









| RabbitMQ系列文章 |
|---|
| 深入RabbitMQ世界:探索3种队列、4种交换机、7大工作模式及常见概念 |
| 不止于纸上谈兵,用代码案例分析如何确保RabbitMQ消息可靠性? |
| 不止于方案,用代码示例讲解RabbitMQ顺序消费 |
| RabbitMQ常见问题持续汇总 |
文章导图
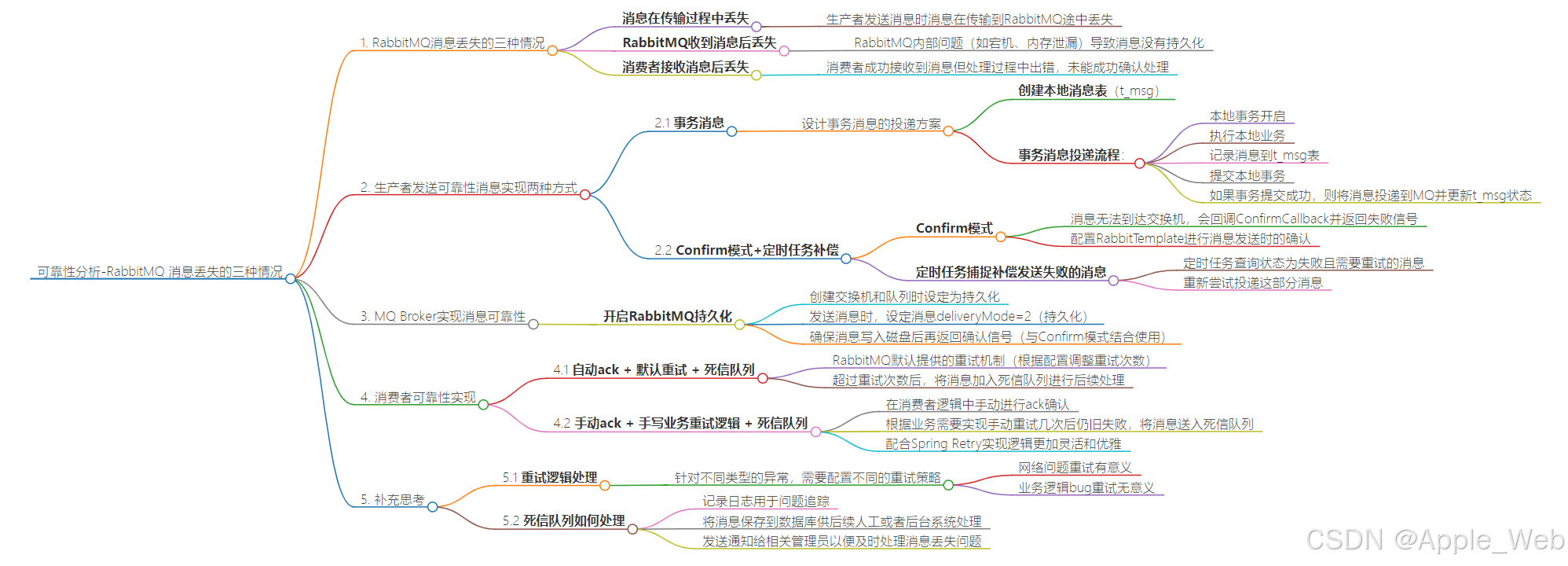
可靠性分析-RabbitMQ 消息丢失的三种情况
关于如何保证消息可靠性,在网上搜索方案解决能搜出很多,但是关于对应的代码却很少有人去实现分析,所以本篇文章,我不止会讨论方案如何实现,还会有对应的代码讲解,让你更好地理解!
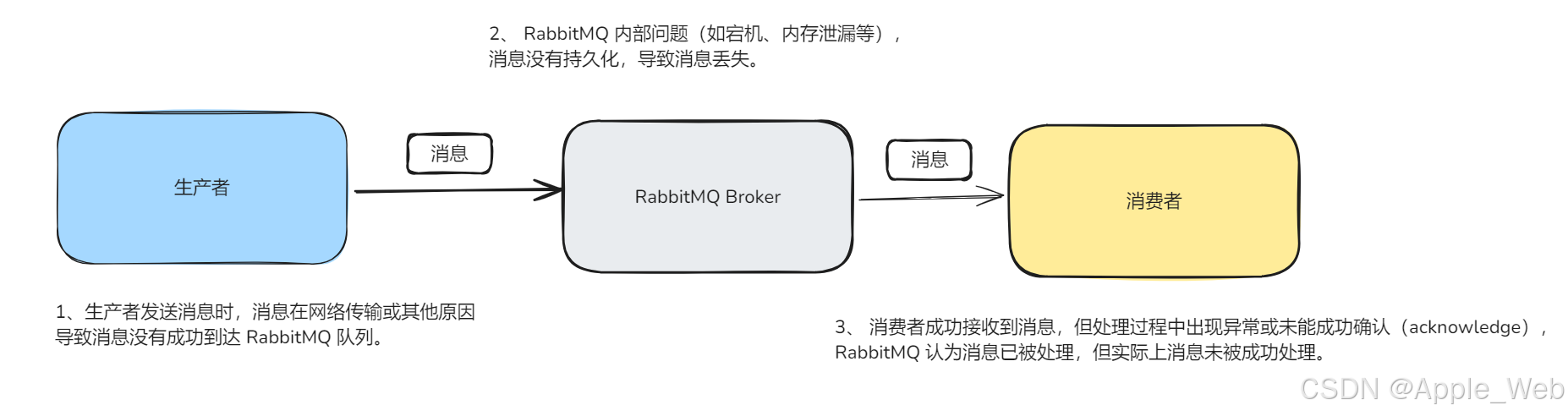
从图中可以看出 RabbitMQ 发送消息时可能发生的三种丢失情况:
- 消息在传输过程中丢失
生产者发送消息时,消息在网络传输或其他原因导致消息没有成功到达 RabbitMQ 队列。 - RabbitMQ 收到消息后丢失
RabbitMQ 收到了消息,但由于 RabbitMQ 内部问题(如宕机、内存泄漏等),消息没有持久化,导致消息丢失。 - 消费者接收消息后丢失
消费者成功接收到消息,但处理过程中出现异常或未能成功确认(acknowledge),RabbitMQ 认为消息已被处理,但实际上消息未被成功处理。
接下来我们就一一分析这三种情况
生产者发送可靠性消息实现2种方式
1、采用事务消息
如果是采用rocketMQ可以直接采用rocketMQ本身实现的事务消息,不需要额外自己实现了!关于事务消息的文章在我的另外一篇文章有专门介绍:
事务消息是投递消息的一种方式,可以确保业务执行成功,消息一定会投递成功。
事务消息投递方案设计
1、本地库创建一个消息表(t_msg)
create table if not exists t_msg
(
id varchar(32) not null primary key comment '消息id',
body_json text not null comment '消息体,json格式',
status smallint not null default 0 comment '消息状态,0:待投递到mq,1:投递成功,2:投递失败',
fail_msg text comment 'status=2 时,记录消息投递失败的原因',
fail_count int not null default 0 comment '已投递失败次数',
send_retry smallint not null default 1 comment '投递MQ失败了,是否还需要重试?1:是,0:否',
next_retry_time datetime comment '投递失败后,下次重试时间',
create_time datetime comment '创建时间',
update_time datetime comment '最近更新时间',
key idx_status (status)
) comment '本地消息表'
2、事务消息投递的过程
- step1:开启本地事务
- step2:执行本地业务
- step3:消息表t_msg写入记录,status为0(待投递到MQ)
- step4:提交本地事务
- step5:若事务提交成功,则投递消息到MQ,然后将t_msg中的status置为1(投递成功);本地事务失败的情况不用考虑,此时消息记录也没有写到db中

知识点拓展:Spring事务同步器
知识点拓展: 如何判断事务是否提交成功呢?这就涉及Spring的事务同步器了
TransactionSynchronizationManager.registerSynchronization 是 Java Spring 框架中的一个方法,它用于注册事务同步处理器(TransactionSynchronization)。事务同步处理器是 Spring 事务管理的一个特性,允许你在事务的边界内执行一些操作,无论是事务提交还是回滚。
具体来说,TransactionSynchronizationManager 负责管理事务同步操作的注册和执行。当你调用 registerSynchronization 方法时,你可以传入一个实现了 TransactionSynchronization 接口的实例。这个实例定义了在事务的不同阶段(如开始、提交、回滚)应该执行哪些操作。
以下是 TransactionSynchronization 接口中定义的一些方法,这些方法可以在事务的不同生命周期点被调用:
beforeCommit(boolean readOnly): 在事务提交之前调用,如果事务是只读的,则readOnly参数为true。beforeCompletion(): 在事务实际提交或回滚之前调用,用于执行清理操作。afterCommit(): 如果事务提交成功,则调用此方法。afterCompletion(int status): 在事务完成后调用,无论事务是提交还是回滚。status参数指示事务的状态:STATUS_COMMITTED表示提交成功,STATUS_ROLLED_BACK表示已回滚。
/**
* 若有事务,则在事务执行完毕之后,进行投递
*
* spring事务扩展点,通过TransactionSynchronizationManager.registerSynchronization添加一个事务同步器TransactionSynchronization,
* 事务执行完成之后,不管事务成功还是失败,都会调用TransactionSynchronization#afterCompletion 方法
*/
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
public void afterCompletion(int status) {
/**
* 代码走到这里时,事务已经完成了(可能是回滚了、或者是提交了)
* 看下本地消息记录是否存在?如果存在,说明事务是成功的,业务是执行成功的,则投递消息 & 并将消息状态置为成功
*/
//为了提升性能:事务消息的投递消息这里异步去执行,即使失败了,会有补偿JOB进行重试
mqExecutor.execute(() -> deliverMsg(msgPOList));
}
});
3、异常情况
step5失败了,其他步骤都成功,此时业务执行成功,但是消息投递失败了,此时需要有个job来进行补偿,对于投递失败的消息进行重试。
4、消息投递补偿job
这个job负责从本地t_msg表中查询出状态为0记录或者失败需要重试的记录,然后进行重新投递到MQ。
对于投递失败的,采用衰减的方式进行重试,比如第1次失败了,则10秒后,继续重试,若还是失败,则再过20秒,再次重试,需要设置一个最大重试次数,最终还是投递失败,则需要告警+人工干预。
核心代码讲解
发送事务消息
这里按照上面的消息投递流程,在提交完本地事务以后,通过TransactionSynchronizationManager.registerSynchronization添加一个事务同步器TransactionSynchronization,这样事务执行完成之后,不管事务成功还是失败,都会调用TransactionSynchronization#afterCompletion 方法,然后我们在里面处理对应的逻辑即可:
- 看下本地消息记录是否存在?如果存在且状态还是未投递,说明事务是成功的,业务是执行成功的,则投递消息 & 并将消息状态置为成功
- 如果本地消息记录为空,说明本地事务回滚了,那么消息表中的记录也会自动事务回滚,不需要额外处理
@Transactional
public void sendMessage(String bodyJson) {
Message message = new Message();
message.setMessageId(UUID.randomUUID().toString());
message.setBodyJson(bodyJson);
message.setCreateTime(LocalDateTime.now());
message.setUpdateTime(LocalDateTime.now());
// Step 1: 开启本地事务
// Step 2: 执行本地业务
// Step 3: 消息表写入记录,status为0
message.setStatus(0);
messageRepository.save(message);
// Step 4: 提交本地事务
/**
* 若有事务,则在事务执行完毕之后,进行投递
*
* spring事务扩展点,通过TransactionSynchronizationManager.registerSynchronization添加一个事务同步器TransactionSynchronization,
* 事务执行完成之后,不管事务成功还是失败,都会调用TransactionSynchronization#afterCompletion 方法
*/
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
public void afterCompletion(int status) {
/**
* 代码走到这里时,事务已经完成了(可能是回滚了、或者是提交了)
* 看下本地消息记录是否存在?如果存在,说明事务是成功的,业务是执行成功的,则投递消息 & 并将消息状态置为成功
*/
Message msg=messageRepository.findById(message.getMessageId());
if (msg != null && msg.getStatus() == 0) {
// Step 5: 投递消息到MQ
rabbitTemplate.convertAndSend("exchangeName", "routingKey", bodyJson);
// 更新消息状态
msg.setStatus(1);
msg.setUpdateTime(LocalDateTime.now());
msg.save(message);
}
//如果msg==null,说明本地事务回滚了,那么消息表中的记录也会自动事务回滚,不需要额外处理
}
});
}
定时任务补偿处理失败消息
这里用定时任务扫描出状态为0或者status=2且retry=1,并且他们的重试时间在未来2分钟内(2分钟是为了避免一次性查出所有对数据库造成较大压力)要重试的消息:
- 如果发送成功,将状态设置为1代表发送成功了
- 如果发送异常,则将状态设置为2代表发送失败,同时根据已经重试次数是否小于5次(可以根据自己业务设定)设置是否需要继续重试
@Scheduled(cron = "*/60 * * * * ?") // 每1分钟执行一次
public void retryFailedMessages() {
// 查询状态为0或者status=2且retry=1且重试时间在未来2分钟内要重试的消息,sql是这样的
//select m from message m where (m.status = 0 and m.nextRetryTime<=当前时间 + 2分钟) or (m.status = 2 and m.sendRetry = true and m.nextRetryTime<=当前时间 + 2分钟)
List<Message> messages = messageRepository.findMessagesToSend(0);
for (Message message : messages) {
// 尝试重新发送
try {
rabbitTemplate.convertAndSend("exchangeName", "routingKey", message.getBodyJson());
message.setStatus(1); // 设置为已发送成功
messageRepository.save(message);
} catch (Exception e) {
// 处理失败的情况
message.setFailCount(message.getFailCount() + 1);
message.setFailMsg(e.getMessage());
// 设置为发送失败
message.setStatus(2);
message.setNextRetryTime(LocalDateTime.now().plusSeconds(10 * message.getFailCount()));
message.setSendRetry(message.getFailCount() < 5); // 最多重试5次
messageRepository.save(message);
}
}
}
2、Confirm模式+定时任务补偿
0、前置知识:Confirm和Return模式
rabbitmq 整个消息投递的路径为:
producer—>rabbitmq broker—>exchange—>queue—>consumer
confirm 模式和 return 模式都是确保消息可靠传输的机制。下面是对这两种模式的简单讲解:
Confirm 模式
confirm 模式用于确保消息已经成功到达 RabbitMQ 服务器。这种模式可以帮助你确认消息是否被正确地写入了 RabbitMQ 的交换机(Exchange)。工作原理如下:
- 发布消息:当生产者发送消息时,RabbitMQ 会给生产者一个确认响应(acknowledgment),表明消息已经被正确接收和处理。
- 确认机制:如果消息成功到达交换机,RabbitMQ 会发送一个确认(ack)给生产者;如果消息无法到达交换机(例如由于交换机不存在),RabbitMQ 会发送一个否定确认(nack)。
配置 confirm 模式时,通常需要设置 ConfirmCallback 来处理这些确认信息:
@Configuration
public class RabbitConfig {
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
// 消息确认成功
} else {
// 消息确认失败
System.out.println("Message failed to be acknowledged: " + cause);
}
});
return rabbitTemplate;
}
}
Return 模式
return 模式用于处理消息路由失败的情况。即消息不能被路由到任何队列时,RabbitMQ 会将消息返回给生产者。工作原理如下:
- 发布消息:当生产者发送消息到交换机,但交换机无法根据消息的路由键将其路由到任何队列时,消息会被返回给生产者。
- 返回机制:生产者可以通过
ReturnCallback处理这些返回的消息。
配置 return 模式时,你需要设置 ReturnsCallback 来处理这些返回的消息:
@Configuration
public class RabbitConfig {
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);
rabbitTemplate.setReturnsCallback(returned -> {
System.out.println("Message returned: " + returned.getMessage());
});
rabbitTemplate.setMandatory(true); // 设置为 true 以启用 Return 模式
return rabbitTemplate;
}
}
事务模式
事务模式(Transaction Mode)用于确保消息的可靠性,尤其是在生产者发送消息时。事务模式通过将消息的发送操作放入一个事务中来保证消息的发送和消费具有原子性,即要么成功发送并确认,要么失败并回滚。
其实就是我们所理解的数据库事务一个意思
举个例子理解一下就明白了:
- 发送消息的方法上添加
@Transactional注解标记事务。 - 调用 setChannelTransacted 方法设置为 true 开启事务模式。
//提供一个事务管理器
@Bean
RabbitTransactionManager transactionManager(ConnectionFactory connectionFactory) {
return new RabbitTransactionManager(connectionFactory);
}
@Transactional
public void send() {
rabbitTemplate.setChannelTransacted(true);
rabbitTemplate.convertAndSend(RabbitConfig.JAVABOY_EXCHANGE_NAME,RabbitConfig.JAVABOY_QUEUE_NAME,"hello rabbitmq!".getBytes());
int i = 1 / 0;
}
在上面的案例中,我们在结尾来了个 1/0 ,这在运行时必然抛出异常,我们可以尝试运行该方法,发现消息并未发送成功。
性能差不推荐!性能差不推荐!性能差不推荐!
总结
关于 ConfirmCallback 和 ReturnCallback 的回调说明:
1.如果消息没有到exchange,则confirm回调,ack=false
2.如果消息到达exchange,则confirm回调,ack=true
3.exchange到queue成功,则不回调return
4.exchange到queue失败,则回调return(需设置mandatory=true,否则不回回调,消息就丢了)
- Confirm 模式:确保消息成功到达交换机,适用于消息是否被成功接收的确认。性能较好,使用异步确认机制,但需要处理消息未被成功确认的情况。
- Return 模式:处理消息无法路由到任何队列的情况,适用于处理消息路由失败的情况。
- 事务模式:保证消息的可靠性,但性能开销较大。
在实际应用中,通常推荐使用 Confirm 模式来替代事务模式,因为它在保证消息可靠性的同时性能更好。事务模式更适合需要严格一致性和较低吞吐量的场景。
1、创建消息表
我们模拟公司添加新员工以后发送入职邮件的MQ案例:参考的是github的vhr项目
首先创建一张表,用来记录发送到中间件上的消息,对应实体类如下所示:
public class MailSendLog {
private String msgId;
private Integer empId;
//0 消息投递中 1 投递成功 2投递失败
private Integer status;
private String routeKey;
private String exchange;
private Integer count;
private Date tryTime;
private Date createTime;
private Date updateTime;
每次发送消息的时候,就往数据库中添加一条记录。这里的字段都很好理解,有三个我额外说下:
- status:表示消息的状态,有三个取值,0,1,2 分别表示消息发送中、消息发送成功以及消息发送失败。
- tryTime:表示消息的第一次重试时间(消息发出去之后,在 tryTime 这个时间点还未显示发送成功,此时就可以开始重试了)。
- count:表示消息重试次数。
2、发送消息
在消息发送的时候,我们就往该表中保存一条消息发送记录,并设置状态 status 为 0,tryTime 为 1 分钟之后。
公司添加员工以后发送入职邮件MQ:
employeeMapper.insertSelective添加新员工mailSendLogService.insert(mailSendLog)添加消息发送日志rabbitTemplate.convertAndSend发送MQ
public Integer addEmp(Employee employee) {
Date beginContract = employee.getBeginContract();
Date endContract = employee.getEndContract();
double month = (Double.parseDouble(yearFormat.format(endContract)) - Double.parseDouble(yearFormat.format(beginContract))) * 12 + (Double.parseDouble(monthFormat.format(endContract)) - Double.parseDouble(monthFormat.format(beginContract)));
employee.setContractTerm(Double.parseDouble(decimalFormat.format(month / 12)));
//添加员工
int result = employeeMapper.insertSelective(employee);
if (result == 1) {
Employee emp = employeeMapper.getEmployeeById(employee.getId());
//生成消息的唯一id
String msgId = UUID.randomUUID().toString();
MailSendLog mailSendLog = new MailSendLog();
mailSendLog.setMsgId(msgId);
mailSendLog.setCreateTime(new Date());
mailSendLog.setExchange(MailConstants.MAIL_EXCHANGE_NAME);
mailSendLog.setRouteKey(MailConstants.MAIL_ROUTING_KEY_NAME);
mailSendLog.setEmpId(emp.getId());
mailSendLog.setTryTime(new Date(System.currentTimeMillis() + 1000 * 60 * MailConstants.MSG_TIMEOUT));
//添加消息发送日志
mailSendLogService.insert(mailSendLog);
rabbitTemplate.convertAndSend(MailConstants.MAIL_EXCHANGE_NAME, MailConstants.MAIL_ROUTING_KEY_NAME, emp, new CorrelationData(msgId));
}
return result;
}
3、Confirm回调
在 confirm 回调方法中,如果收到消息发送成功的回调,就将该条消息的 status 设置为1(在消息发送时为消息设置 msgId,在消息发送成功回调时,通过 msgId 来唯一锁定该条消息)。
@Configuration
public class RabbitConfig {
public final static Logger logger = LoggerFactory.getLogger(RabbitConfig.class);
@Autowired
CachingConnectionFactory cachingConnectionFactory;
@Autowired
MailSendLogService mailSendLogService;
@Bean
RabbitTemplate rabbitTemplate() {
RabbitTemplate rabbitTemplate = new RabbitTemplate(cachingConnectionFactory);
rabbitTemplate.setConfirmCallback((data, ack, cause) -> {
String msgId = data.getId();
if (ack) {
logger.info(msgId + ":消息发送成功");
mailSendLogService.updateMailSendLogStatus(msgId, 1);//修改数据库中的记录,消息投递成功
} else {
logger.info(msgId + ":消息发送失败");
}
});
rabbitTemplate.setReturnCallback((msg, repCode, repText, exchange, routingkey) -> {
logger.info("消息发送失败");
});
return rabbitTemplate;
}
4、定时任务补偿
另外开启一个定时任务,定时任务每隔 10s 就去数据库中捞一次消息,专门去捞那些 status 为 0 并且已经过了 tryTime 时间记录,把这些消息拎出来后,首先判断其重试次数是否已超过 3 次,如果超过 3 次,则修改该条消息的 status 为 2,表示这条消息发送失败,并且不再重试。对于重试次数没有超过 3 次的记录,则重新去发送消息,并且为其 count 的值+1。
@Scheduled(cron = "0/10 * * * * ?")
public void mailResendTask() {
List<MailSendLog> logs = mailSendLogService.getMailSendLogsByStatus();
if (logs == null || logs.size() == 0) {
return;
}
logs.forEach(mailSendLog->{
if (mailSendLog.getCount() >= 3) {
mailSendLogService.updateMailSendLogStatus(mailSendLog.getMsgId(), 2);//直接设置该条消息发送失败
}else{
mailSendLogService.updateCount(mailSendLog.getMsgId(), new Date());
Employee emp = employeeService.getEmployeeById(mailSendLog.getEmpId());
rabbitTemplate.convertAndSend(MailConstants.MAIL_EXCHANGE_NAME, MailConstants.MAIL_ROUTING_KEY_NAME, emp, new CorrelationData(mailSendLog.getMsgId()));
}
});
}
两者方式的弊端
这2种思路有两个弊端:
- 去数据库走一遭,可能拖慢 MQ 的 Qos,不过有的时候我们并不需要 MQ 有很高的 Qos,所以这个应用时要看具体情况。
- 按照上面的思路,可能会出现同一条消息重复发送的情况,不过这都不是事,我们在消息消费时,解决好幂等性问题就行了。
MQ Broker保证可靠性
前面我们从生产者的角度分析了消息可靠性传输的原理和实现,现在我们从broker的角度来看一下如何能保证消息的可靠性传输?
假设有现在一种情况,生产者已经成功将消息发送到了交换机,并且交换机也成功的将消息路由到了队列中,但是在消费者还未进行消费时,mq挂掉了,那么重启mq之后消息还会存在吗?如果消息不存在,那就造成了消息的丢失,也就不能保证消息的可靠性传输了。
也就是现在的问题变成了如何在mq挂掉重启之后还能保证消息是存在的?
解决方案: 开启RabbitMQ的持久化,也即消息写入后会持久化到磁盘,此时即使mq挂掉了,重启之后也会自动读取之前存储的额数据
开启持久化的步骤:
1、创建交换机时,设置durable=true:这个在springboot里面默认就是持久化的,其实不需要特别指定!
//构造方法:
public DirectExchange(String name) {
super(name);
}
super对应的构造方法:durable=true
public AbstractExchange(String name) {
this(name, true, false);
}
public DirectExchange(String name, boolean durable, boolean autoDelete)
@Bean
DirectExchange testDirectExchange() {
//return new DirectExchange("testDirectExchange");效果一样
return new DirectExchange("testDirectExchange",true,false);
}
2、创建queue时,设置durable=true:这个在springboot里面也默认就是持久化的,所以也不需要特别指定!
public Queue(String name) {
this(name, true, false, false);
}
@Bean
Queue testQueue() {
//return new Queue("testQueue");效果一样
return new Queue("testQueue",true);
}
注意这只会持久化当前队列的元数据,不会持久化消息数据,还要配合第三步骤
3、发送消息时,设置消息的deliveryMode=2,此时才会将消息持久化到磁盘上去:这个在SpringBoot里面发送消息时自动设置deliveryMode=2,也不需要人工再去设置!
是不是发现springboot帮我们封装了很多默认的常用的参数,真的就叫做约定大于配置(在没有规定配置的地方,采用默认配置,以力求最简配置为核心思想)
通过以上方式,可以保证大部分消息在broker不会丢失,但是还是有很小的概率会丢失消息,什么情况下会丢失呢?
假如消息到达队列之后,还未保存到磁盘mq就挂掉了,此时还是有很小的几率会导致消息丢失的。
这就要mq的持久化和前面的confirm进行配合使用,只有当消息写入磁盘后才返回ack,那么就是在持久化之前mq挂掉了,但是由于生产者没有接收到ack信号,此时可以进行消息重发。
这个方案其实就是我们的第二个方案,具体参考上述方案2:Confirm模式+定时任务补偿
消费者可靠性
注意点:
手动ACK与自动ACK冲突:在 RabbitMQ 中,消息的确认(ACK)可以是手动的也可以是自动的。如果在配置中设置了自动 ACK,但在消费者代码中又手动调用了
basicAck方法,就会导致报错。这是因为 RabbitMQ 认为消息已经被处理,但客户端又尝试再次确认,造成了冲突。
自动ack+默认重试+死信队列
为了在 Spring Boot 中实现使用 RabbitMQ 和死信队列(DLQ)来处理消息重试,自动 ACK,和达到重试次数后将消息投递到死信队列的功能,可以按照以下步骤进行设置:
1. 添加依赖
在你的 pom.xml 中添加 RabbitMQ 的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2. 配置 RabbitMQ
在 application.yml 或者 application.properties 中配置 RabbitMQ 的连接信息和队列、交换机、路由等设置:
对于RabbitMQ的默认重试次数到底是几次???网上搜出来有人说3次,有人说无限重试,我自己本地测试了一下,可以分为如下3个场景
默认的无限重试配置
这里可以看到关于重试的配置什么都没有,此时如果消费异常会默认无限重试
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
acknowledge-mode: auto
默认开启3次重试
可以看到这里开启了配置retry.enabled=true,此时如果消费异常会默认重试3次
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
acknowledge-mode: auto
retry:
enabled: true
但是我并没有3次的重试配置,为什么是3呢,看下源码就知道了
org.springframework.boot.autoconfigure.amqp.RabbitProperties.Retry
可以看到源码里面maxAttempts=3
public static class Retry {
/**
* Whether publishing retries are enabled.
*/
private boolean enabled;
/**
* Maximum number of attempts to deliver a message.
*/
private int maxAttempts = 3;
/**
* Duration between the first and second attempt to deliver a message.
*/
private Duration initialInterval = Duration.ofMillis(1000);
自定义重试次数
当然我们也可以重新定义重试次数
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
acknowledge-mode: auto
retry:
enabled: true
max-attempts: 5
# max-interval: 10000 # 重试最大间隔时间
# initial-interval: 2000 # 重试初始间隔时间
# multiplier: 2 #间隔时间乘子,间隔时间*乘子=下一次的间隔时间,最大不能超过设置的最大间隔时间
3. 定义普通队列和死信队列
通过配置类定义普通队列、死信队列、交换机和绑定关系。
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RabbitMQConfig {
public static final String NORMAL_QUEUE = "normal.queue";
public static final String DLX_QUEUE = "dlx.queue";
public static final String EXCHANGE = "exchange";
@Bean
public Queue normalQueue() {
return QueueBuilder.durable(NORMAL_QUEUE)
.withArgument("x-dead-letter-exchange", EXCHANGE)
.withArgument("x-dead-letter-routing-key", "dlx.routing.key")
.build();
}
@Bean
public Queue dlxQueue() {
return QueueBuilder.durable(DLX_QUEUE).build();
}
@Bean
public DirectExchange exchange() {
return new DirectExchange(EXCHANGE);
}
@Bean
public Binding normalBinding() {
return BindingBuilder.bind(normalQueue()).to(exchange()).with("normal.routing.key");
}
@Bean
public Binding dlxBinding() {
return BindingBuilder.bind(dlxQueue()).to(exchange()).with("dlx.routing.key");
}
}
4. 实现消费者逻辑
在消费者中实现自动重试机制,并设置重试次数达到 3 次后将消息投递到死信队列。这里我们使用 @RabbitListener 来监听队列。
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.rabbit.listener.api.ChannelAwareMessageListener;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
@Service
public class MessageConsumer {
private static final int MAX_RETRY_COUNT = 3;
@RabbitListener(queues = RabbitMQConfig.NORMAL_QUEUE)
public void receiveMessageForAuto(Message message, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, Channel channel) throws IOException {
try {
// 获取消息内容
String msgBody = new String(message.getBody());
// 消费者业务逻辑
System.out.println("Received message: " + message);
// 模拟处理异常
throw new RuntimeException("Simulated exception");
} catch (Exception e) {
System.out.println(e.getMessage());
throw new RuntimeException("转换抛出测试");
}
}
}
在这个类继续加上死信消费者处理
@SneakyThrows
@RabbitListener(queues = DLX_QUEUE)
public void handleDlq(Channel channel, Message message){
// 处理消息
System.out.println("死信队列-handleDlq {} :"+message);
}
5. 测试
启动 Spring Boot 应用,并发送消息到普通队列。模拟消费者处理失败,通过日志观察到重试机制,超过 3 次后消息被投递到死信队列。
6. 发送消息
通过 RabbitTemplate 发送消息到普通队列。
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MessageProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/send")
public String sendMessage() {
String message = "Hello RabbitMQ!";
rabbitTemplate.convertAndSend(RabbitMQConfig.EXCHANGE, "normal.routing.key", message);
return "Message sent!";
}
}
手动ack+手写重试逻辑+死信队列
在 Spring Boot 中使用 RabbitMQ 的手动 ACK 模式实现消息消费和重试机制,并将达到最大重试次数后的消息投递到死信队列的功能,可以通过以下步骤实现。主要区别是手动处理 ACK,并根据消费结果进行确认或拒绝。
1. 修改配置
在 application.yml 或 application.properties 中,将 acknowledge-mode 设置为 manual,启用手动 ACK 模式。
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
listener:
simple:
acknowledge-mode: manual # 手动确认模式
2. 定义普通队列和死信队列
这一部分与自动 ACK 实现时相同。这里直接沿用之前的配置。
3. 实现消费者逻辑
如果这里手动ack的话,一定要自己去实现重试逻辑,依靠mq本身的重试达到3次以后,并不会把消息投入到死信队列,并且mq中还会有一条unack的消息。
注意这里是针对业务逻辑bug尝试,如果是网络这种问题一般重试了则会正常消费,也能够ack成功!
在消费者中实现手动实现循环重试3次,3次以后还是失败则执行basicNack(deliveryTag, false,false)将消息投递到死信队列进行处理
channel.basicNack 与 channel.basicReject 的区别在于basicNack可以批量拒绝多条消息,而basicReject一次只能拒绝一条消息。
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@Service
public class MessageConsumer {
private static final int MAX_RETRY_COUNT = 3;
@RabbitListener(queues = RabbitMQConfig.NORMAL_QUEUE)
public void receiveMessageForManual(String message, @Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
Channel channel) throws IOException {
int retryCount = 0;
while (retryCount<=MAX_RETRY_COUNT){
try {
// 消费者业务逻辑
System.out.println("Received message: " + message);
// 模拟处理异常
throw new RuntimeException("Simulated exception");
} catch (Exception e) {
if (retryCount >=MAX_RETRY_COUNT) {
// 重试次数已达最大,将消息投递到死信队列,并确认消费
System.out.println("Message will be moved to DLX after " + retryCount + " retries.");
channel.basicNack(deliveryTag, false,false);
break;
} else {
retryCount++;
// 重试次数未达最大,继续循环重试
System.out.println("Retrying message, count: " + retryCount);
}
}
}
}
}
优化-采用spring retry重试
@Retryable注解:value = { RuntimeException.class }:指定遇到RuntimeException时进行重试。maxAttempts = MAX_RETRY_COUNT:指定最大重试次数为MAX_RETRY_COUNT次。backoff = @Backoff(delay = 1000):每次重试之间有 1000 毫秒的延迟。
@Recover注解:- 该方法在重试次数用尽后执行。它接收触发重试的异常以及原始方法的参数。
- 在
recover方法中,你可以处理失败的情况,比如将消息投递到死信队列。
@RabbitListener(queues = RabbitMQConfig.NORMAL_QUEUE)
@Retryable(
value = { RuntimeException.class }, // 需要重试的异常类型
maxAttempts = MAX_RETRY_COUNT, // 最大重试次数
backoff = @Backoff(delay = 1000) // 重试延迟,可选
)
public void receiveMessageBySpringRetry(String message,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
Channel channel) throws IOException {
// 消费者业务逻辑
System.out.println("Received message: " + message);
// 模拟处理异常
throw new RuntimeException("Simulated exception");
}
// 在重试达到最大次数后执行的逻辑
@Recover
public void recover(RuntimeException e, String message,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag,
Channel channel) throws IOException {
System.out.println("Message will be moved to DLX after retries exceeded.");
channel.basicNack(deliveryTag, false, false); // 投递到死信队列
}
4. 发送消息
发送消息的代码不变,使用 RabbitTemplate 发送消息到普通队列。
5. 测试
启动 Spring Boot 应用,发送消息到普通队列。消费者在消费失败时会自动重试,达到最大重试次数后消息会被投递到死信队列。
6. 总结
在手动 ACK 模式下,消费者可以根据消息处理的结果决定是确认消息 (basicAck) 还是拒绝消息 (basicNack) 并选择是否重新入队。通过这种方式,能够实现更灵活的消息处理和重试机制。
思考1: 重试逻辑处理
注意点:
- 重试并不是RabbitMQ重新发送了消息,仅仅是消费者内部进行的重试,换句话说就是重试跟mq没有任何关系;
- 重试场景:网络问题重试是有意义的,业务bug重试没有意义,要配合死信队列进行处理
是否是消费者只要发生异常就要去重试呢?其实不然,假设下面的两个场景:
-
http下载视频或者图片或者调用第三方接口
-
空指针异常或者类型转换异常(其他的受检查的运行时异常)
很显然,第一种情况有重试的意义,第二种没有。
对于第一种情况,由于网络波动等原因造成请求失败,重试是有意义的;
对于第二种情况,需要修改代码才能解决的问题,重试也没有意义。
所以对于消费端异常的消息,如果在有限次重试过程中消费成功是最好的,如果有限次重试之后仍然失败的消息可以发到死信队列进行处理,具体如何处理可以参考如下
思考2:死信队列应该如何处理
一般情况下我们重试失败以后到了死信队列应该怎么处理呢?大概思路可以参考如下
1、记录日志
在死信队列的监听器中记录详细的错误日志,以便后续分析和排查问题。
2、保存到数据库
将处理失败的消息及其错误信息保存到数据库中,以便后续手动处理或分析。
3、通知管理员
通过邮件、短信或其他方式通知系统管理员或相关人员,以便及时处理问题。
4、人工干预
将消息标记为需要人工干预,并提供一个管理界面供管理员查看和处理这些消息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











