







深度学习的基本网络架构:
1、LeNet
结构设计:
layer 1: 卷积层 6x6x5
layer 1.5: 下采样层 2x2
layer 2: 卷积层 5x5x16
layer 2.5: 下采样层 2x2
layer 3: 全连接层 120
layer 4: 全连接层 84
layer 5: soft-max 输出10个类别
之后的发展趋势就是在基本的网络结构的基础上:堆叠的卷积层(contrast normalization和池化)后加若干层全连接层,增加网络的层数以及网络的大小,为了避免过拟合,采用dropout等方法【1】。
池化的优点: 降低参数维度,减少计算量并提高训练速度;一定程度提高了模型的旋转、平移等不变性,减少了过拟合。另外:max-pooling具有降低卷积层参数误差造成的均值增大的问题,保留纹理信息,mean-pooling则可以降低邻域大小受限造成的方差增大的问题,保留背景信息。
contrast normalization:一种normalization方法,在HoG中有所应用。
为什么大家倾向于一种更深及更大的网络呢??一般来说,神经网络类似于一种多神经元的自动组合的函数。更深及更大的网络会具有更多的结点数目,从而提高整个模型的表达能力,虽然一定程度会导致过拟合。但是一般深度学习都倾向于一个huge的数据集,从而目标是拟合整个世界=。=也就不是很care过拟合的问题-。-
稀疏:由于层数的增加会导致运算量的迅速增加,而稀疏的参数则会减少运算量,这就是为什么倾向于得到稀疏的参数的原因。另外,稀疏的参数在一定程度上保证模型的结构代价最小化。
Convolution:convolutions are implemented as collections of dense connections to the patches in the earlier layer【1】.
convolutional layer 描述了图像的 local feature (局部特征),而最后的几层(倒数第二、第三层) fully connected layer,描述了图像的 global feature (全局特征)。
2、AlexNet
较LeNet而言,AlexNet使用了五层卷积神网络和三个全连接层。 同时,为了提高运行速度,这个网络被设计成了一个2-GPU并行结构。
提出了ReLU作为激活函数,由于ReLU是一个非饱和非线性函数可以获得较饱和非线性函数更快的收敛性能(Sigmoid,tanh等),不需要对输入规范化以避免出现饱和的问题。而且,ReLU在一定程度上提高了模型的稀疏性。
提出了Local Response Normalization,计算公式如下
bix,y=aix,y/(k+α∑min(N−1,i+n/2)j=max(0,i−n/2(ax,y)2)β ,其中n表示相邻卷积核的搜索范围。
提出了重叠池化的trick。
在数据预处理部分,采用了PCA;模型训练过程中,采用了dropout。
3、VGGNet
VGGNet训练了若干个网络,从VGG-11,VGG-13到VGG-16,VGG-19。不同于AlexNet或其他卷积神经网络,在VGGNet中,没有使用较大的卷积核,而是只使用了3x3的卷积核。并利用若干个3x3卷积核来实现较大的卷积核的作用,这里不仅增加了网络深度而且降低了网络参数。此外,该网络中还采用了1x1的卷积核,这种卷积核可以提高网络的深度但是不对输入尺寸造成影响,另外,可以视为对输入的一个线性映射。
4、GoogleNet
googleNet中采用了一个很赞的网络层叫做Inception Layer,这种结构是基于Network-in-Network的结构提出,目标是为了充分利用现有的元素得到一个稀疏的卷积神经网络。增加Inception Layer 一定意义上增加了每一层的单元数量,但是并没有带来巨大的运算量代价。一定程度上也提高了运算速度。

由于低维的embedding也可能含有大量的相关信息,但是这种embedding represent information需要是dense,compressed依旧难以计算,所以GoogleNet增加了一个1x1的卷积层计算reductions,同时这一步也使用了ReLU激活函数使其dual-purpose。
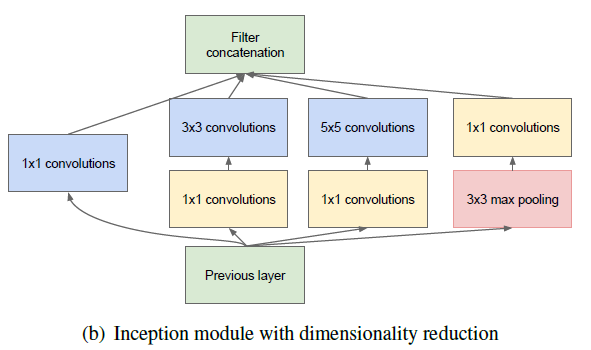
GoogleNet的整体结构由两层卷积层(带pooling),Inception(3a-3b),Inception(4a-4e),Inception(5a-5b)以及一个avg pooling和一个linear layer构成。这里在卷积层之后使用了一个avg pooling,虽然最后依旧加了一个全连接层,论文中表示这一个全连接层增加的目的是为了便于向标签数据对齐。在avg池化之后采用了dropout防止过拟合(一般dropout是跟在全连接层上的)。
最后,由于GoogLeNet是一个很深的神经网络,在最后层的输出可能存在如梯度弥散等问题,在该网络中,为了充分利用浅层特征,或者说是中间结果,在4a和4d输出处增加了一个output,用来加权优化整个网络的loss。
5、ResNet
ResNet中认为随着网络深度的增加,准确性的下降不是过拟合造成的,而是由于训练误差的增大。所以增加一个残差网络来直接对残差进行学习,该网络结构的基本设计如下图所示,将输入分成 x 和
shotcut connection不是很新的概念,【2】中表示,在googleNet所提的Inception层中也用到了shortcut connection的概念,shortcut branch 和一组deeper branch的集合。
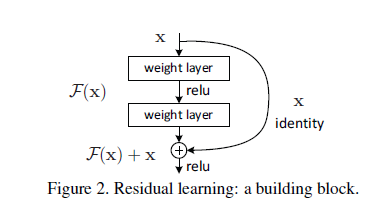
ResNet的整体网络结构类似于VGG-Net,不同之处在于增加了shortcut connection,使部分卷积层变成了残差卷积层。
ResNet中在每一个卷积层和激活函数的中间增加了Batch normalization操作。用来确保前向传播的信号不是零方差的【2】。目的是为了避免gradient vanish现象。
6、Advanced Combined Network and Tricks
【4】的主要贡献在于提出了Batch Normalization方法,该方法在ResNet中也有所使用。在卷积层和激活函数中使用效果极佳。为什么要在这个时候使用呢?主要原因是因为训练初期得到参数不稳定导致在激活函数后使用效果不佳。而且由于初始参数便是基于标准正太分布得到的,做normalization之后,可以得到更稳定的结果。
操作:每一维度减去自身均值,再除以自身标准差,由于使用的是随机梯度下降法,这些均值和方差也只能在当前迭代的batch中计算
在【3】中,表示ResNet中所提的残差层在深度网络训练过程中并不是必须的,但是可以极大的提高收敛速度。
参考文献:
【1】Going Deeper with Convolutions
【2】Deep Residual Learning for Image Recognition
【3】Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
【4】Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift
【5】Rethinking the inception architecture for computer vision















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









