







安装Hadoop:
2.1 配置虚拟机网络:静态ip地址、hostname、hosts (已更新)
2.2 ssh无密码登录各节点 (跟centos8操作一致)
2.3 安装java环境 (已更新)
2.4 hadoop3.2.1集群配置
2.4.0 官网下载hadoop,解压到/usr/local

2.4.1 配置文件
配置文件在这个文件夹里:
具体的配置信息按照需求来写,参考hadoop官网中的Configuration
core-site.xml :分布式文件系统和MapReduce的核心配置文件
hadoop.tmp.dir:hadoop的临时存储目录
fs.defaultFS:分布式文件系统访问的主路径,大数据平台的默认路径
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<!--The name of the default file system.
A URI whose scheme and authority determine the FileSystem implementation.
The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class.
The uri's authority is used to determine the host, port, etc. for a filesystem. -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-master</value>
<!-- A base for other temporary directories -->
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<!-- The user name to filter as, on static web filters while rendering content.
An example use is the HDFS web UI (user to be used for browsing files). -->
</property>
</configuration>
hdfs-site.xml:HDFS文件系统属性配置
dfs.replication:分布式文件系统进行数据块冗余备份时的副本因子,默认是3,一般跟从节点数量一致
dfs.namenode.name.dir:namenode数据存储目录
dfs.namenode.name.dir:datanode数据存储目录
保证路径存在
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
<!-- The address and the base port where the dfs namenode web ui will listen on. -->
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
<!-- The secondary namenode http server address and port. -->
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>master:9000</value>
<!-- RPC address that handles all clients requests.
In the case of HA/Federation where multiple namenodes exist, the name service id is added to the name e.g. dfs.namenode.
rpc-address.ns1 dfs.namenode.rpc-address.EXAMPLENAMESERVICE The value of this property will take the form of nn-host1:rpc-port. The NameNode’s default RPC port is 8020. -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<!-- Determines where on the local filesystem the DFS name node should store the name table(fsimage).
If this is a comma-delimited list of directories then the name table is replicated in all of the directories, for redundancy. -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<!-- Determines where on the local filesystem an DFS data node should store its blocks.
If this is a comma-delimited list of directories, then data will be stored in all named directories, typically on different devices.
The directories should be tagged with corresponding storage types ([SSD]/[DISK]/[ARCHIVE]/[RAM_DISK]) for HDFS storage policies.
The default storage type will be DISK if the directory does not have a storage type tagged explicitly.
Directories that do not exist will be created if local filesystem permission allows. -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<!-- Default block replication. The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time. -->
</property>
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
<!-- If "true", enable permission checking in HDFS.
If "false", permission checking is turned off, but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode, owner or group of files or directories. -->
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/namesecondary</value>
<!-- Determines where on the local filesystem the DFS secondary name node should store the temporary images to merge.
If this is a comma-delimited list of directories then the image is replicated in all of the directories for redundancy. -->
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>${dfs.namenode.checkpoint.dir}</value>
<!-- Determines where on the local filesystem the DFS secondary name node should store the temporary edits to merge.
If this is a comma-delimited list of directories then the edits is replicated in all of the directories for redundancy.
Default value is same as dfs.namenode.checkpoint.dir -->
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
<!-- If true (the default), then the namenode requires that a connecting datanode's address must be resolved to a hostname.
If necessary, a reverse DNS lookup is performed.
All attempts to register a datanode from an unresolvable address are rejected.
It is recommended that this setting be left on to prevent accidental registration of datanodes listed by hostname in the excludes file during a DNS outage.
Only set this to false in environments where there is no infrastructure to support reverse DNS lookup. -->
</property>
</configuration>
mapred-site.xml:
我看大多数的配置都配了 mapreduce.framework.name:yarn 并行计算调度资源由yarn调度控制
我查3.2.1的官方文档时没有这一条,所以我没有配,运行正常
<configuration>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
<!-- MapReduce JobHistory Server IPC host:port -->
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
<!-- MapReduce JobHistory Server Web UI host:port -->
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
<!-- CLASSPATH for MR applications. A comma-separated list of CLASSPATH entries.
If mapreduce.application.framework is set then this must specify the appropriate classpath for that archive, and the name of the archive must be present in the classpath.
If mapreduce.app-submission.cross-platform is false, platform-specific environment vairable expansion syntax would be used to construct the default CLASSPATH entries.
For Linux: $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*.
For Windows: %HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*, %HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*.
If mapreduce.app-submission.cross-platform is true, platform-agnostic default CLASSPATH for MR applications would be used: {{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/*, {{HADOOP_MAPRED_HOME}}/share/hadoop/mapreduce/lib/* Parameter expansion marker will be replaced by NodeManager on container launch based on the underlying OS accordingly. -->
</property>
</configuration>
yarn-site.xml: 配置YARN的相关参数
yarn主进程:resourcemanager
yarn.resourcemanager.hostname:主进程节点的主机名
yarn.nodemanager.aux-services:进行认证服务时的服务
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<!-- The hostname of the RM. -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<!-- A comma separated list of services where service name should only contain a-zA-Z0-9_ and can not start with numbers -->
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tarcker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
<!-- The address of the scheduler interface. -->
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
<!-- The address of the applications manager interface in the RM. -->
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
<!-- The address of the RM admin interface. -->
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
<!-- The http address of the RM web application.
If only a host is provided as the value, the webapp will be served on a random port. -->
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value> 8192</value>
<!-- The maximum allocation for every container request at the RM in MBs.
Memory requests higher than this will throw an InvalidResourceRequestException. -->
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<!-- Whether virtual memory limits will be enforced for containers. -->
</property>
</configuration>
workers:添加从节点主机名
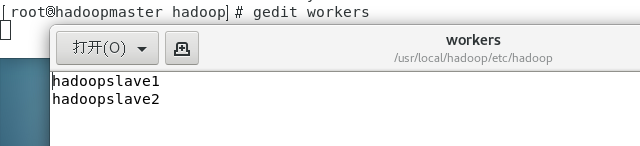
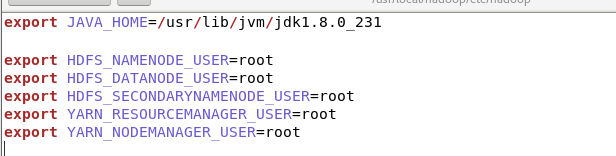
hadoop-env.sh:
因为hadoop本身是由java实现的,hadoop的正常运行依赖于jdk,所以需要在运行环境里配置jdk的路径
2.4.2 将配置文件分发到各从节点
2.4.3 格式化namenode
第一次启动前在master格式化namenode:hdfs namenode -format
只需运行一次
2.4.4 关闭防火墙
启动hadoop前,要关闭防火墙

2.4.5 设置环境变量

2.4.6 启动
start-dfs.sh
start-yarn.sh
启动后,jps可以查看已经启动的程序
主节点:
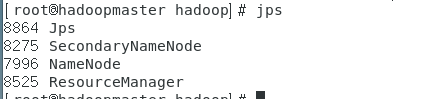
从节点:
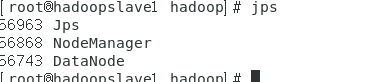
除了第一次启动前在master格式化namenode,其他操作都是要主从机器一样
Web页面访问
http://主机名(或主机IP地址):50070 访问HDFS管理页面
http://主机名(或主机IP地址):8088 访问MR管理页面














 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









