










目录
一、AFS(Anomaly-aware Feature Selection)
二、RRS(Reconstruction Residuals Selection)
三、SDAS(Strength-controllable Diffusion Anomaly Synthesis)
SIA(Synthetic Industrial Anomalies)数据集
【1】重建类方法(Reconstruction-based Methods)
【2】嵌入类方法(Embedding-based Methods)
【3】自监督类方法(Self-supervised Methods)
【4】一类分类方法(One-class Classification Methods)
论文标题
RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection
RealNet:用于异常检测的具有真实合成异常的特征选择网络
核心问题:
在工业异常检测领域,如何从大规模预训练模型中有效选择特征成为当前面临的主要挑战。传统方法在特征选择上缺乏统一的策略,导致异常检测效果在不同类别间不稳定,且高计算成本限制了模型实用性。该论文针对“预训练特征选择难”和“合成异常不真实”这两个痛点提出了新的解决方案。
创新方法:
RealNet 提出了两项关键技术:
-
AFS(Anomaly-aware Feature Selection):自适应选择与异常高度相关的预训练特征,减少冗余与偏差(依赖预训练模型)。
-
RRS(Reconstruction Residuals Selection):在重建残差中去除不含异常信息的部分,提高异常召回率。
此外,该方法引入 SDAS(Strength-controllable Diffusion Anomaly Synthesis) 技术生成更贴近真实分布的异常样本,并发布了大规模合成异常数据集 SIA,用于增强自监督学习。
论文讲解:
论文分为五个核心部分:
-
引言:阐述特征选择与异常合成的重要性及现有方法的缺陷。
-
相关工作:对比了重建类【1】、嵌入类【2】、自监督类【3】和一类分类方法【4】的优缺点,为提出 RealNet 奠定基础。
-
方法设计:详细介绍 RealNet 网络结构,特别是 AFS 与 RRS 如何配合以提升检测能力。SDAS 的设计保证了生成异常与实际异常的视觉相似性。
-
实验验证:在四个工业数据集上验证方法性能,在 MVTec-AD、MPDD、BTAD 和 VisA 数据集上均超越现有 SOTA。
-
数据集发布与消融实验:介绍合成数据集 SIA,并通过消融分析验证各模块的贡献。
局限分析:
-
计算成本:尽管引入了特征选择降低计算负担,但仍依赖大规模预训练模型(此文章采用了 WideResNet50作为预训练模型),推理成本在边缘部署中仍可能成为瓶颈。
-
泛化能力:方法在公开工业图像上表现优异,但在更加复杂或多变的场景中泛化能力仍需进一步验证。
-
数据需求:虽然 SDAS 可合成异常样本,但其仍需大量正常图像和高质量掩膜进行训练和微调,限制了其应用门槛。
问题解答:
-
Why:为什么该方法比传统方案更优?
RealNet 通过引入 AFS 与 RRS 两大自适应模块,解决了传统方法特征冗余、误选问题,同时在保持高精度的同时大幅提高召回率。此外,SDAS 异常生成器提高了异常样本的多样性与真实性,使训练过程更有效。 -
How:如何将该方法扩展到其他场景?
RealNet 的核心思想可迁移到如医学影像、视频监控等领域:只需替换预训练特征提取模型与重建目标,同时调适 SDAS 生成的异常类型,即可应用于不同模态的异常检测任务。
RealNet三项核心技术
整体流程图
来自论文原文并非博主原创。
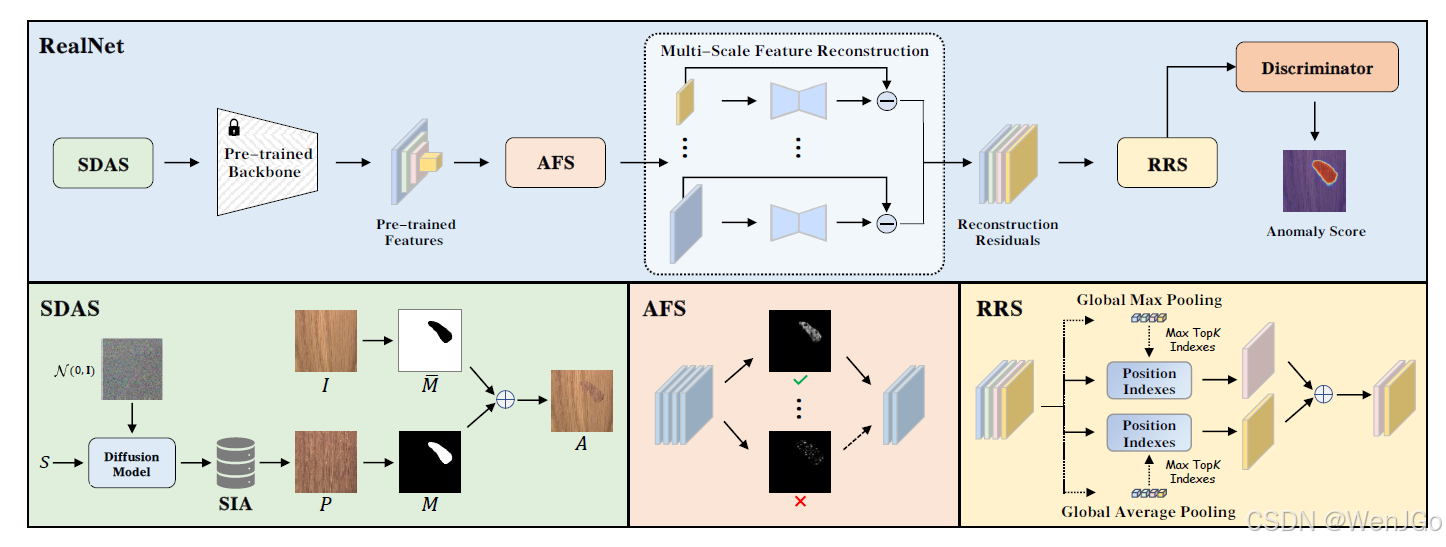
图2. RealNet的流程包含三个核心组件:可控制强度的扩散异常合成(SDAS)、异常感知特征选择(AFS)和重建残差筛选(RRS)。
- SDAS 能够生成多样化、接近真实分布的异常图像;
- AFS 对大规模预训练CNN提取的特征进行精炼,以实现降维。
精炼后的特征通过一组重建网络被重建为对应的正常图像特征; - RRS 则用于筛选出最可能识别异常的重建残差,并将这些残差输入判别器中进行异常检测与定位。
一、AFS(Anomaly-aware Feature Selection)
中文名称:异常感知特征选择模块
目的
从预训练模型提取的大量特征中,选择最能体现异常特征的子集,避免冗余和误导信息影响检测效果。
动机
-
工业检测图像中,预训练模型(WideResNet50)会输出多个尺度、多个层次的特征图;
-
然而,并非所有通道、层级都对异常敏感;
-
直接使用所有特征会带来冗余、噪声和计算成本。
实现方式
-
提取图像经过预训练模型(WRN-50)后的多个层的特征;
-
使用一个通道注意力机制(Channel Attention)【5】模块,学习每个通道对异常的响应程度;
-
通过多尺度融合进一步筛选,选择响应最强的通道,作为最终用于检测的特征。
优势
-
减少无效特征带来的误报;
-
提高模型在推理阶段的效率;
-
可自适应调整不同类别、不同样本的特征选择。
二、RRS(Reconstruction Residuals Selection)
中文名称:重建残差筛选模块
目的
从输入图像与重建图像之间的差异(残差)中,剔除不包含异常信息的部分,保留最有可能是异常的残差信号。
动机
-
重建类方法的残差图中,既包含异常区域,也包含重建模糊、背景噪声等非异常因素;
-
这些多余信号会误导后续异常定位和分类;
-
需要一种机制筛选出真正有用的“异常残差”。
实现方式
-
先用编码器-解码器结构【6】对图像进行重建;
-
得到输入图像与重建图像的像素差异(残差图);
-
使用一个 门控机制(Gated Selection)【7】 或轻量分类器模块,对残差图每个位置进行评分;
-
保留得分高的区域,生成优化过的残差图,送入检测器。
优势
-
排除“无害残差”,提升召回率;
-
更聚焦于真实异常区域;
-
减少误检和漏检现象。
三、SDAS(Strength-controllable Diffusion Anomaly Synthesis)
中文名称:强度可控的扩散异常合成机制
目的
生成接近真实分布的异常样本用于训练,增强自监督学习模型的泛化能力和鲁棒性。
动机
-
实际工业图像中,异常样本极少,监督学习困难;
-
原有的合成方法过于简单或风格不统一,容易被模型识别为“伪异常”;
-
需要合成“拟真、可控、具有结构感”的异常图像。
实现方式
-
基于 扩散模型(Diffusion Model)【8】:从正常图像中添加噪声,再逆过程生成目标图像;
-
控制合成异常的“强度”:即残缺程度、位置、形状等,通过条件引导方式生成;
-
保证合成异常分布与真实异常一致,例如表面缺陷、凹陷、裂痕等;
-
同时生成对应的掩膜(Mask,与合成异常图像对应的像素级标注图,用于指示图像中异常区域的位置和形状)用于训练监督。
优势
-
保留正常图像背景和纹理,增加真实性;
-
异常形式多样,提升模型泛化能力;
-
可配合自监督任务提升特征学习质量。
SIA(Synthetic Industrial Anomalies)数据集
在 SDAS 基础上,作者构建了 大规模工业异常数据集 SIA,覆盖多个异常类别和模态,为社区提供统一的评估基准和训练数据源。
名词解释
【1】重建类方法(Reconstruction-based Methods)
原理:
使用自编码器(Autoencoder)、变分自编码器(VAE)或生成对抗网络(GAN)重建输入图像,利用输入与重建图像之间的残差检测异常。
优点:
-
训练仅需正常样本,无需异常数据;
-
可解释性强:残差高的区域即可能为异常;
-
适合局部异常检测,重建失败区域直观呈现。
缺点:
-
重建泛化性强时可能重建异常样本,导致检测失败;
-
无法排除与异常无关的残差信号,误报率高;
-
对模型架构与损失函数敏感,训练不稳定。
【2】嵌入类方法(Embedding-based Methods)
原理:
将图像嵌入高维特征空间,检测与正常样本分布差异,常基于KNN、PatchCore或高斯建模等方式。
优点:
-
计算高效,推理阶段无需重建;
-
利用预训练特征表现强,迁移性好;
-
部署简单,适合边缘设备。
缺点:
-
特征选择主观,对层次和通道组合依赖强;
-
对高维特征空间中的异常可分性敏感;
-
缺乏端到端优化过程,不可训练性影响适应性。
【3】自监督类方法(Self-supervised Methods)
原理:
设计代理任务(如旋转预测、遮挡还原、图像恢复等)作为训练目标,让模型学习正常数据的模式,异常样本因无法完成任务而表现异常。
优点:
-
无需人工标注异常,高度自动化;
-
适合无标签工业场景;
-
具有一定的泛化能力。
缺点:
-
代理任务设计依赖经验,不通用;
-
难以生成真实分布下的异常特征;
-
模型易过拟合代理任务而非异常特性。
【4】一类分类方法(One-class Classification Methods)
原理:
基于如 OC-SVM、Deep SVDD 等方法,仅使用正常样本训练一个紧凑的表示空间,异常样本将偏离该空间。
优点:
-
理论基础清晰,数学模型简单;
-
适合小样本学习;
-
易于解释,异常边界明确定义。
缺点:
-
性能受特征表达能力限制大;
-
对噪声样本和异常干扰敏感;
-
难以适应分布多样的正常样本集。
【5】通道注意力机制
RealNet 中使用的通道注意力机制(Channel Attention)并不是在这篇论文首创。该机制最早由 Hu 等人在 2017 年提出的 Squeeze-and-Excitation Networks(SENet)中引入,并在 2018 年的 CVPR 上发表。SENet 通过对特征通道间的相关性进行建模,提升了图像识别任务的性能,并在 2017 年的 ImageNet 挑战赛中取得了冠军。
通道注意力机制的实现原理
通道注意力机制的核心思想是通过学习每个通道的重要性权重,增强对关键信息的关注,抑制无关或冗余的信息。其典型实现方式包括以下几个步骤:
-
Squeeze(压缩):对每个通道的特征图进行全局平均池化(Global Average Pooling),将空间维度的信息压缩为一个数值,得到通道描述子。
-
Excitation(激励):将压缩后的通道描述子输入到一个由两个全连接层组成的瓶颈结构中,学习通道间的依赖关系,生成每个通道的权重系数。
-
Scale(缩放):将学习到的权重系数通过逐通道乘法的方式应用到原始特征图上,完成对特征的重标定。
这种机制使得网络能够自适应地调整各个通道的响应,突出对当前任务更有用的特征,抑制无关或冗余的信息,从而提升模型的表达能力和性能。
RealNet 中的应用
在 RealNet 中,通道注意力机制被用于其提出的 AFS(Anomaly-aware Feature Selection)模块中。通过引入通道注意力机制,RealNet 能够自适应地选择与异常检测任务高度相关的预训练特征,减少冗余和偏差,提高模型在异常检测任务中的性能。
【6】什么是编码器-解码器?
1. 编码器(Encoder)
- 功能:将输入数据(如图像)压缩成一个低维的特征表示(feature representation),通常称为“潜在表示”(latent representation)。
- 实现方式:通常是卷积神经网络(CNN)的一部分,逐层提取图像的抽象特征。
- 输出:一个包含图像关键信息的特征图(feature map)。
2. 解码器(Decoder)
- 功能:从编码器输出的特征表示中恢复出原始输入的结构,比如重建图像。
- 实现方式:通常使用反卷积(转置卷积)、上采样等方式,逐步还原图像的空间维度。
- 输出:与输入图像尺寸相同或相近的重建图像。
举个简单例子帮助理解
假设啊,你有一个正常样本图像(比如一张没有划痕的手机屏幕照片),编码器-解码器模型训练得非常好,能够很好地重建这种正常的图像。
但如果你输入一张有划痕的手机屏幕图像(异常样本),模型因为没见过这种异常模式,就很难准确重建那条划痕的位置,导致该区域的残差很大。
所以:
- 正常区域:重建得好 → 残差小;
- 异常区域:重建得差 → 残差大;
【7】门控机制
门控机制(Gated Selection)是一种用于控制信息流的技术,常见于各种深度学习模型中,如循环神经网络(RNN)、长短期记忆网络(LSTM)和门控循环单元(GRU)。在这篇文章中的门控机制被用来对重建图像与原始输入图像之间的差异(残差图)进行评分,以识别并保留最有可能包含异常信息的区域。
门控机制的工作原理
-
特征提取:首先,通过编码器-解码器结构生成输入图像与重建图像之间的残差图。这一步骤已经完成了对原始数据的压缩表示及其重建过程,得到了反映两者之间差异的残差图。
-
评分机制:接下来,使用门控机制或轻量级分类器对残差图中的每个位置进行评估。这个步骤可以看作是为残差图中的每一个像素或区域分配一个分数,该分数反映了这个位置包含异常的可能性。在这个过程中,门控机制能够学习到哪些模式或特征更可能指示异常情况。
-
选择性保留:基于上述得分,系统会选择性地保留那些得分高的区域(即认为更可能是异常的部分),而过滤掉得分低的区域。这样做的目的是为了减少非异常因素(比如重建模糊、背景噪声等)对最终异常检测结果的影响。
【8】扩散模型(Diffusion Model)
扩散模型(Diffusion Model)是一类生成模型,它受到了非平衡热力学的启发。这类模型通过逐步向数据中添加噪声来学习如何从随机噪声中生成真实数据样本。扩散模型的核心思想是定义一个扩散过程,在这个过程中,原始数据逐渐被转化为噪声;然后,训练一个模型来逆转这个过程,即从噪声中恢复出原始数据。
扩散模型的工作原理
-
前向扩散过程:在这个阶段,扩散模型通过一系列步骤逐步向数据中添加噪声,直到数据变得像是纯粹的噪声。每一步都使用马尔科夫链(未来只依赖现在,与过去无关,具体自行百度吧)的形式,其中每个步骤都会在当前数据上添加少量的高斯噪声。最终结果是一个与输入数据分布无关的纯噪声分布。
-
逆向生成过程:这是扩散模型的学习目标,即学习如何逆转上述的前向扩散过程。模型需要学会从完全的噪声开始,逐步去除噪声,以恢复到接近于原始数据的样本。这一过程同样按照马尔科夫链的方式进行,但方向相反,旨在将噪声映射回有意义的数据点。
-
训练过程:为了训练扩散模型,通常采用变分推断的方法最小化生成样本与真实样本之间的差异。这意味着模型尝试学习一个近似的逆向扩散过程,使得从噪声开始的逐步变换能够尽可能准确地还原为原始数据分布。



















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











