








官网:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
hadoop的特性
可靠性,多副本机制
可扩展
高性能
容错性
简介
运行程序:
MapReduce编程模型—》jar–》yarn—》JVM—》申请计算资源
HDFS:负责大数据存储
核心进程:
NameNode:文件,名称等的元数据信息。文件名,文件大小,切块,创建与修改时间。
接受客户端请求,接受NameNode请求,分配任务
DataNode:文件存储
可选进程:
SecondaryNameNode:辅助NameNode工作
YARN:资源调度
MapReduce规范:
Mapper(简单处理)
Reducer(合并)
打包后成为一个job,提交到yarn运行,Task。
job创建一个进程MRAppMaster
YARN
ResourceManager:集群资源管理
NodeManager:负责单台计算机的资源管理,领取RM任务,为Job中的每个Task分配计算资源
概念:container进行资源隔离,方式其他任务进行资源抢占。
软件要求:
java,ssh,sshd,pdsh也推荐安装
伪分布式环境配置:
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://h1:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
检查ssh命令
ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t rsa -P ‘’ -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
执行
格式化文件系统:
$ bin/hdfs namenode -format
启动NameNode和DataNode:
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
Hadoop安装完后,启动时报Error: JAVA_HOME is not set and could not be found.
解决办法:
修改/etc/hadoop/hadoop-env.sh中设JAVA_HOME。
应当使用绝对路径。
export JAVA_HOME=$JAVA_HOME //错误,不能这么改
export JAVA_HOME=/usr/java/jdk1.8 //正确,应该这么改
vim /etc/profile
加入:
export HADOOP_HOME=/usr/software/hadoop-3.0.1
export PATH=$PATH:$JAVA HOME/bin:$HADOOP HOME/bin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
保存后执行profile,source /etc/profile
浏览NameNode
NameNode -

如果出现无法访问的情况:
CentOS 7.0默认使用的是firewall作为防火墙
查看防火墙状态
firewall-cmd --state
停止firewall
systemctl stop firewalld.service
禁止firewall开机启动
systemctl disable firewalld.service
MapReduce
要使用yarn调度资源
mapreduce.framework.name=yarn
创建MR任务的目录
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/<username>
复制文件:
$ bin/hdfs dfs -mkdir input
$ bin/hdfs dfs -put etc/hadoop/*.xml input
执行:
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
$ bin/hdfs dfs -get output output
$ cat output/*
查看运行结果:
$ bin/hdfs dfs -cat output/*
When you’re done, stop the daemons with:
$ sbin/stop-dfs.sh
配置文件
默认的配置文件:jar包中
HADOOP_HOME/share/xxx.jar/xxx-default.xml
core-default.xml
hdfs-default.xml
mapred-default.xml
yarn-default.xml
自定义: xxx-site.xml
自定义加载配置目录: hadoop --config ./myconf
在sbin目录执行管理脚本
start-dfs.sh
yarn计算的日志聚集功能

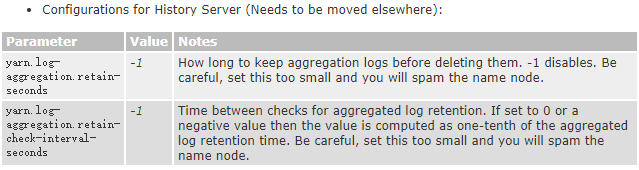
过程错误
- DataNode缺失
NameNode没有:未初始化执行hadoop namenode -format - 无法上传文件: selinux未关闭disable
- mapreduce执行job卡住: 查看Node的配置文件是否配置正确














 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









