的代码就会被对应到固定的地址
4、函数链接库的5个秘密
(1)动态库文件的扩展名是".so",而静态库文件的扩展名是".a"
(2)例如,你通过-lthread选项,告诉编译链接到libthread.so;
传给C编译器的命令行参数里并没有提到函数库的完整路径名,它甚至没有提到在函数库目录中该文件的完整名字,实际上,编译器被告知根据选项-lname链接到相应的函数库,函数库的名字是libname.so----换句话说,"lib"部分和文件的扩展名被省掉了,但在前面加一个“l”
(3)编译器期望在确定的目录找到库
编译器选项-Lpathname告诉链接器一些其他的目录,如果命令中加入了-l选项,链接器就往这些目录查找函数库;不提倡使用环境变量的做法,一般还是在链接时使用-Lpathname和-Rpathname
(4)观察头文件,确认所使用的函数库
一个很好的建议就是可以观察所使用的#include指令,在程序中所包含的每个头文件都可能代表一个必须链接的库,这个建议也适用于C++;问题是:头文件的名字通常并不与它所对应的函数库名相似。
例如:

函数库链接所存在的另一个不一致性就是函数库做包含的某个函数的原型可能与其他头文件中所声明的函数的原型一样;例如在头文件<string.h>、<stdio.h>和<time.h>中声明的函数通常是在同一个库libc.so中提供。
(5)与提取动态库中的符号相比,静态库中的符号提取的方法限制更严
动态链接中,所有的库符号进入输出文件的虚拟地址空间中,所有的符号对于链接在一起的所有文件都是可见的;
相反,对于静态链接,在处理静态库时,它只是在静态库中查找载入器当时多指导的未定义符号。
在编译器命令行中各个静态链接库出现的顺序是非常重要的:因为符号是通过从左到右的顺序进行解析的,如果相同的符号在两个不同的函数库中有不同的定义,静态库出现的顺序不同,其结果可能不同;如果在自己的代码之前引入静态库,因为此时尚未出现未定义的符号,所以它不会从函数库中提取任何符号,接着,当目录文件被链接器处理时,它所有的对函数库的引用都将是未实现的;
为了能从某个静态库中提取所需要的符号,首先需要让文件包含未解析的引用,解决方法:
始终将-l函数库选项放在编译命令行的最右边。
注意:不要让程序中的任何符号成为全局的,除非有意把它们作为程序的接口之一。
5、产生链接器报告文件
可以在ld程序中使用“-m”选项,让链接器产生一个报告,它里面包括了被Interpose的符号说明,通常,带“-m”选项的ld会产生一个内存映射或列表,显示在可执行文件中的什么地方放入了哪些符号,它同时显示了同一个符号的多个实例,通过查看报告的内容,用户可以判断是否发生了Interpositioning。
ld程序中的“-D”选项,目的是提供更好的链接-编辑调试。这个选项允许用户显示链接-编辑过程和所包含的输入文件,如果需要监视从静态库中提取对象的过程,这个选项尤其是有用,它同时可用于显示运行时绑定信息。

*****************************************************************************************************************************************************************************************
2013年4月3日更新
*****************************************************************************************************************************************************************************************
六、运行时数据结构
代码和数据的区别可以认为是编译时和运行时的分界线。
编译器的绝大部分工作都跟翻译代码有关,必要的数据存储管理的绝大部分都在运行时进行。
学习运行时系统的3个主要理由:
(1)有助于优化代码,获得最佳的效率
(2)有助于理解更高级的材料
(3)当陷入麻烦时,它可以使分析问题更加容易
UNIX中的可执行文件是以一种特殊的方式加上标签,这样系统就能确认它们的特殊属性,为重要的数据定义标签,用独特的数字唯一的标识该数据是一种普遍采用的编程技巧;标签所定义的数字通常称为“神奇”数字,它是一种能够确认一组随机的二进制位集合的神秘力量。
例如:
(1) 超级块(UNIX文件系统中的基础数据结构)就是用下面这个神奇数字唯一标识的:
#define FS_MAGIC 0x011954
这是Kirk McKusick的生日,Berkeley fast文件系统的实现者。
(2) a.out文件中也存在类似的神奇数字,在AT&T的UNIX System V发布之前,a.out文件被标识为神奇数字0407.
1、段
目标文件和可执行文件可以有几种不同的格式;但所有不同的格式都具有一个共同的概念,那就是段segments。
就目标文件而言,段就是二进制文件中简单的区域,里面保存了和某种特定类型(如符号表条目)相关的所有信息。
注:在UNIX中,段表示一个二进制文件相关的内容块;
在Intel x86的内存模型中,段表示一种设计的结果,在这种设计中,地址空间并非一个整体,而是分成一些64K大小的区域,称之为段
(1)当在一个可执行文件中运行size命令时,它会告诉你这个文件中的三个段(文本段、数据段和bss段)的大小
$echo;echo "text data bss total ";size a.out
注:可执行程序包括BSS段、数据段、文本段(代码段);BSS(block started by symbol)通常是指用来存放程序中未初始化的全局变量和静态变量的一块内存区域;特点是可读写的,在程序执行之前的BSS段被自动清0,所以未初始化的全局变量在程序执行之前已经成0了;
注意BSS段和数据段的区别,BSS段存放的是未初始化的全局变量和静态变量,而数据段存放的是初始化后的全局变量和静态变量。

由于BSS段只保存没有值的变量,所以事实上它并不需要保存这些变量的映像,运行时所需要的BSS段的大小记录在目标文件中,但BSS段(不像其他段)并不占据目标文件的任何空间。
(2)检查可执行文件的内容的另一种方法是使用nm或dump实用工具。
注:
编程挑战:
查看可执行文件中的段:
(1)编译“Hello World”程序,在可执行文件中执行ls -l,得到文件的总体大小,运行size得到文件里各个段的大小。。
$ size hello.out
text data bss dec hexfilename
1176 504 16 1696 6a0hello.out
$ ls -l hello.out
-rwxrwxr-x 1 test test 8377 4月 2 03:54 hello.out
(2)增加以全局的int arr[1000]数组声明,重新进行编译,再用上面的命令得到总体以及各个段的大小,注意前后的区别:
$ size hello.out
text data bss dec hexfilename
1176 504 4032 5712 1650hello.out
$ ls -l hello.out
-rwxrwxr-x 1 hangma hangma 8405 4月 2 03:56 hello.out
区别:bss段明显增大,增大的尺寸恰好是数组arr的大小;但是总体尺寸却是增加不大,只增加了28个字节
(3)现在,在数组的声明中增加初始值(记住,C语言并不强迫对数组进行初始化时为每个元素提供初始值)。这将使数组从BSS段转换到数据段,重复上边的测试,注意各个段前后大小的区别。
$ size hello.out
text data bss dec hexfilename
1176 4520 16 5712 1650hello.out
$ ls -l hello.out
-rwxrwxr-x 1 hangma hangma 12437 4月 2 04:23 hello.out
(4)现在,在函数内声明一个巨大的数组;然后再声明一个巨大的局部数组,但这次加上初始值,重复上面的测试。定义于函数内部的局部数组存储于可执行文件中码?又没有初始化有什么不同?
在函数内声明一个数组int a[1000];但不进行初始化:
$ ls -l hello.out
-rwxrwxr-x 1 hangma hangma 12437 4月 11 12:22 hello.out
$ size hello.out
text data bss dec hexfilename
1176 4520 16 5712 1650hello.out
定义b[1000]并进行初始化
ls -l hello.out
-rwxrwxr-x 1 hangma hangma 12437 4月 11 14:27 hello.out
$ size hello.out
text data bss dec hexfilename
1272 4520 16 5808 16b0hello.out
定义于函数内部的局部数组不是存储于可执行文件,又没有初始化并没有什么不同,说明局部变量只有在执行时才创建;
不同之处在于文本段不同。
(5)如果在调试阶段编译,文件和段的大小又没有变化?是为了最大程度的优化?
注:
(1)数据段保存在目标文件中;
(2)BSS段不保存在目标文件中,除了记录BSS段在运行时所需要的大小
(3)文本段是最容易受优化措施影响的段
(4)a.out文件的大小受调试状态下编译的影响,但段不受影响。
2、操作系统在a.out文件里干了些什么
段可以方便的映射到对象中,链接器在运行时可以直接载入这些对象;载入器只是取文件中每个段的映像,并直接将它们放入内存中;从本质上来说,段在执行的程序中是一块内存区域,每个区域都有特定的目的。
文本段包含程序的指令,链接器把指令直接从文件拷贝到内存中,以后再也不用管它;典型情况下,程序的文本无论是内容还是大小都不会改变,有些操作系统和链接器甚至可以向段中不同的section赋予适当的属性。
(1)可执行文件中的段在内存中如何布局

数据段包含经过初始化的全局和静态变量以及它们的值;BSS段的大小从可执行文件中得到,然后链接器得到这个大小的内存块,紧跟在数据段之后;当这个内存区进入程序的地址空间后全部清零,包括数据段和BSS段的整个区段此时通常称为数据区;这是因为在操作系统的内存管理术语中,段就是一片连续的虚拟地址,所以相邻的段被接合;一般情况下,在任何进程中数据段是最大的段。
此外,需要一些内存空间用于保存局部变量、临时数据、传递到函数中的参数等,堆栈段就是用于这个目的;还需要堆空间,用于动态分配的内存,只要调用malloc()函数,就可以根据需要在堆上分配内存;
注意虚拟地址空间的最低部分未被映射,也就是说,它位于进程的地址空间内,但并未赋予物理地址,所以任何对它的引用都是非法的,在典型情况下,它是从0地址开始的几K字节,它用于捕捉使用空指针和小整形值的指针引用内存的情况。
(2)当考虑共享库时,进程的地址空间:

3、运行时系统在a.out里干了什么:
运行时数据结构有:堆栈、活动记录、数据、堆等
(1)堆栈段
堆栈段包含单一的数据结构-堆栈:是一个动态内存区域,实现一种后进先出的结构;
堆栈段的插入和删除都需要在栈顶操作,但是可以修改栈中间单元的数据;
函数可以通过参数或者全局变量访问它所调用的函数的局部变量,运行时系统维护一个指针,通常称为sp,用于提示堆栈当前顶部位置。
堆栈段有三个主要用途:
1)堆栈为函数内部声明的局部变量提供存储空间,即函数内部的局部变量都是存放在堆栈中,
2)进行函数调用时,堆栈存储与此有关的一些维护性信息:函数调用地址、任何不适合装入寄存器的参数或者一些寄存器值的保存
3)堆栈也可以用作暂时存储区:计算一个很长的算术表达式,可以把部分结果压到堆栈中,当需要时再把它从堆栈中取出。
2、过程活动记录
每当函数被调用时,都会产生一个过程活动记录,这是一种数据结构,用于支持过程调用,并记录调用结束后返回调用点所需要的全部信息。
过程活动记录也存放于堆栈中。

运行时系统维护一个指针,通常称为fp,用于提示活动堆栈结构,它的值是最靠近堆栈顶端的过程活动记录的地址;

程序从main()函数开始,堆栈向下生长。
注:尽管上文中说将过程活动记录压到堆栈中,但过程活动记录并不一定存在于堆栈中;事实上,尽可能的把过程活动记录的内容放到寄存器中会使函数调用的速度更快。
5、setjmp和longjmp


6、UNIX中的堆栈段
在UNIX中,当进程需要更多的空间时,堆栈段会自动生长;当试图访问当前系统分配给堆栈的空间之外时,它将产生一个硬件中断,称为页错误。
正常情况下,内核通过向违规的进程发送合适的信号来处理无效地址的引用;
在堆栈顶端的下端有一个称为red zone的小型区域,如果对这个区域进行引用,并不会产生失败,相反,操作系统通过一个好的内存块来增加堆栈段的大小。
内存映射硬件确保你无法访问操作系统分配给你的进程之外的内存。
7、DOS中的堆栈段
在DOS中,建立可执行文件时,堆栈的大小必须同时确定,而且它不能在运行时增长,如果超过,会发生STACK OVERFLOW;
*****************************************************************************************************************************************************************************************
2013年4月11日更新
*****************************************************************************************************************************************************************************************
第七章 对内存的思考
1、段:
在UNIX系统中,段是一块以二进制形式出现的相关内容;
在x86系统中,段是内存模型设计的结果,内存被分成以64K为单位的区域,每个这样的区域便成为段。

2、计算机系统结构的真正挑战不在于内存的容量,而是内存的速度,在内存和CPU的性能之间存在一道很深的鸿沟,CPU的速度很快,但是内存的速度很慢。
3、
4、虚拟内存
为了解决物理内存大小的限制,提出了虚拟内存的概念:基本思路是用廉价但缓慢的磁盘来扩充快速却昂贵的内存;在任一时刻,程序实际需要使用的虚拟内存区段的内容被载入物理内存中,当物理内存中的数据有一段时间未被使用,它们就可能被转移到硬盘中,节省下来的物理内存空间用于载入需要使用的其他数据。
5、Cache存储器
(1) Cache存储器是多层存储概念的更深扩展;
特点是容量小、价格高、速度快;
Cache位于CPU和内存之间,是一种极快的存储缓冲区。
当数据从内存读入时,整行的数据被装入Cache,如果程序具有良好的地址引用局部性,那么CPU以后对临近数据的引用就可以从快速的Cache读取,而不用从缓慢的内存中读取;Cache操作的速度与系统的周期时间相同;
典型情况下,主存的存取速度可能只有它的四分之一;
Cache包含一个地址列表以及它们的内容,随着处理器不断变化它们的引用地址,Cache的地址列表也不断变化,而且CPU对内存的任何访问都要经过Cache。
过程:
当处理器需要从一个特定的地址提取数据时,这个请求首先递交给Cache,如果数据已经存在于Cache,它就可以立即被提取,否则,Cache向内存传递这个请求,于是就要进行较缓慢的访问内存操作,内存读取的数据以行为单位,在读取的同时也装入到Cache中。
用图形表示:

(2)Cache的组成
| 术语 | 定义 |
| 行:line | 行就是对Cache进行访问的单位;每行由两部分构成:一个数据部分以及一个标签,用于指定它多代表的地址 |
| 块:block | 一个Cache行内的数据被称做块;来回移动于Cache行和内存之间的字节数据就保存在块中;一个典型的块为32字节; 一个Cache行的内容代表特定的内存块,如果处理器试图访问属于该块地址范围的内存,它就会做出反应,速度自然要比访问内存快得多 在计算机行业,对绝大多数人来说,块和行的概念分的并不是特别清 |
| Cache | 一个Cache(一般为64K到1M之间,也可能更多)由许多行组成,有时也是用相关的硬件来加速对标签的访问,为了提高速度,Cache的位置离CPU很近,而且内存系统和总线经过高度优化,尽可能的提高大小等于Cache块的数据块的移动速度。 |
6、数据段
数据段包含一个对象,即堆heap,能够根据需要自动增长;堆用于动态分配的存储,也就是通过malloc函数获得的内存,并通过指针访问;

堆内存的回收不必与它所分配的顺序一致,甚至可以不回收,所以无序的malloc/free最终会产生堆碎片,堆对它的每块区域都需要密切留心,其中一种策略就是建立一个可用块的链表,每块由malloc分配的内存块都在自己的前面标明自己的大小;
被分配内存总是经过对齐,以适合机器上最大尺寸的原子访问;回收的内存可供重新使用,但并没有办法把它从你的进程移出交还给操作系统?;
堆的末端由一个称为break的指针来标识,当堆管理器需要更多内存时,它可以通过系统调用brk和sbrk来移动break指针,一般情况下,不必由自己显式的调用brk,如果分配的内存容量很大,brk最终会被自动调用;
用于管理内存的调用是:
malloc和free---------------从堆中获得内存以及把内存返回给堆。
brk和sbrk-----------------调整数据段的大小至一个绝对值。
7、内存泄露
(1)堆经常会出现两种类型的问题:
内存损坏:释放或改写仍在使用的内存;
内存泄露:未释放不再使用的内存。
注:alloca()函数:栈上动态分配内存进行讨论,分配的内存即为栈内存,栈上的内存有一个特点即是不用我们手工去释放申请的内存。栈内存由一个栈指针来开辟和回收,栈内存是从高地址向低地址增长的,增长时,栈指针向低地址方向移动,指针的地址值也就相应的减小;回收时,栈指针向高地址方向移动,地址值也就增加。所以栈内存的开辟和回收都只是指针的加减,由此相对于分配堆内存可以获得一定的性能提升
在C99标准之前,C语言是不支持变长数组的,如果想要动态开辟栈内存以达到变长数组的功能就得依靠alloca函数。其实在gcc下,c99下的变长数组后台也是依靠alloca来动态分配栈内存的,当然这里不能完全说是调用alloca来实现的,alloca可能被优化并内联(当然你还是可以说这是在调用)。这里就不纠结这个问题了,在本文不属于重点。实际中,alloca函数是不推荐使用的,他存在很多不安全的因素。
alloca()不具有移植性:在没有传统堆栈的机器上很难实现,当它的返回值直接传入另一个函数时会带来问题,因为它的分配在栈上:
如 fgets(alloca(100), 100, stdin)。
内存泄露的主要可见症状就是罪魁进程的速度会减慢,原因是体积大的进程更有可能被系统换出,让别的进程运行,而且大的进程换进换出时花费的时间也更多。
观察内存泄露是一个两步骤的过程:
首先:使用swap命令检测还有多少可用的交换空间:
/usr/sbin/swap -s
如果发现不断有内存被分配但从来不释放,一个可能的解释就是有个进程出现了内存泄露。
然后:确定可疑的进程,看看它是不是该为内存 泄露负责:使用
ps -lu 用户名
来显示所有进程的大小:
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
5 S 998 2542 2437 0 80 0 - 23056 ? ? 00:00:00 sshd
0 S 998 2543 2542 0 80 0 - 6985 wait pts/3 00:00:00 bash
5 S 998 2775 2665 0 80 0 - 23056 poll_s ? 00:00:00 sshd
0 S 998 2779 2775 0 80 0 - 6985 wait pts/5 00:00:00 bash
0 R 998 22378 2543 0 80 0 - 4576 - pts/3 00:00:00 ps
标题为SZ的列就是以页面数表示的进程的大小。
8、总线错误
事实上,总线错误几乎都是由于未对齐的读或写引起的;它之所以成为总线错误,是因为 出现未对齐的内存访问请求时,被堵塞的组件就是地址总线;
对齐的意思就是数据项只能存放在地址是数据项大小的整数倍的内存位置上。

9、段错误
段错误或者段违规:在Sun的硬件中,是由于内存管理单元的异常所致,该异常则通常是由于解除引用一个未初始化或非法值的指针引起的。如果指针引用一个并不位于你的地址空间中的地址,操作系统便会对此进行干涉。
注:
(1)一个微妙之处是,导致指针具有非法的值通常是由于不同的编程错误所引起的,和总线错误不同,段错误更像是一个间接的症状而不是引起错误的原因。
(2)一个更糟糕的微妙之处是,如果未初始化的指针恰好具有未对齐的值,对于指针所要访问的数据而言,它将产生总线错误,而不是段错误,对于绝大多数计算机而言确实如此,因为CPU先看到地址,然后再把它发送给MMU。
通常导致段错误的几个原因:
(1)解引用一个包含非法值的指针,例如解引用未经过初始化的指针
(2)解引用一个空指针,即NULL指针
(3)在未得到正确的权限时进行访问,例如试图向一个只读文件中写入数据
(4)用完了堆栈或者堆空间,这个比较极端
总线错误意味着CPU对进程引用内存的一些做法不满,而段错误则是对MMU对进程引用内存的一些错误发出的抱怨。
已发生频率为序,最终可能导致段错误的常见编程错误是:
1、坏指针错误:一是在指针赋值之前就用它来引用内存,二是向库函数传送一个坏指针(可能会显示系统程序中出现错误,但是并不是系统程序引起了错误,而是你的程序的问题);三是对指针进行释放之后在访问它的内容,解决办法是在释放指针之后在将他置为空值,free(p);p=NULL;
2、改写overwrite错误:越过数组边界写入数据,在动态分配的内存两端之外写入数据,或改写一些堆管理数据结构;在动态分配的内存之前的区域写入数据就很容易发生这种情况的错误:p=malloc(256);p[-1]=0;p[256]=0;
3、指针释放引起的错误:释放同一个内存块两次,或释放一块未曾使用的malloc分配的内存,或释放仍在使用中的内存,或释放一个无效的指针。
例子:释放链表中元素的错误方法:
struct node*p,*start
for(p=start;p;p=p->next)
free(p);//这里释放了p,但是下一次迭代时,就会对已经释放的指针进行解除引用操作,从而导致不可预料的结果。
正确的方法:
struct node* p,*start,*tmp;
for(p=start;p;p=tmp)
{
tmp=p->next;
free(p);
p=NULL;
}
*****************************************************************************************************************************************************************************************
2013年4月25日更新
*****************************************************************************************************************************************************************************************
第八章 为什么程序员分不清万圣节和圣诞节
一、数据类型的转变
1、当操作符的操作数类型不一致时会发生类型转换,它负责把两个不同的操作数类型转换成为同一种普通类型,转换后的类型一般也就是结果类型;
在表达式中,每个char和short都被转换为int;而float都被转换为double;
这种称为类型提升:
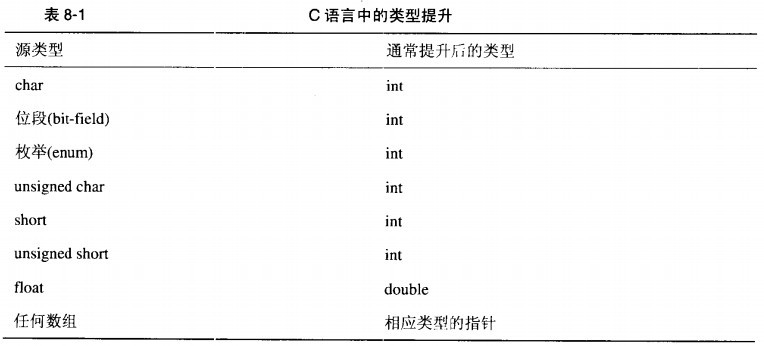
前提是int型能够完整的容纳原先的数据,否则将被转换为unsigned int;
注:另一个会发生隐式类型转换的地方就是参数传递,如果使用了适当的函数原型,类型提升就不会发生,否则就会发生,在被调用函数的内部,提升后的参数被裁减为原先声明的大小。这就是为什么单个的printf()格式串%d适用于几个不同的类型,short、char、int等,无论实际传递的是哪一个类型,函数从堆栈中取出的参数总是int型,并在printf或其他被调用函数里按统一的格式处理,如果使用printf来打印比int长的类型,就无法取得正确的值:即如果传递的参数时long long int型,打印格式是%d,那么就会截取低32位进行打印,如果低32位大于int型最大值,就会打印错误。
隐式类型转换的注意点:
1)隐式类型转换时语言中的一种临机手段,起源于简化最初的编译器的想法;把所有的操作数换为统一的长度,极大的简化了代码的生成;这样,压到堆栈中的参数都是统一长度的,所以运行时系统只需要知道参数的数目,而不需要知道他们的长度。
2)即使不理睬缺省的类型转换,也可以用c语言进行大量的编程工作。
3)隐式类型转换在涉及原型的上下文中显的非常重要。
2、原型之痛
(1)建立原型就是为了消除一种普通的错误,即形参和实参之间类型不匹配。ANSI C的函数原型就是采用了一种新的函数声明形式,把参数的类型包含在声明之中,函数的定义也作了相应的改变以匹配声明;这样,编译器就可以在函数的声明和使用之间进行检查。

(2)在K&RC中,没有函数原型,那就会发生缺省提升;参数类型的自动提升是为了简化编译器,所有的东西都使用同一长度,这样可以简化参数的传递;然后在被调用函数的函数体内,这些值会根据函数定义时参数的声明类型自动裁减为该类型。
例子:
char arr[5] = {'a','b','c','d','e'};
printf("%d",arr[4]);
在printf()中,会发生隐式类型转换,尽管传递的参数类型是char型,但是会被提升为int型,函数从堆栈中取出的参数时int型,然后传递给printf()函数,在printf()函数内部,提升后的int型参数被裁减为原先声明的char型。
(3)在ANSI C中使用了函数原型,类型提升便不会发生,否则便会发生;
(4)原型在什么地方会失败:
K&RC的原型声明和函数定义 如果和 ANSI C的原型声明和函数定义交叉使用,就会失败;
因为K&RC的参数传递时会发生参数类型提升,而ANSI C的参数由于有原型声明,不会发生类型提升;
例如:
如果一个K&RC函数定义增加函数原型,而原型的参数列表中有一个short参数,在参数传递时,这个原型将导致实际传递给函数的就是short类型的参数,而根据函数定义,它期望接收的是一个int型参数,这样,函数从堆栈中抓取4个字节(int型)而不是2个字节(short)型,如此一来,与short型参数靠在一起的那2个字节便成为垃圾数据的制造者;
在实际编程中,把函数原型声明放置在头文件中,而函数的定义则放置在另一个包含了该头文件的源文件中来防止这种情况的发生,编译器能够同时发现他们,如有不匹配就能检测到。
每次在使用系统调用ioctl()之后,检查一下全局变量errno是一种好的方法,它隶属于ANSI C标准
3、复杂的类型转换可以按照以下3个步骤编写:
(1)一个对象的声明,它的类型就是想要转换的结果类型。
(2)删去标识符(以及任何如extern之类的存储限定符),并把剩余的内容放在一对括号里。
(3)把第2步产生的内容放在需要进行类型转换的对象的左边。
*****************************************************************************************************************************************************************************************
2013年5月2日更新
*****************************************************************************************************************************************************************************************
第九章 再论数组
一、什么时候数组和指针相同
1、声明本身可以分成3种情况:
(1)外部数组的声明
(2)数组的定义,定义是声明的一种特殊情况,定义为变量分配内存空间,并可能为变量提供一个初始值,其他的声明仅仅是指明变量的类型和变量的名字以及变量的链接形式
(3)函数参数的声明
注意:
(1)所有作为函数参数的数组名总是可以通过编译器转换为指针
(2)在其他所有声明情况下,数组的声明就是数组,指针的声明就是指针,两者不可以混淆,即你既不能将一个数组变量声明为指针变量,也不能将指针变量声明为数组变量;
典型的错误就是:在一个文件中定义某个数组,在另一个文件中将该数组声明为指针变量;
(3)在使用数组时,数组总是可以写成指针的形式,两者可以互换;
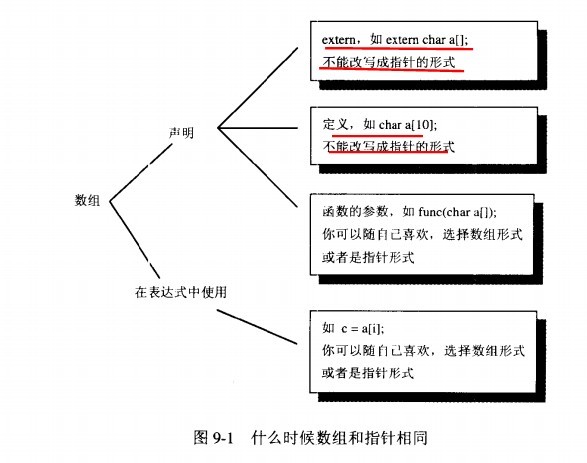
为什么数组的声明就是数组,指针的声明就是指针变量呢?
因为数组和指针在编译器处理时是不同的,在运行时的表示形式也是不一样,并可能产生不同的代码;
具体来说,对编译器而言,一个数组就是一个地址,一个指针就是一个地址的地址;
每个符号的地址在编译时可知,即编译器符号表将每个符号的地址存储起来;
(1)对于基本类型的变量,例如,int a;char ch;long int b;unsigned int c、、、等,在符号表中存放的实际是这些变量的地址,即&a,&ch,&b,&c,所以在引用这些变量时,直接从这些地址中取出变量即可;
(2)对于数组int a[100]来说,编译器符号表中存放的就是数组a[100]所有单元的地址(即:&a[0],&a[1],&a[2],&a[3],、、、、、),因为对于数组来说,无论是否进行初始化,编译器总会为它分配空间,而且这些空间是连续的,这就意味着,编译器会在符号表中保存每一个数组成员的地址,这些地址当然也是连续的,对于a[i]来说,其实是*(a+i),分为两步,第一步是求a+i,而a是什么呢,数组名,即数组首地址,写的明白一点,数组首元素的地址应该是 &a[0] = &(*(a + 0))= &(*a) = a,&和*在这里一个是取地址,一个是解引用,互为逆运算,相互抵消,结果即为a,那么a其实是&a[0],这一点清楚了,因为编译器为数组已经分配好内存空间,即在符号表中保存了这些空间的地址,那么&a[0]代表的地址也保存在符号表中,即a代表的地址也在符号表中,那么a+i经过编译器换算,其实得到的是&a[i],这就相当于在编译器符号表中直接根据偏移得到该变量的地址;第二步是求*(&a[i]),直接取地址中的值,记得到a[i];
(3)对于指针char *p来说,编译器符号表中存放的实际是指针变量p的地址&p,注意,编译器只为p指向的字符的地址存放假设*p = “abcdefgh”,如果我们要引用这个字符p[i],需要经过三步,第一步,取地址&p中的内容,得到字符的存放地址p;第二步,根据偏移量i,得到相应的偏移地址p+i;第三步,根据上一步的偏移地址得到地址中的内容
为什么不能讲char a[100]声明为extern char *a?
因为数组变量a和指针变量a在编译器符号表中保存的方式不同,所以当你采用指针方式引用数组时,就会发生将&a[0]误当成&a,显然 这是错误的,&a[0]是char* ,而&a是char**,类型就不匹配,从解引用过程来看也是错误的;
*****************************************************************************************************************************************************************************************
2013年5月3日更新
*****************************************************************************************************************************************************************************************
第九章 再论数组
1、数组和指针为什么会发生混淆
(1)数组和指针什么时候相等?
作为函数定义的形式参数,char s[]和char *s是一样的,数组表达式总是可以改写成带偏移量的指针表达式------------K&RC
规则一:表达式中的数组名(与声明不同)被编译器当做一个指向该数组第一个元素的指针。
Int a[10];&a[0] = &(*(a+0)) = &(*a)=a
规则二:下标总是与指针的偏移量相同
规则三:在函数参数的声明中,数组名被编译器当做指向该数组第一个元素的指针。
规则一和规则二合在一起理解,就是对数组下标的引用总是可以写成“一个指向数组的起始地址的指针加上偏移量”
例外:
当是下列情况下,对数组的引用不能用指向该数组第一个元素的指针来代替,应该把整个数组作为一个整体来考虑:
(1) 数组作为sizeof()的操作数---显然此时需要的是整个数组的大小,而不是指针所指向第一个元素的大小
(2) 使用&操作符取数组的地址
(3) 数组是一个字符串常量初始值。
规则一:
1)对数组的引用如a[i]在编译时总是被编译器改写成*(a+i)的形式,你只要记住:在表达式中,指针和数组是可以互换的,因为它们在编译器里的最终形式都是指针,并且都可以进行取下标操作;就像加法一样,取下标操作符的操作数是可以交换的,编译器并不在意操作数的先后顺序,就像加法运算中3+5和5+3都是一样的,对应到下标引用中,就是:
a[6]和6[a]这两种形式都是一样的,都是表示*(a+6);
注意:在表达式中,指针变量可以进行自增运算,但是数组名却不能进行自增运算
2)编译器自动会把下标值的步长调整到数组元素的大小;对起始地址执行加法操作之前,编译器会负责计算每次增加的步长,这就是为什么指针总是有类型限制,每个指针通常只能指向一种类型的原因所在-----------因为编译器需要知道对指针进行解除引用操作时应该取几个字节,以及每个下标的步长应取几个字节。
规则二:
在运行时增加对C语言下标的范围检查是不切实际的,因为取下标操作只是表示将要访问该数组,但并不一定要访问,例如,int a[6];while(0){b = a[7];}尽管a[7]是非法的,但是永远不可能访问;而且,程序员完全可以使用指针来访问数组,从而绕过下标操作符。
一维数组和指针引用产生的代码并不具有显著的差别;因为数组下标是定义在指针的基础上,优化器常常可以将它转换为更有效率的指针表达式形式,并生成相同的机器指令;即编译器将数组下标作为指针的偏移量。
C语言把数组下标改写成指针偏移量的根本原因是指针和偏移量是底层硬件所使用的基本类型。
规则三:
C标准规定:作为“作为某种类型的数组”的形参的声明应该调整为“某种类型的指针”;在函数形参定义这个情况下,编译器必须把数组形式改写成指向数组第一个元素的指针形式。编译器只向函数传递数组的地址,而不是整个数组的拷贝。
2、为什么C语言把数组形参当做指针?
之所以要把传递给函数的数组形参转换为指针是出于效率的考虑;
(1) 在C语言中,所有非数组形式的数据实参均以传值形式调用:对实参做一份拷贝并传递给调用的函数,函数不能修改作为实参的值,而只能修改传递给它的那份拷贝;
传值调用对于传递整个数组,无论是时间上还是空间上的开销都是非常大的。
如果所有的数组在作为参数传递时都转换为传递指向数组其实地址的指针,而其他的参数均采用传值调用,就可以简化编译器;同样,函数的返回值绝对不能是一个函数数组,而只能是指向数组或函数的指针。
(2) 数据也可以使用传值调用,只要在它前面加上取地址符&,这样你只拥有一个指向变量的指针而不是变量本身。
(3) C语言允许程序员把形参声明为数组(程序员打算传递给函数的东西)或者指针(函数实际所接收到的东西)
(4) 数组/指针实参的一般用法

(5) 没有办法把数组本身传递给一个函数,因为它总是被自动转换为指向数组的指针,当然,在函数内部使用指针,所能进行的对数组的操作几乎跟传递原原本本的数组没有差别,只不过,如果想用sizeof(实参)来获得数组的长度,所得到的的结果不正确而已,因为你毕竟使用的是一个纯粹的指针变量,而不是数组名。
到底是sizeof(实参)还是sizeof(形参)无法获得原始数组的长度?
我感觉应该是sizeof(形参)无法获得,因为尽管形参值和实参值相等,都是数组第一个元素的地址,但是&(实参)=数组的首地址=数组第一个元素的地址,但是&(形参)= 不定?,说到底,实参是与实际数组对应,
(6) 总之,在声明一个函数时,可以把形参定义为数组,也可以定义成指针,不论你选择什么,编译器都会注意到该对象是一个函数参数的特殊情况,它会产生代码对该指针进行解除引用操作。
(7) 如果你想让代码看上去清楚,就必须遵循一定的规则;我们始终倾向于把参数定义为指针,因为这是编译器内部所使用的形式,即使你把参数定义为数组,编译器也会把数组转换为指针;

3、数组片段的下标
可以通过向函数传递一个指向数组第一个元素的指针来访问整个数组,但也可以让指针指向数组中的任意其他一个元素,这样传递给函数的就是从该元素之后的数组片段(我的疑问是难道该元素之前的数组片段不能访问吗,因为数组的地址是连续的啊,我回去要编程试一下)。
4、数组和指针可交换性的总结
(1)用a[i]这样的形式对数组进行访问总是被编译器解释为像*(a+i)这样的指针访问
(2)指针始终是指针,它绝不可以改写成数组。你可以用下标形式访问指针,但这种情况一般是指针作为函数参数时,而且实际传递给函数的是一个数组。
(3)在特定的上下文中,也就是一个数组作为函数的参数时(而且只有这种情况),此数组的声明被看做是一个指针。作为函数参数的数组(在此函数调用中)始终会被编译器修改成为指向数组第一个元素的指针。
(4)因此,当一个数组定义为函数的参数时,可以选择把它定义为数组,也可以定义为指针;但不管选择那种方法,在函数内部事实上获得的都是一个指针变量。
(5)在其他所有情况中,定义和声明必须匹配,如果定义了一个数组,在其他文件进行声明时,也必须把它声明为数组,如果定义了一个指针,在其他文件对它进行声明时,也必须把它声明为指针。
5、C语言中没有多维数组的概念,只有数组的数组。
在C语言中,可以这样声明一个数组:
char carrot[10][20];
或者声明一种看上去更像“数组的数组”形式
typedef char vegetable[20];
vegetable carrot[10];
不论哪种情况,访问单个字符都是通过carrot[i][j]的形式,编译器在编译时会把它解析为
*(*(carrot +i)+j)的形式。
例如:
int apricot[2][3][5];
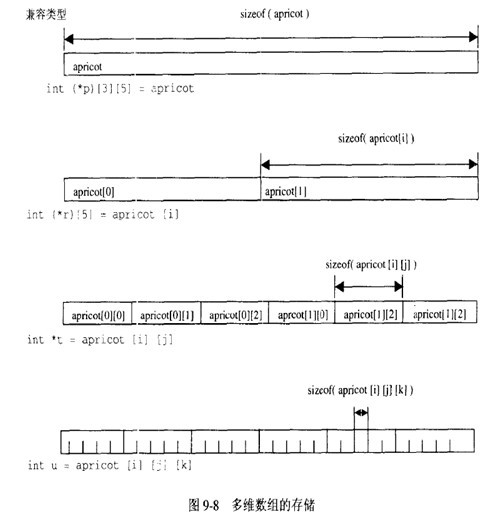
正常情况下,赋值发生在两个相同类型之间,如int与int ,double与double等,在上图中,数组的数组的数组中的每一个单独的数组都可以看做是一个指针,这是因为在表达式中的数组名被编译器当作指向数组第一个元素的指针;换句话说,不能把一个数组赋值给另一个数组,因为数组作为一个整体不能成为赋值的对象;但是可以把数组名赋值给一个指针,就是因为这个“在表达式中数组名被编译器当作一个指针”的规则。
指针所指向的数组的维数不同,其区别很大,步长不同。
6、内存中数组是如何布局的
在C语言中,数组最右边的下标是最先变化的。
如果数组的长度比所提供的初始化值的个数要多,剩余的几个元素会自动设置为0,如果元素的类型是指针,那么它们会被初始化为NULL,如果元素的类型是float,那么它们会被初始化为0.0,什么叫位模式?
(1) 只有字符串常量才可以初始化为指针数组,指针数组不能由非字符串的类型直接初始化。
int *a[]={
{1,2,3},
{6,7}
{8,9}
}
上面这种初始化就是错误的,无法正确编译。
(2)

(3) 数组参数的地址和数组参数的第一个元素的地址竟然不一样,解释一下:
例如
void pointer(int *pt)
int ptr[]={12,38,3,23,23,23,12,45,565,}
pointer(ptr);
在上述指针变量的传递中,实参ptr传递给函数的形参pt,尽管此时pt=ptr,但是pt是形参,和ptr不是同一个变量,所以pt的地址和ptr的地址不同
&ptr是整个数组的起始地址,它和数组第一个元素的地址相同,&pt是数组参数的地址,它是一个新的变量,此变量的地址当然不会与数组第一个元素的地址相同,毕竟一个地址只能存放一个变量。

第十章再论指针
1、 一个数组的查询:
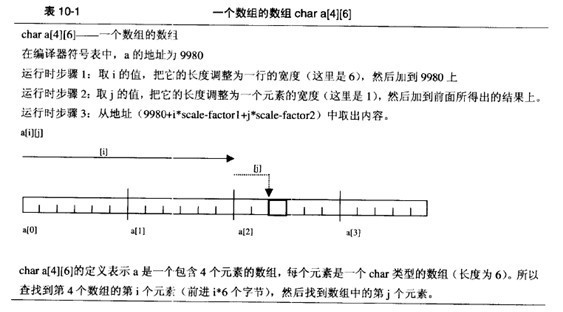
2、 字符串指针数组:
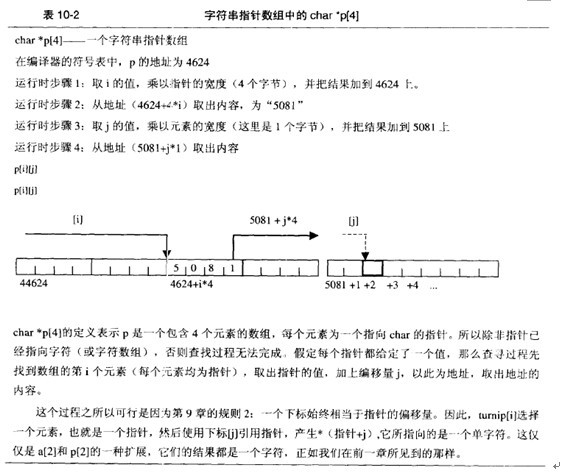
为什么char(*p)[4] char pt[5][4]可以:p = pt?而char*p[4]与char pt[5][4]不能p = pt?
因为char(*p)[4]实际上应该写成(char[4]) *p的形式比较合适,表示指向4个char型宽度的变量的指针,即p++每次地址都会加4,就是因为p指向的4个char型宽度的变量,这就好比int *a,a++每次地址都会增加4个字节,因为int型变量占四个字节;
而char pt[5][4]既可以看成char[4] pt[5],这样该数组就是明显的数组的数组,在pt[5]中每一个变量都是char[4]型变量;也可以看成 char pt[5] [4],这样pt就是char[5][4]型指针变量;因此,要么将指针变量pt赋给一个指向char[4]数据的指针,要么将pt赋给一个指向char[5][4]型数据的指针,前者就是将pt赋给一个行指针,后者就是将pt赋给相同类型的数组。
将char[4]定义为新类型Char,则char(*p)[4]可以写成 Char *p,char pt[5][4]可以写成Char pt[5],则数组名pt代表数组的首地址,指针p指向的对比一维数组首地址赋给指针变量可以知道,当然p = pt;
对于char *p[4]来说,它是一个指针数组,该数组的每一个指针变量都是指向char型,这与char pt[5][4]的数组名pt不是同类型的指针变量,因此不能相互赋值。
char pt[5][4]的数组名pt的真正含义是:
pt = &(*(pt+0))=&(pt[0])=&pt[0],所谓的二维数组名实际的意义是:第一行的首地址,则pt+1 = &(*(pt+1))=&pt[1],显然pt 的步长实际就是行长度,即列数,所以pt的数据类型就是指向char[4]的指针变量,则只能讲pt赋给一个行指针,即赋给一个指向char[4]的指针。
这样从指针的含义上来看,很显然,将二维数组名 代表的指针变量赋值给行指针的原因了。3、 存储长度不一的数据,使用单纯的数组可能会浪费空间,解决办法之一就是使用指针数组。
例如使用字符指针数组指向若干个字符串,系统会为这些字符串分配存储空间,且不会浪费空间,这样会大大节省空间。
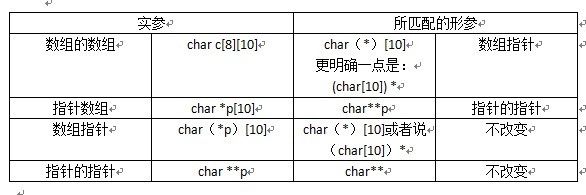
4、 数组和指针参数是如何被编译器修改的
数组名被修改成一个指针参数,这个规则仅仅是一维数组的规则,这个一定要记住,我能记住么,我想肯定能。
数组的数组会被改写成数组的指针,而不是指针的指针。
当数组的数组作为实参时,形参被改写成数组指针;
指针数组作为实参时,形参被改写成指针的指针
数组指针(行指针)作为实参时,形参不改变
指针的指针作为实参时,形参不改变。
上面举例为:
5、在C语言中,没有办法向函数传递一个普通的多维数组

(1)一维数组的传递
在C语言中,任何一维数组均可以作为函数的实参,形参被改写为指向数组第一个元素的指针,所以需要一个约定来提示数组的长度。一般有两个基本办法:
l 增加一个额外的参数,表示元素的个数,argc就是起这个作用的
l 赋予数组最后一个元素一个特殊的值,提示它是数组的尾部,字符串结束符’\0’字符就是起这个作用的,这个特殊字符必须不会作为正常的元素值在数组中出现。
(2)二维数组的传递
二维数组的情况要复杂一些,二维数组在作为函数实参时,数组被改写为指向数组第一行的指针。现在需要两个约定:其中一个用于提示每行的结束,另一个用于提示所有行的结束。
提示单行结束可以使用一维数组所用的两种方法;
提示所有行结束也可以这样:提示所有行结束的方式可以增加一个额外的行,行内所有元素的值都是不可能在数组正常元素中出现,能够提示数组超出了范围,当对指针进行自增操作时,要对它进行检查,看看它是否到达了那一行;或者是,定义一个额外的参数,提示数组的行数。
(3)多维数组的传递:但是多维数组包括二维数组,必须指定除了第一维之外所有维数的长度;
举例,以二维数组传递为例
有以下方式:
方法一:
my_function(int my_arr[10][20])
这种方法是最简单的方法,但同时作用最小,因为它迫使函数只能处理10行20列的int型数组。
方法二:
my_function(int my_arr[][20])
合法的省略第一维的长度,但是每一行都必须正好是20个整数的长度;
方法三:
my_function(int (*my_arr)[20])
这种方法和上面的方法相似,必须保证每一行的长度正好是20个整数。
方法四:
my_function(char **my_arr)
注意:只有把二维数组改为一个指向向量的指针数组的前提下才可以这么做,即将
char arr[10][20]改为: char *arr[10]
这种方式允许任意的字符串指针数组传递给函数,但必须是指针数组,而且必须是指向字符串的指针数组,这是因为字符串和指针都有一个显式的越界值,分别为NUL和NULL,可以作为标记,至于其他类型,并没有一个类似的通用的且可靠的值,所以并没有一种内置的方法知道何时到达数组某一维的结束位置,即使是指向字符串的指针数组,通常也需要一个计数参数argc,记录字符串的数量,这是因为,你只是把指向第一个字符串的指针传递给函数,如果想要判断字符串的结束,只能传递字符串的个数。
方法五:
放弃多维数组的形式;就是将二维数组表示成一维数组,因为即使是二维数组表示成一维数组,在内存中的排列并不会改变。
1、 如果多维数组的长度都是固定值,把它传递给一个函数毫无问题,但是如果作为函数的参数的数组的长度是任意的:
(1) 一维数组:需要包括一个计数值或者是一个能够标识越界位置的结束符;如果被调用的函数无法检测数组参数的边界,例如,gest()函数存在安全漏洞,从而导致因特网蠕虫的产生
(2) 二维数组:不能直接传递给函数,但是可以把二维数组改写成数组指针,并用相同的下标表示方法;对于字符串,这样做可以,因为字符串有字符串结束符,对于其他类型,需要增加一个计数值或者能够标识越界位置的结束符;同样,它依赖于调用函数和被调用函数之间的约定
(3) 三维或多维数组,都无法使用,必须把它分解为几个维数或者更少的数组。
2、 使用指针从函数返回一个数组
严格说来,无法直接从函数返回一个数组,但是可以让函数返回一个指向任何数据结构的指针,当然也可以是一个指向数组的指针。
在返回指向数组的指针时,数组必须是不能用完后收回,或者是函数内部的动态分配的存储空间或者是全局变量或者是静态全局变量。
不能从函数中返回一个指向函数的局部变量的指针;以为局部变量在使用过后就会收回,返回的指针指向的内存就会变成未知的内存。
char*p = NULL;
printf(”%s”,p);出现错误
%s说明符的参数必须是一个指向字符数组的指针,由于NULL并不是一个这样的指针,所以这个调用将陷入未定义行为。
3、 使用指针创建和使用动态数组
(1)ANSI C中,数组是静态的--------------数组的长度在编译时便已确定不变,即不能使用变量作为数组定义时的长度,即使是恒定变量:
const int n = 5;
int arr[n];
这是错误的,期待整形常量表达式,即数组的长度只能是整形常量表达式。
(2)实现动态数组
基本思路就是:使用malloc()库函数得到一个指向一块内存的指针,然后像引用数组一样引用这块内存,机理就是一个数组下标访问可以改写为一个指针加上偏移量。
(4) 使用库函数realloc(),它能够对一个现在的内存块大小进行重新分配,同时不会丢失原先内存块的内容,当需要在动态表中增长一个项目时:
l 对表进行检查,判断表是否已满
l 如果确实已满,使用relloc()扩展,注意:要判断realloc()函数是否分配成功,不然,如果直接将realloc()函数分配的空间赋值给原先的表指针,可能是表指针指向NULL
l 在表中增加所需要的项目。
(5) 动态分配内存的方式:

第十一章 你懂的C,C++不在话下
面向对象编程的特点是继承和动态绑定;C++通过类的派生支持继承,通过虚拟函数支持动态绑定;虚拟函数提供一种封装类体系实现细节的方法。
一、面向对象编程的关键概念
1、 抽象:去除对象中不重要的细节,只保留描述对象中本质特征的关键点。
2、 类:类是一种用户定义类型,就好像int这样的系统定义的类型,具有一套完善的针对他的的操作;类机制也必须允许程序员规定他所定义的类能够进行的操作;类里面的任何东西都被称为类的成员;
3、 封装:把类型、数据和函数组合在一起,组成一个类;
4、 继承:允许类从一个简单的基类中接收数据结构和函数。派生类获得基类的数据和操作,并可以根据需要对它们进行改写,也可以在派生类中增加新的数据和函数成员。
二、
1、抽象建立了一种抽象数据类型,C++使用类这个特性来实现它,它提供了一种自上而下、观察数据类型属性的方法来看待封装:把用户定义类型中的各种数据和方法组合在一起;它同时也提供了一种自底向上的观点来看待封装:把各种数据和方法组合在一起实现一种用户定义类型。
2、封装:当你把抽象数据类型和它们的操作捆绑在一起的时候,就是在进行封装。
3、类就是封装的软件实现,类也是一种类型,就像char、int、double、struct rec*都是类型一样,因此,你必须声明该类的变量以便进行有用的工作。
类和类型一样,可以取得它的大小或声明它的变量等;
对象和变量一样,可以对它进行很多操作,如取得它的地址、把它作为参数传递、把它作为函数的返回值、使它成为常量值等。一个对象(一个类的变量)可以像声明其他任何变量一样被声明:
Vegetable carrot;
这里vegetable是一个类的名字,而carrot是该类的一个对象,类的名字以大写字母开头是一个好习惯。
C++类允许用户定义类型:
把用户定义类型和施加在
*****************************************************************************************************************************************************************************************
2013年5月4\5日更新
*****************************************************************************************************************************************************************************************















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









