






【论文阅读| CVPR 2023 |MetaFusion:通过对象检测的元特征嵌入进行红外和可见光图像融合】

题目:MetaFusion: Infrared and Visible Image Fusion via Meta-Feature Embedding
from Object Detection
会议:Computer Vision and Pattern Recognition(CVPR)
论文:链接
代码:https://github.com/wdzhao123/MetaFusion
年份:2023
1.摘要&&引言
融合红外图像和可见光图像能够为后续的目标检测任务提供更多的纹理细节。反过来,目标检测任务则提供目标的语义信息,以提升红外和可见光图像的融合效果。
然而,这两个不同层次任务之间的特征差异阻碍了其发展进程。
针对这一问题,本文提出了一种通过目标检测的元特征嵌入来实现红外与可见光图像融合的方法。
其核心思想是设计一个元特征嵌入模型,依据融合网络的能力生成目标语义特征,这样语义特征就自然地与融合特征相适配。该方法通过模拟元学习进行优化。
此外,我们进一步在融合任务和检测任务之间实施相互促进学习,以提高它们各自的性能。
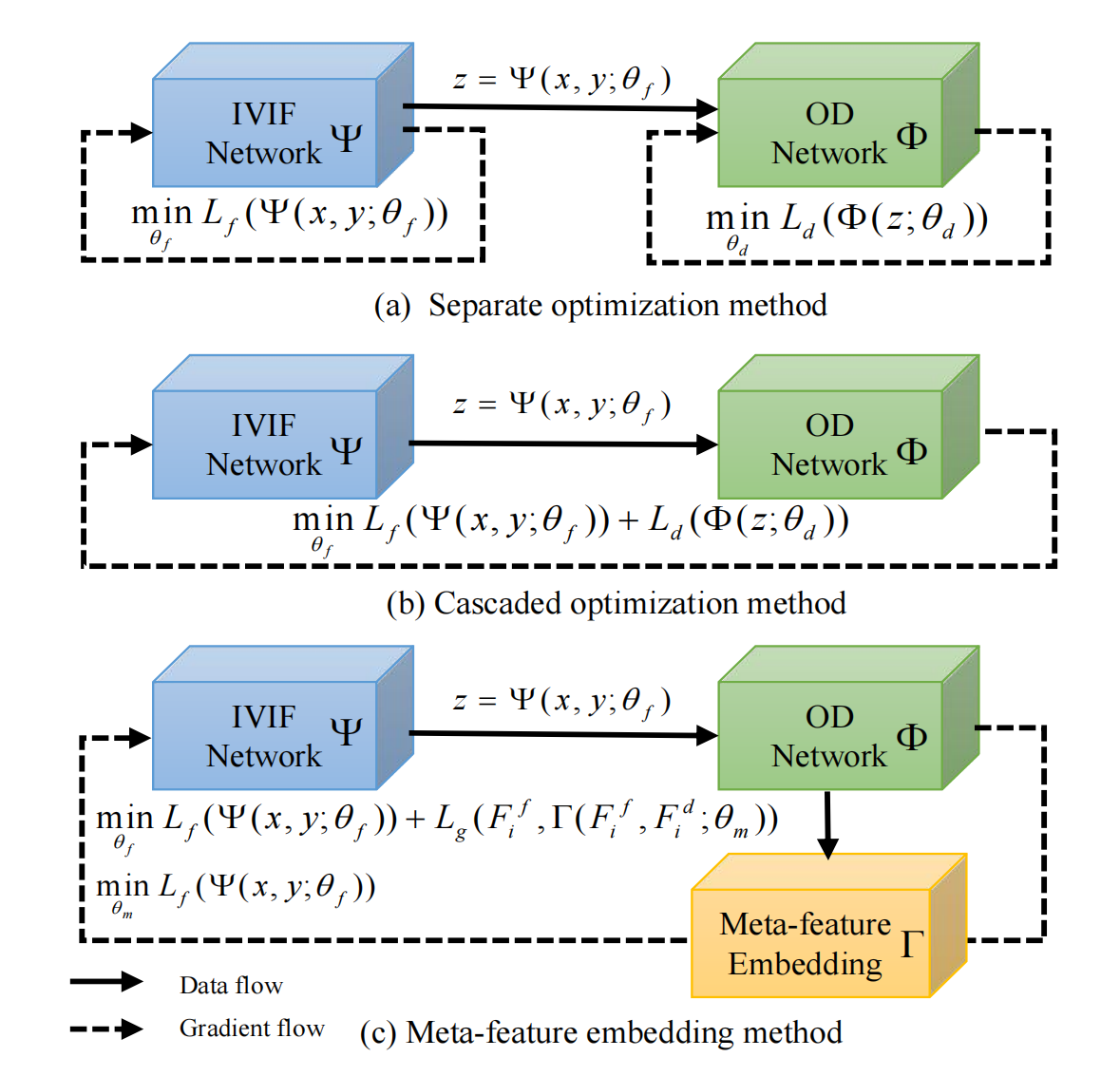
图1. 红外与可见光图像融合(IVIF)和目标检测(OD)的不同联合学习方法。
(a) 分离优化方法:首先通过融合损失 L f L_{f} Lf 对红外与可见光图像融合网络 Ψ \Psi Ψ 进行优化。然后,融合网络 Ψ \Psi Ψ 根据输入的红外和可见光图像对 x x x、 y y y 生成融合结果 z z z。最后,利用融合结果 z z z,通过检测损失 L d L_{d} Ld 对目标检测网络 Φ \Phi Φ 进行优化。
(b) 级联优化方法:将目标检测网络 Φ \Phi Φ 视为一种约束条件,通过损失 L f L_{f} Lf 和 L d L_{d} Ld 对红外与可见光图像融合网络 Ψ \Psi Ψ 进行优化。
(c) 元特征嵌入方法:对元特征嵌入模块 Γ \Gamma Γ 进行优化,以学习如何引导融合网络 Ψ \Psi Ψ 使损失 L f L_{f} Lf 较低。然后,元特征嵌入模块 Γ \Gamma Γ 根据检测特征 F i d F_{i}^{d} Fid和融合特征 F i d F_{i}^{d} Fid 生成元特征。最后,利用损失 L d L_{d} Ld,使用元特征来引导融合网络 Ψ \Psi Ψ。
具体而言,我们提出了一种基于目标检测元特征嵌入的红外与可见光图像融合方法,将其命名为MetaFusion。MetaFusion包括红外与可见光图像融合网络 F F F、目标检测网络 D D D以及元特征嵌入网络 M F E MFE MFE。
特别地,元特征嵌入网络 M F E MFE MFE旨在生成元特征,以弥合融合网络 F F F和检测网络 D D D之间的差距,它通过两个交替步骤进行优化:内层更新和外层更新。
在内层更新过程中,我们首先使用元训练集 S m t r S_{mtr} Smtr对融合网络 F F F进行优化,以得到其更新后的网络 F ′ F' F′。然后, F ′ F' F′在元测试集 S m t s S_{mts} Smts上计算融合损失,以此来优化元特征嵌入网络 M F E MFE MFE。这样做的动机在于,如果 M F E MFE MFE成功生成了与融合网络 F F F兼容的元特征,那么 F ′ F' F′将生成更好的融合图像,也就是说,融合损失应该会更低。
在外层更新过程中,融合网络 F F F在固定的元特征嵌入网络 M F E MFE MFE所生成的元特征的引导下,在元训练集 S m t r S_{mtr} Smtr和元测试集 S m t s S_{mts} Smts上进行优化。通过这种方式,融合网络 F F F能够学习如何提取语义信息,从而提高融合质量。在上述两个交替步骤中,目标检测网络 D D D保持固定,以提供检测语义信息。
因此,我们进一步实施了一种相互促进学习机制,即使用改进后的融合网络 F F F生成融合结果来微调目标检测网络 D D D,然后,改进后的目标检测网络 D D D提供更好的语义信息来优化融合网络 F F F。
综上所述,我们的贡献如下。
- 我们探究了红外与可见光图像融合(IVIF)和目标检测(OD)的联合学习框架,并提出了MetaFusion方法,以在这两项任务上取得优异的性能表现。
- 设计了元特征嵌入网络,用于生成能够弥合融合网络(F)和检测网络(D)之间差距的元特征。
- 接着,引入了融合网络(F)和检测网络(D)之间的相互促进学习机制,以提升它们的性能。
- 在图像融合和目标检测方面进行的大量实验验证了所提出方法的有效性。
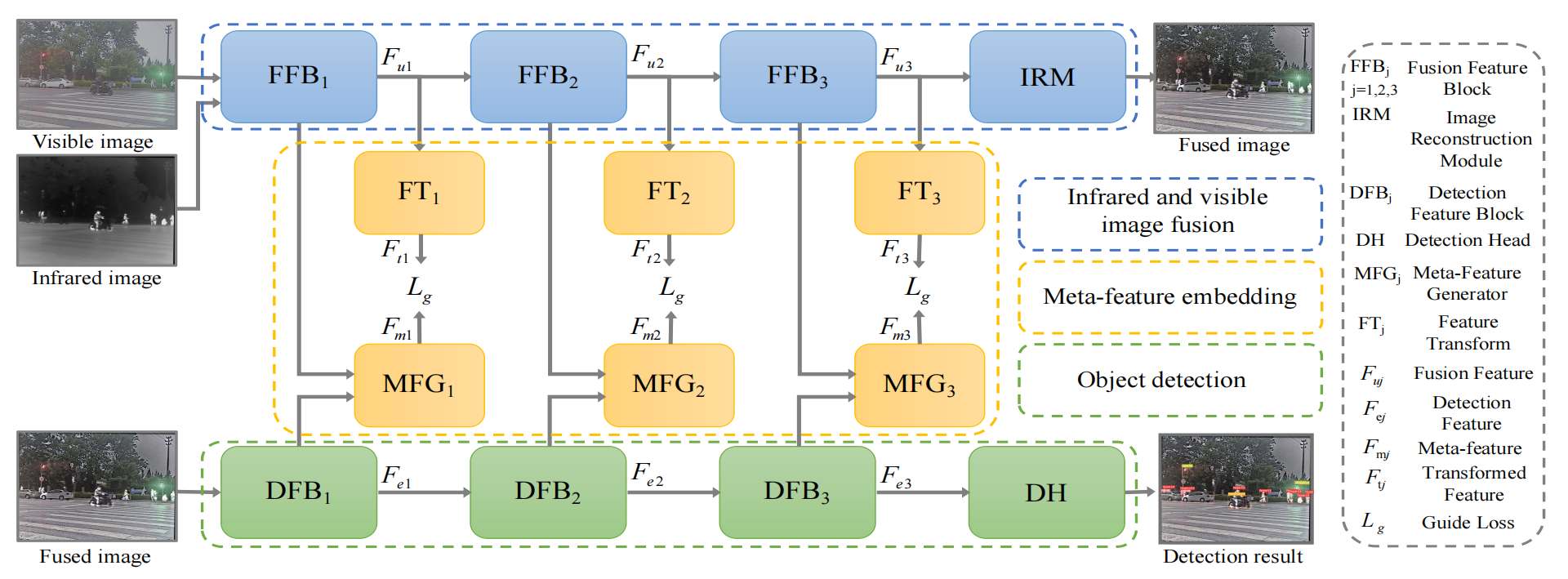
图2. 所提出的MetaFusion的框架示意图。MetaFusion包括三个部分:红外与可见光图像融合(IVIF)、目标检测(OD)和元特征嵌入(MFE)。
IFIV网络包含四个模块:
三个用于提取和融合特征的特征融合模块( F F B 1 FFB1 FFB1)、( F F B 2 FFB2 FFB2)、( F F B 3 FFB3 FFB3);
一个用于重建融合结果的图像重建模块( I R M IRM IRM)。
MFE包含:
三个元特征生成器( M F G 1 MFG_{1} MFG1)、( M F G 2 MFG_{2} MFG2)、( M F G 3 MFG_{3} MFG3),用于从目标检测特征( F e j F_{ej} Fej)生成多级元特征;
三个特征变换网络( F T 1 FT1 FT1)、( F T 2 FT_{2} FT2)、( F T 3 FT_{3} FT3),用于将元特征转换为融合特征。
目标检测网络分为:
三个特征提取模块( D F B 1 DFB_{1} DFB1)、( D F B 2 DFB_{2} DFB2)、( D F B 3 DFB_{3} DFB3);
一个目标检测头( D H DH DH)。
2.方法
2.1元特征嵌入
元特征嵌入包括元特征生成器 M F G MFG MFG和特征变换 F T FT FT。元特征生成器 M F G MFG MFG根据目标检测特征 F e j F_{ej} Fej以及红外与可见光图像融合 I V I F IVIF IVIF特征 F u j F_{uj} Fuj生成元特征 F m j F_{mj} Fmj,即 F m j = M F G ( F u j , F e j ) F_{mj} = MFG(F_{uj}, F_{ej}) Fmj=MFG(Fuj,Fej),其中j是特征层级索引。特征变换 F T FT FT通过生成特征桥接 F t j F_{tj} Ftj,将元特征 F m j F_{mj} Fmj转换为融合特征 F u j F_{uj} Fuj。具体而言,元特征嵌入学习分为两个阶段:内部更新阶段和外部更新阶段,如图3所示。
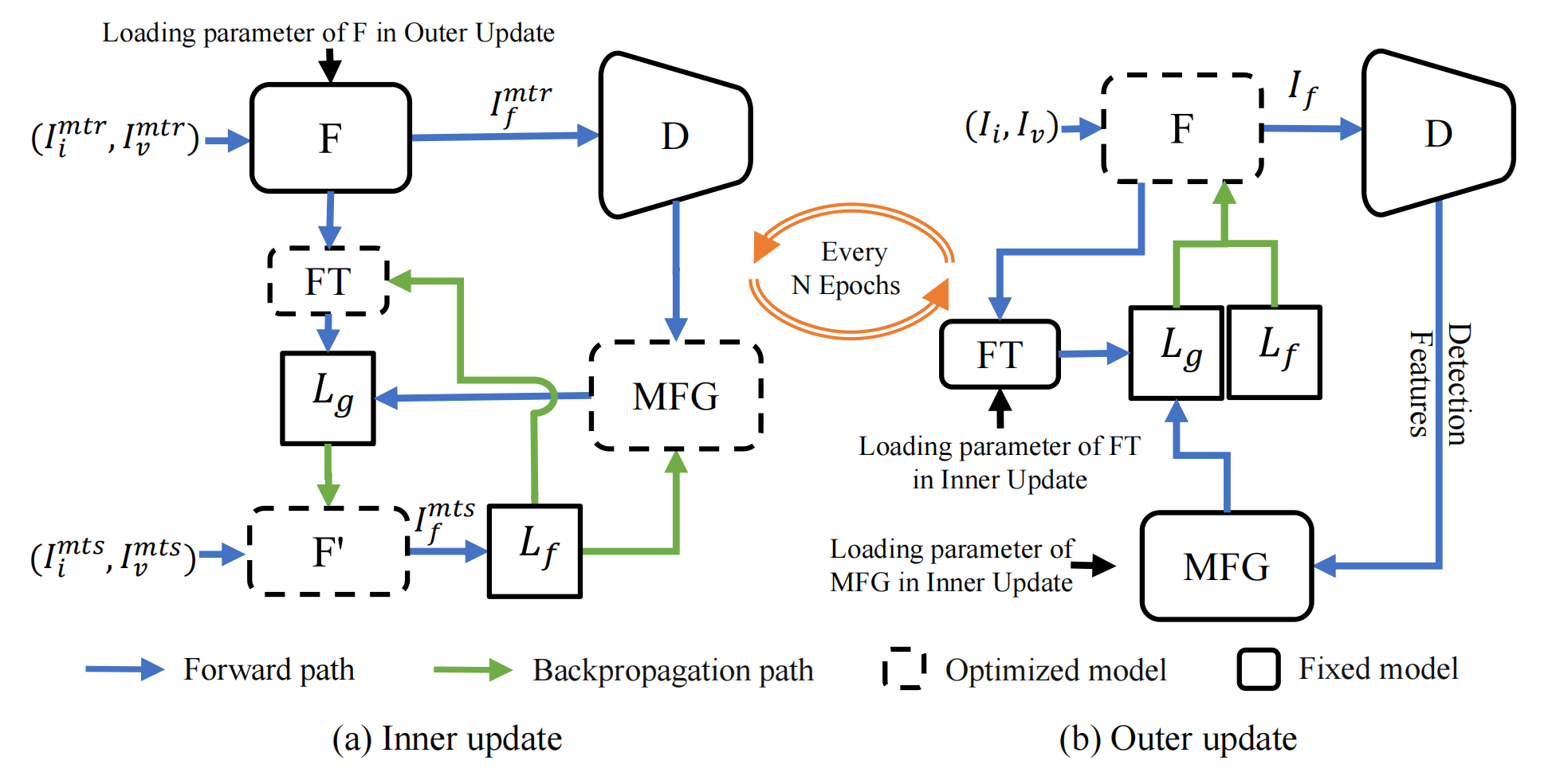
内部更新阶段
在内部更新阶段,我们优化 M F G MFG MFG、 F T FT FT 和 F F F(见图 3(a))。给定元训练集 S m t r S_{m t r} Smtr 和元测试集 S m t s S_{m t s} Smts,我们首先在 S m t r S_{m t r} Smtr 上通过元特征引导来更新 F F F 的参数 θ F \theta_{F} θF。
θ
F
′
=
θ
F
−
β
F
′
∇
θ
F
L
g
(
F
m
j
,
F
t
j
)
=
θ
F
−
β
F
′
∂
L
g
(
F
m
j
,
F
t
j
)
∂
θ
F
(1)
\theta_{F'}=\theta_{F}-\beta_{F'} \nabla_{\theta_{F}} L_{g}(F_{m j}, F_{t j})=\theta_{F}-\beta_{F'} \frac{\partial L_{g}(F_{m j}, F_{t j})}{\partial \theta_{F}} \tag{1}
θF′=θF−βF′∇θFLg(Fmj,Ftj)=θF−βF′∂θF∂Lg(Fmj,Ftj)(1)
其中,引导损失
L
g
L_{g}
Lg 是
L
2
L_2
L2 距离,
β
F
′
\beta_{F'}
βF′ 是
F
′
F'
F′ 的学习率,
θ
F
′
\theta_{F'}
θF′ 是由
F
F
F 更新得到的
F
′
F'
F′ 的参数。
然后,使用参数为
θ
F
′
\theta_{F'}
θF′ 的
F
′
F'
F′ 在元测试集
S
m
t
s
S_{mts}
Smts 上计算融合损失
L
f
L_{f}
Lf。
L
f
L_{f}
Lf 可衡量使用元特征引导
F
F
F 的效果,
L
f
L_{f}
Lf 越低,
F
F
F 的语义提取能力越强。利用
L
f
L_{f}
Lf 更新
M
F
G
MFG
MFG 的参数
θ
M
F
G
\theta_{MFG}
θMFG 和
F
T
FT
FT 的参数
θ
F
T
\theta_{FT}
θFT:
θ
M
F
G
=
θ
M
F
G
−
β
M
F
G
∇
θ
M
F
G
L
f
(
I
f
m
t
s
,
I
i
m
t
s
,
I
v
m
t
s
)
(2)
\theta_{MFG}=\theta_{MFG}-\beta_{MFG} \nabla_{\theta_{MFG}} L_{f}(I_{f}^{mts}, I_{i}^{mts}, I_{v}^{mts}) \tag{2}
θMFG=θMFG−βMFG∇θMFGLf(Ifmts,Iimts,Ivmts)(2)
θ
F
T
=
θ
F
T
−
β
F
T
∇
θ
F
T
L
f
(
I
f
m
t
s
,
I
i
m
t
s
,
I
v
m
t
s
)
(3)
\theta_{FT}=\theta_{FT}-\beta_{FT} \nabla_{\theta_{FT}} L_{f}(I_{f}^{mts}, I_{i}^{mts}, I_{v}^{mts}) \tag{3}
θFT=θFT−βFT∇θFTLf(Ifmts,Iimts,Ivmts)(3)
这里,融合损失
L
f
L_{f}
Lf 是 SSIM 损失 [38],
I
i
m
t
s
I_{i}^{mts}
Iimts 和
I
v
m
t
s
I_{v}^{mts}
Ivmts 是来自
S
m
t
s
S_{mts}
Smts 的红外和可见光图像,
I
f
m
t
s
=
F
′
(
I
i
m
t
s
,
I
v
m
t
s
)
I_{f}^{mts}=F'(I_{i}^{mts}, I_{v}^{mts})
Ifmts=F′(Iimts,Ivmts) 是元测试融合结果,
β
M
F
G
\beta_{MFG}
βMFG 和
β
F
T
\beta_{FT}
βFT 分别是
M
F
G
MFG
MFG 和
F
T
FT
FT 的学习率。
∇
θ
M
F
G
L
f
\nabla_{\theta_{MFG}} L_{f}
∇θMFGLf 可按以下公式计算:
∇
θ
M
F
G
L
f
(
F
′
(
I
i
m
t
s
,
I
v
m
t
s
)
,
I
i
m
t
s
,
I
v
m
t
s
)
=
∂
L
f
(
F
′
(
I
i
m
t
s
,
I
v
m
t
s
)
,
I
i
m
t
s
,
I
v
m
t
s
)
∂
θ
F
′
×
(
−
∂
2
L
g
(
F
m
j
,
F
t
j
)
∂
θ
F
∂
θ
M
F
G
)
(4)
\begin{aligned} \nabla_{\theta_{MFG}} L_{f}(F'(I_{i}^{mts}, I_{v}^{mts}), I_{i}^{mts}, I_{v}^{mts}) &=\frac{\partial L_{f}(F'(I_{i}^{mts}, I_{v}^{mts}), I_{i}^{mts}, I_{v}^{mts})}{\partial \theta_{F'}} \times \left(-\frac{\partial^{2} L_{g}(F_{m j}, F_{t j})}{\partial \theta_{F} \partial \theta_{MFG}}\right) \end{aligned} \tag{4}
∇θMFGLf(F′(Iimts,Ivmts),Iimts,Ivmts)=∂θF′∂Lf(F′(Iimts,Ivmts),Iimts,Ivmts)×(−∂θF∂θMFG∂2Lg(Fmj,Ftj))(4)
同理,
∇
θ
F
T
L
f
\nabla_{\theta_{FT}} L_{f}
∇θFTLf 可按以下公式计算:
∇
θ
F
T
L
f
(
F
′
(
I
i
m
t
s
,
I
v
m
t
s
)
,
I
i
m
t
s
,
I
v
m
t
s
)
=
∂
L
f
(
F
′
(
I
i
m
t
s
,
I
v
m
t
s
)
,
I
i
m
t
s
,
I
v
m
t
s
)
∂
θ
F
′
×
(
−
∂
2
L
g
(
F
m
j
,
F
t
j
)
∂
θ
F
∂
θ
F
T
)
(5)
\begin{aligned} \nabla_{\theta_{FT}} L_{f}(F'(I_{i}^{mts}, I_{v}^{mts}), I_{i}^{mts}, I_{v}^{mts}) &=\frac{\partial L_{f}(F'(I_{i}^{mts}, I_{v}^{mts}), I_{i}^{mts}, I_{v}^{mts})}{\partial \theta_{F'}} \times \left(-\frac{\partial^{2} L_{g}(F_{m j}, F_{t j})}{\partial \theta_{F} \partial \theta_{FT}}\right) \end{aligned} \tag{5}
∇θFTLf(F′(Iimts,Ivmts),Iimts,Ivmts)=∂θF′∂Lf(F′(Iimts,Ivmts),Iimts,Ivmts)×(−∂θF∂θFT∂2Lg(Fmj,Ftj))(5)
这样,
M
F
G
MFG
MFG 能根据当前
F
′
F'
F′ 的语义提取能力学习生成与
F
F
F 兼容的元特征。
外部更新阶段
在外部更新阶段,使用初始参数
θ
F
\theta_{F}
θF 训练
F
F
F。给定训练数据
S
=
{
S
m
t
r
,
S
m
t
s
}
S = \{S_{mtr}, S_{mts}\}
S={Smtr,Smts},通过融合损失
L
f
L_{f}
Lf 和引导损失
L
g
L_{g}
Lg 优化
F
F
F 的参数
θ
F
\theta_{F}
θF:
θ
F
=
θ
F
−
β
F
∇
θ
F
(
L
f
(
I
f
,
I
i
,
I
v
)
+
λ
g
∑
j
=
1
3
L
g
(
F
m
j
,
F
t
j
)
)
=
θ
F
−
β
F
(
∂
L
f
(
I
f
,
I
i
,
I
v
)
∂
θ
F
+
λ
g
∑
j
=
1
3
∂
L
g
(
F
m
j
,
F
t
j
)
∂
θ
F
)
(6)
\begin{aligned} \theta_{F} &= \theta_{F} - \beta_{F} \nabla_{\theta_{F}} \left( L_{f}(I_{f}, I_{i}, I_{v}) + \lambda_{g} \sum_{j = 1}^{3} L_{g}(F_{m j}, F_{t j}) \right) \\ &= \theta_{F} - \beta_{F} \left( \frac{\partial L_{f}(I_{f}, I_{i}, I_{v})}{\partial \theta_{F}} + \lambda_{g} \sum_{j = 1}^{3} \frac{\partial L_{g}(F_{m j}, F_{t j})}{\partial \theta_{F}} \right) \end{aligned} \tag{6}
θF=θF−βF∇θF(Lf(If,Ii,Iv)+λgj=1∑3Lg(Fmj,Ftj))=θF−βF(∂θF∂Lf(If,Ii,Iv)+λgj=1∑3∂θF∂Lg(Fmj,Ftj))(6)
其中,
I
i
I_{i}
Ii 和
I
v
I_{v}
Iv 是来自
S
S
S 的红外和可见光图像,
λ
g
\lambda_{g}
λg 是平衡
L
f
L_{f}
Lf 和
L
g
L_{g}
Lg 的超参数,
β
F
\beta_{F}
βF 是
F
F
F 的学习率。
交替更新
最后,内部更新阶段和外部更新阶段每 N N N 个训练轮次交替进行,以提高对 M F G MFG MFG 和 F F F 的优化效果。
2.2相互促进学习
在 2.1 节中固定了目标检测网络 D D D,以便提供稳定的目标语义特征。通过这种方式, M F G MFG MFG 无需处理变化的目标语义特征,从而降低了训练 M F G MFG MFG 的难度。
然而,固定的 D D D 会限制 F F F 的目标语义提取能力。为解决这个问题,提出了相互促进学习方法,这种方法不仅能提升 F F F,还能提升 D D D,如图 4 所示。
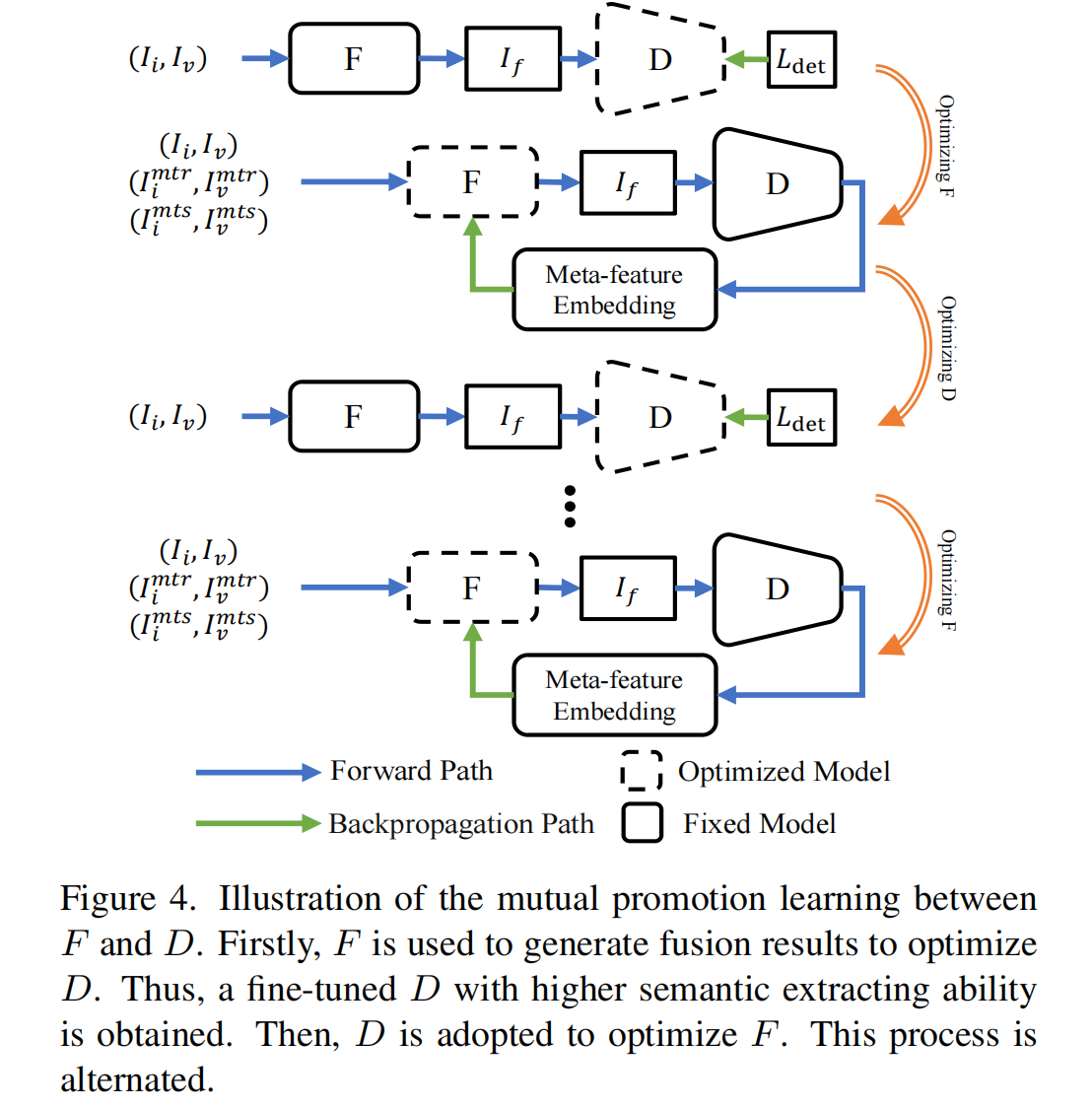
图4. 红外与可见光图像融合网络( F F F)和目标检测网络( D D D)之间相互促进学习的示意图。
首先,利用红外与可见光图像融合网络( F F F)生成融合结果来优化目标检测网络( D D D)。这样,就可以得到一个经过微调且具有更高语义提取能力的目标检测网络( D D D)。
然后,采用目标检测网络( D D D)来优化红外与可见光图像融合网络( F F F)。这个过程是交替进行的。
具体来说,我们首先单独训练 F F F,然后利用融合结果来训练 D D D。接着, D D D 为元特征嵌入提供目标语义特征,从而提升 F F F。之后,由 F F F 生成的改进后的融合结果被用于微调 D D D。通过这种方式, F F F 和 D D D 都得到了提升。
2.3结构
IVIF 网络 F F F 旨在根据输入的红外和可见光图像生成融合结果。 F F F 由三个特征融合块 F F B j FFB_j FFBj, ( j = 1 , 2 , 3 ) (j = 1, 2, 3) (j=1,2,3)和一个图像重建模块 I R M IRM IRM组成,如图 2 所示。
2.3.1 特征融合模块(FFB)
F F B j FFB_j FFBj 用于从输入的红外图像 I i I_i Ii 和可见光图像 I v I_v Iv中提取和融合特征。如果 F F B j FFB_j FFBj 能够很好地融合 I i I_i Ii和 I v I_v Iv的特征,那么这两种特征可以从融合特征中恢复。因此, F F B j FFB_j FFBj描述为:
F F B j = { C 2 T 1 ⊕ C 2 T 1 , j = 1 C 2 T j − 1 ⊕ C 2 T j − 1 , j > 1 (7) FFB_j = \begin{cases} C_{2}T_{1} \mathbin{\text{\(\oplus\)}} C_{2}T_{1}, & j = 1 \\ C_{2}T_{j - 1} \mathbin{\text{\(\oplus\)}} C_{2}T_{j - 1}, & j > 1 \end{cases} \tag{7} FFBj={C2T1⊕C2T1,C2Tj−1⊕C2Tj−1,j=1j>1(7)
其中:
•
C
k
C_k
Ck: 包含
k
k
k 个 “3×3卷积 + ReLU” 层的算子
•
T
j
T_j
Tj: 第
j
j
j 层的特征集成操作,定义为
T
j
=
C
2
(
F
u
(
j
)
)
T_j = C_2(F_{u(j)})
Tj=C2(Fu(j))
•
⊕
\oplus
⊕: 特征通道连接操作
•
F
u
(
j
)
F_{u(j)}
Fu(j): 第
j
j
j 个FFB块的输出特征
当 j = 1 j=1 j=1 时,输入为原始红外和可见光特征;当 j > 1 j>1 j>1 时,输入为前一层的融合特征 F u ( j − 1 ) F_{u(j-1)} Fu(j−1)。
2.3.2 目标检测网络(D)
目标检测网络 D D D 提供目标语义特征。在我们的框架中,我们选择 y o l o v 5 s yolov5s yolov5s 作为我们的 D D D。根据特征图的大小, D D D 的主干被分为三个特征提取块 { D F B i , i = 1 , 2 , 3 } \{DFB_i, i = 1, 2, 3\} {DFBi,i=1,2,3}。此外,我们将 y o l o v 5 s yolov5s yolov5s 中的颈部和检测头表示为一个块 D H DH DH以简化表达。
2.3.3 元特征嵌入网络(MFE)
MFE通过跨模态语义对齐生成元特征,包含:
-
元特征生成器 M F G j MFG_j MFGj:
M F G j = C 6 ( C 4 ( F u j ) ⊕ C 2 ( Up ( F e j ) ) ) MFG_j = C_6\left(C_4(F_{uj}) \oplus C_2(\text{Up}(F_{ej}))\right) MFGj=C6(C4(Fuj)⊕C2(Up(Fej)))
其中:
• F e j F_{ej} Fej: DFB_j输出的目标语义特征
• F u j F_{uj} Fuj: 对应的场景细节特征
• Up ( ⋅ ) \text{Up}(\cdot) Up(⋅): 双线性插值上采样 -
特征变换网络 F T j FT_j FTj:由3个 “3×3卷积 + ReLU” 层构成,实现元特征到融合特征的映射
2.4训练
我们框架的训练细节如算法1所示,它包含四个步骤:首先对 F F F进行预训练,然后使用融合结果对 D D D进行微调;接着训练 F T FT FT和 M F G MFG MFG,其中 M F G MFG MFG和 F T FT FT每 N = 8 N = 8 N=8个训练轮次更新 n = 200 n = 200 n=200次;最后通过 R = 2 R = 2 R=2轮的相互促进训练增强 F F F和 D D D的性能。
3. 实验
3.1. 实验设置
数据集:我们在三个广泛使用的数据集上进行实验:M3FD [20]、RoadScene [44] 和 TNO [37]。M3FD 被划分为训练集(2940 对图像)和测试集(1260 对图像);RoadScene(221 对图像)和 TNO(40 对图像)仅用于测试。M3FD 同时用于评估目标检测(OD)性能。
实现细节:
- 框架基于 PyTorch 实现,部署于 NVIDIA GeForce RTX 3090 GPU
- 优化器配置:
- 对 F F F 和元特征嵌入网络( M F E MFE MFE)使用 Adam 优化器,学习率 β F = β F ′ = β F T = β M F G = 1 × 1 0 − 3 \beta_F=\beta_{F'}=\beta_{FT}=\beta_{MFG}=1\times10^{-3} βF=βF′=βFT=βMFG=1×10−3
- 判别器 D D D 遵循 YOLOv5s 配置,采用 SGD 优化器(学习率 1 × 1 0 − 2 1\times10^{-2} 1×10−2,每轮衰减 0.1)
- 训练流程:
- 预训练 F F F(100 轮)和 D D D(150 轮)
- 微调 M F E MFE MFE(50 轮)
- 对 D D D 进行第二阶段微调(150 轮)
- 执行 R R R 轮相互促进训练
- 数据预处理:图像统一缩放至 512 × 384 512\times384 512×384,批量大小设为 1
- 关键超参数: λ g = 0.1 \lambda_g=0.1 λg=0.1

元融合训练算法演示
以下是整理后的评价指标描述,采用分层结构和规范排版:
3.2评价指标
本实验采用双维度评价方案:图像融合质量评价和目标检测性能评价。
3.2.1 图像融合质量评价
采用三种经典指标量化IVIF效果,所有计算均在HSV颜色空间的V通道进行:
-
熵(Entropy, EN)
E N = − ∑ i = 0 L − 1 p ( i ) log 2 p ( i ) EN = -\sum_{i=0}^{L-1} p(i)\log_2 p(i) EN=−i=0∑L−1p(i)log2p(i)
衡量融合图像的信息丰富度,值域[0, log₂L],值越大表明信息量越丰富 -
互信息(Mutual Information, MI)
M I = ∑ x , y ∑ a , b p I s , I f ( a , b ∣ x , y ) log 2 p I s , I f ( a , b ∣ x , y ) p I s ( a , b ) p I f ( x , y ) MI = \sum_{x,y} \sum_{a,b} p_{I_s,I_f}(a,b|x,y)\log_2\frac{p_{I_s,I_f}(a,b|x,y)}{p_{I_s}(a,b)p_{I_f}(x,y)} MI=x,y∑a,b∑pIs,If(a,b∣x,y)log2pIs(a,b)pIf(x,y)pIs,If(a,b∣x,y)
衡量输入图像与融合图像间的信息共享量,值越大表明融合过程保留了更多源图像信息 -
视觉信息保真度(Visual Information Fidelity, VIF)
V I F = ∑ i ∈ V σ I s , i 2 ∑ i ∈ V σ I s , i 2 + σ n , i 2 VIF = \frac{\sum_{i\in V}\sigma_{I_s,i}^2}{\sum_{i\in V}\sigma_{I_s,i}^2 + \sigma_{n,i}^2} VIF=∑i∈VσIs,i2+σn,i2∑i∈VσIs,i2
通过对比可见分量与噪声分量评估保真度,值域[0,1],值越大表明可见信息失真越小
注: I s I_s Is表示源图像, I f I_f If表示融合图像, V V V指HSV的亮度通道, σ 2 \sigma^2 σ2表示方差
3.2.2 目标检测性能评价
采用改进型平均精度指标:
• mAP50→95 [9]
计算方式:
mAP
50
→
95
=
1
10
∑
i
=
50
95
AP
i
\text{mAP}_{50→95} = \frac{1}{10}\sum_{i=50}^{95} \text{AP}_i
mAP50→95=101∑i=5095APi
通过逐步提高IoU阈值(从0.5到0.95,步长0.05)计算平均精度,值域[0,1],值越高表明检测性能越优
3.3消融研究
元特征嵌入的效果
元特征嵌入,它从目标检测特征中生成元特征,以帮助红外与可见光图像融合(IVIF)网络学习更多的目标语义信息。
为了验证其效果,将单独优化方法(SoFusion)和级联优化方法(CoFusion)进行了比较,如图1(a)-(b)所示。
具体来说,SoFusion首先优化网络
F
F
F,然后使用生成的融合结果来优化网络
D
D
D。CoFusion将
D
D
D视为一种约束,通过损失
L
f
L_f
Lf和
L
d
L_d
Ld来优化
F
F
F。结果如表1所示。
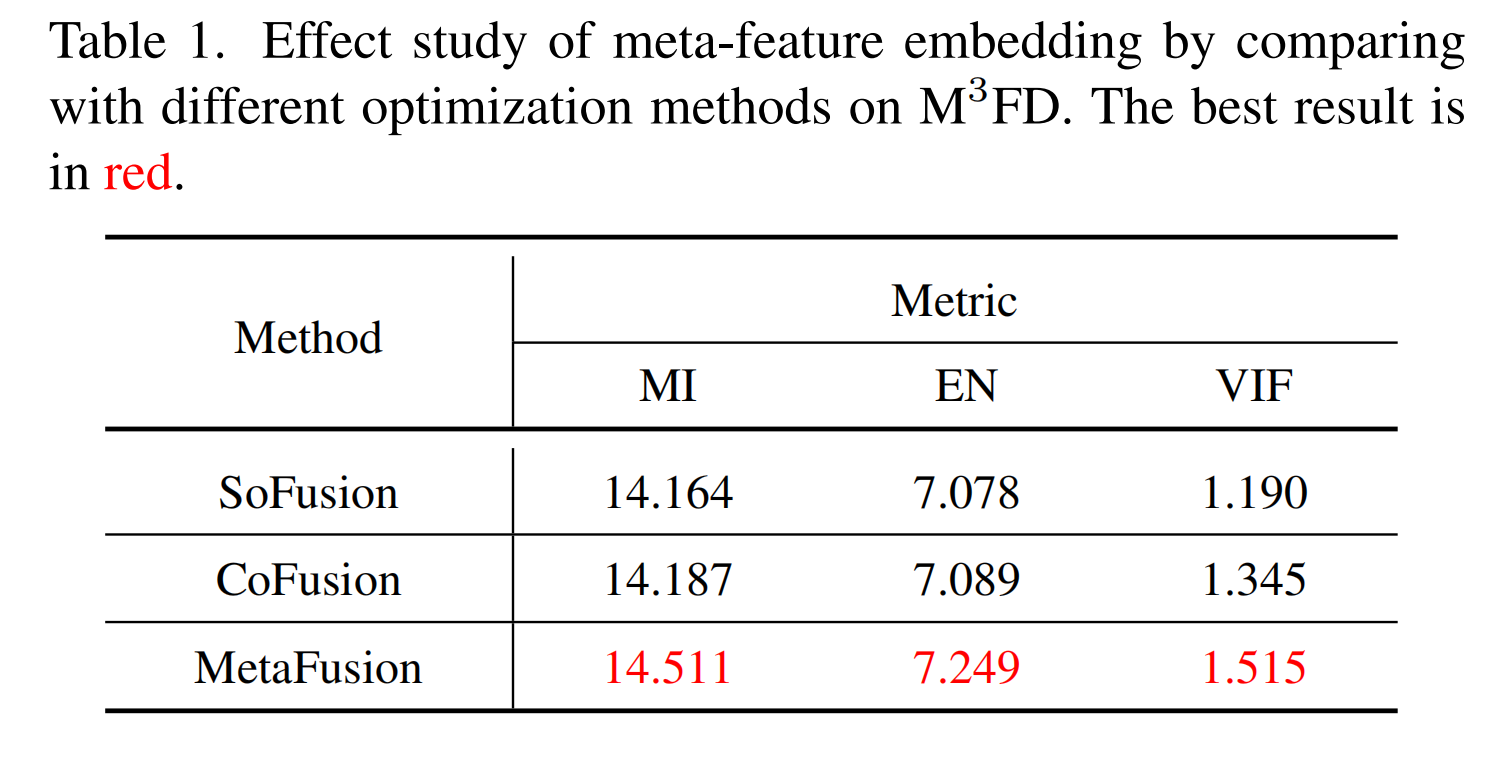
表 1. 通过在 M 3 F D M^{3}FD M3FD数据集上与不同优化方法进行比较来研究元特征嵌入的效果。最佳结果以红色显示。
MetaFusion在IVIF任务上取得了最佳结果。原因是SoFusion忽略了
D
D
D的帮助,而在CoFusion中,直接利用高层的
D
D
D来指导像素级的
F
F
F存在特征不匹配的问题。相比之下,我们实现的元特征嵌入会根据
F
F
F的能力从
D
D
D生成元特征。
因此,这些元特征与
F
F
F自然兼容,从而为
F
F
F提供了有效的目标语义特征。可视化比较如图5所示。MetaFusion突出了目标特征,并生成了最清晰的结果。

图 5. 不同优化方法的可视化对比。
相互促进学习的影响
相互促进学习方法,交替提升 F F F和 D D D。在这里,我们通过评估 R = 0 R = 0 R=0、 1 1 1、 2 2 2轮次来研究相互促进学习的影响。特别地, R = 0 R = 0 R=0表示分别训练 F F F和 D D D。如表2所示,随着 R R R的增加, F F F的结果越来越好。综合考虑训练效率和性能,我们选择 R = 2 R = 2 R=2。
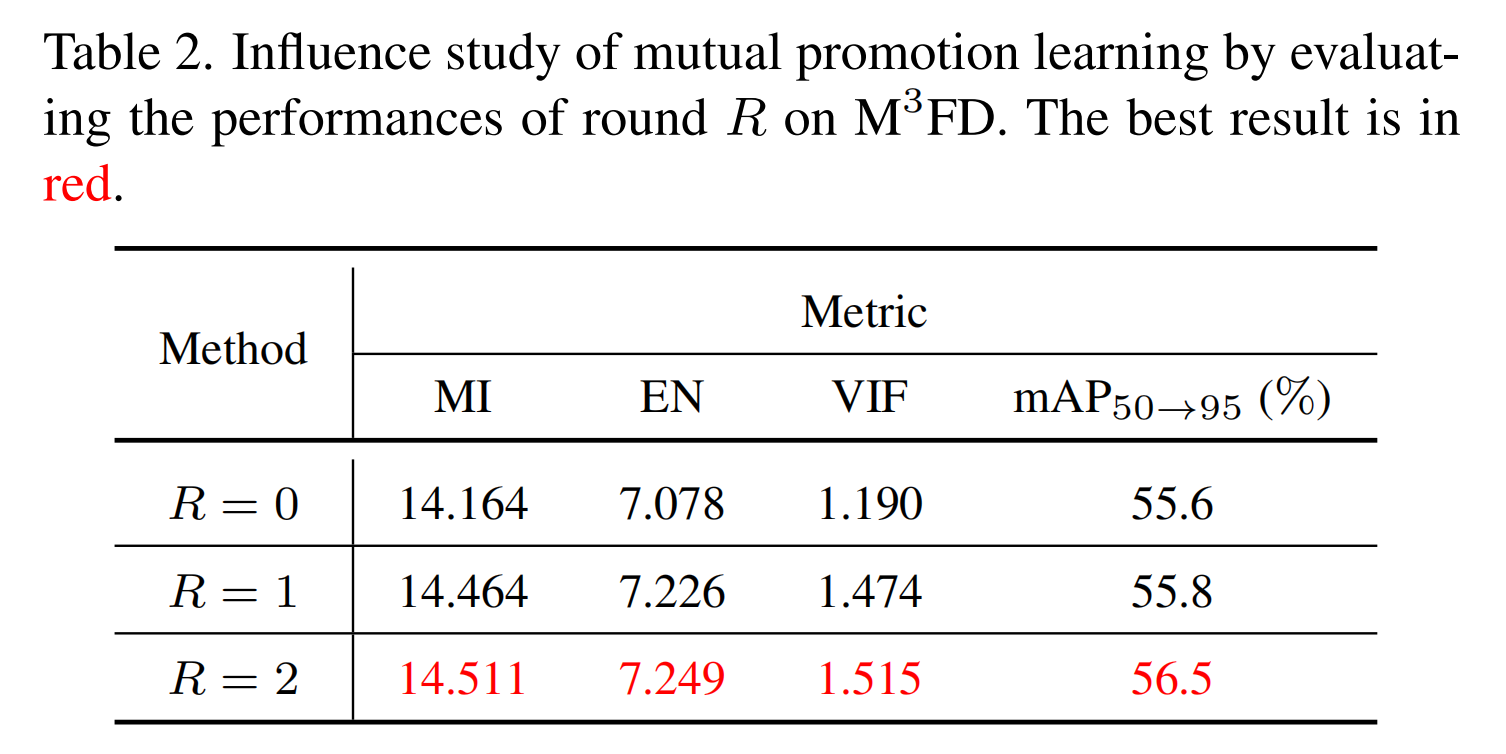
表2. 通过评估在 M 3 F D M^{3}FD M3FD数据集上不同轮次(R)的性能来研究相互促进学习的影响。最佳结果以红色显示。
多层次元特征嵌入的研究
多层次元特征嵌入来构建MetaFusion框架。在这里,我们通过以下配置来研究元特征嵌入的层数。
- 一层元特征嵌入(MetaFusion-L1): M F E = { M F G 1 , F T 1 } MFE = \{MFG_1, FT_1\} MFE={MFG1,FT1}, F = { F F B 1 , I R M } F = \{FFB_1, IRM\} F={FFB1,IRM}, D = { D F B 1 , D H } D = \{DFB_1, DH\} D={DFB1,DH}。
- 两层元特征嵌入(MetaFusion-L2): M F E = { M F G 1 , M F G 2 , F T 1 , F T 2 } MFE = \{MFG_1, MFG_2, FT_1, FT_2\} MFE={MFG1,MFG2,FT1,FT2}, F = { F F B 1 , F F B 2 , I R M } F = \{FFB_1, FFB_2, IRM\} F={FFB1,FFB2,IRM}, D = { D F B 1 , D F B 2 , D H } D = \{DFB_1, DFB_2, DH\} D={DFB1,DFB2,DH}。
- 三层元特征嵌入(MetaFusion-L3): M F E = { M F G 1 , M F G 2 , M F G 3 , F T 1 , F T 2 , F T 3 } MFE = \{MFG_1, MFG_2, MFG_3, FT_1, FT_2, FT_3\} MFE={MFG1,MFG2,MFG3,FT1,FT2,FT3}, F = { F F B 1 , F F B 2 , F F B 3 , I R M } F = \{FFB_1, FFB_2, FFB_3, IRM\} F={FFB1,FFB2,FFB3,IRM}, D = { D F B 1 , D F B 2 , D F B 3 , D H } D = \{DFB_1, DFB_2, DFB_3, DH\} D={DFB1,DFB2,DFB3,DH}。
结果如表3所示。随着多层次元特征嵌入层数的增加, F F F实现了更高的图像融合质量。因为元特征嵌入为 F F F提供了多层次的目标语义特征。
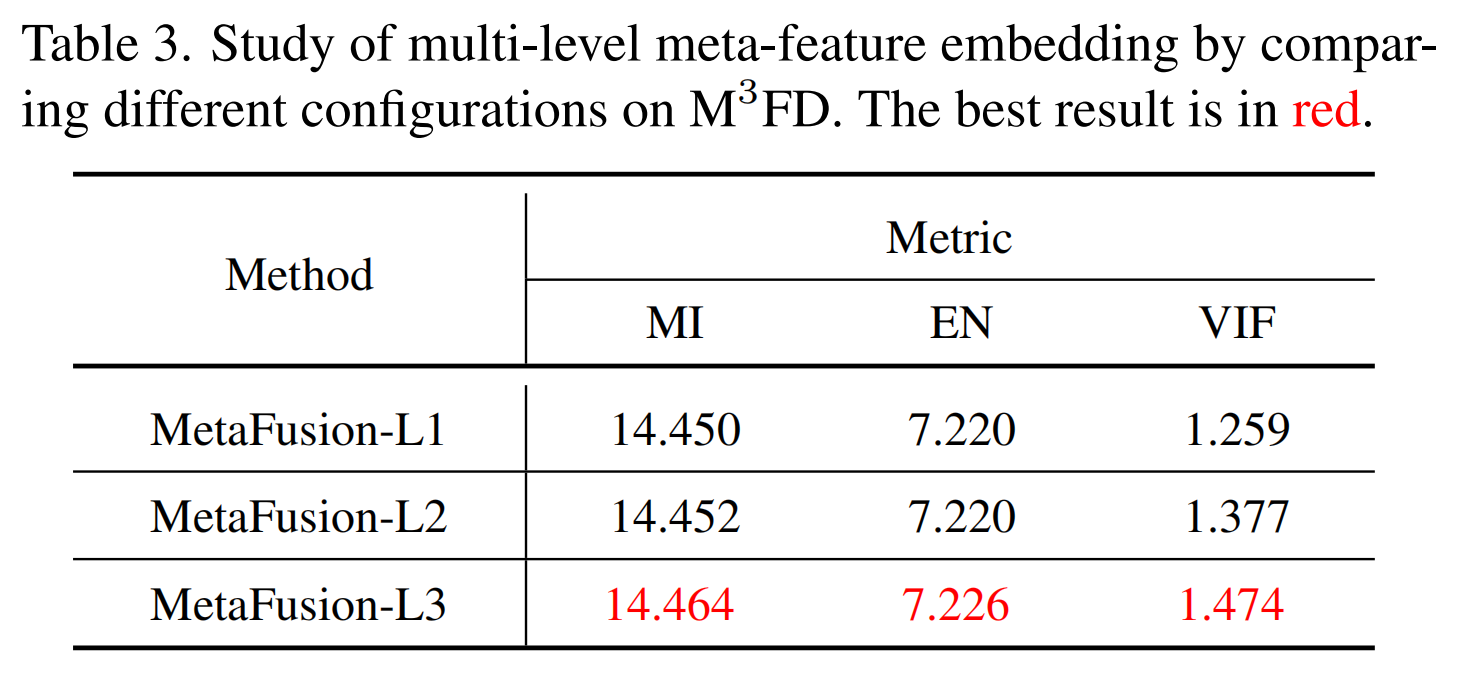
表3. 通过在 M 3 F D M^{3}FD M3FD 数据集上比较不同的配置来研究多层次元特征嵌入的情况。最佳结果以红色显示。
3.4与当前最优方法的比较
我们将所提出的MetaFusion与八种当前最优的融合方法进行比较,以验证其优越性。
这八种方法分别是:FusionGAN 、GANMcC 、MFEIF 、YDTR 、PIAFusion 、SwinFusion 、Tardal 和 U2Fusion 。我们采用了这些方法可用的代码以及推荐的参数设置来生成融合结果,以确保比较的公平性。
不同融合方法的定性结果如图6所示。所有的融合方法在一定程度上都能够融合红外图像和可见光图像的主要特征。然而,FusionGAN、GANMcC、MFEIF 和 YDTR 生成的边缘细节较为模糊,而 U2Fusion、PIAFusion、SwinFusion 和 Tardal 生成的目标对比度较低,如红色矩形框中所示。相比之下,我们提出的 MetaFusion 生成的图像包含清晰的边缘细节和高对比度的目标。

图6. 不同融合方法在 M 3 F D M^{3}FD M3FD数据集(第一组)、RoadScene数据集(第二组)和TNO数据集(第三组)上的定性结果。
接着,我们在表4中给出了不同融合方法的定量结果。我们的 MetaFusion 总体上取得了最大或第二大的指标值。具体来说,较高的熵(EN)和互信息(MI)表明,MetaFusion生成的融合图像包含高对比度的目标和清晰的边缘细节。较大的视觉信息保真度(VIF)值表明,与源图像相比,我们的融合结果具有高质量的视觉效果和较小的失真。此外,我们的方法实现了最快的推理时间,生成一个融合结果仅需0.015秒。
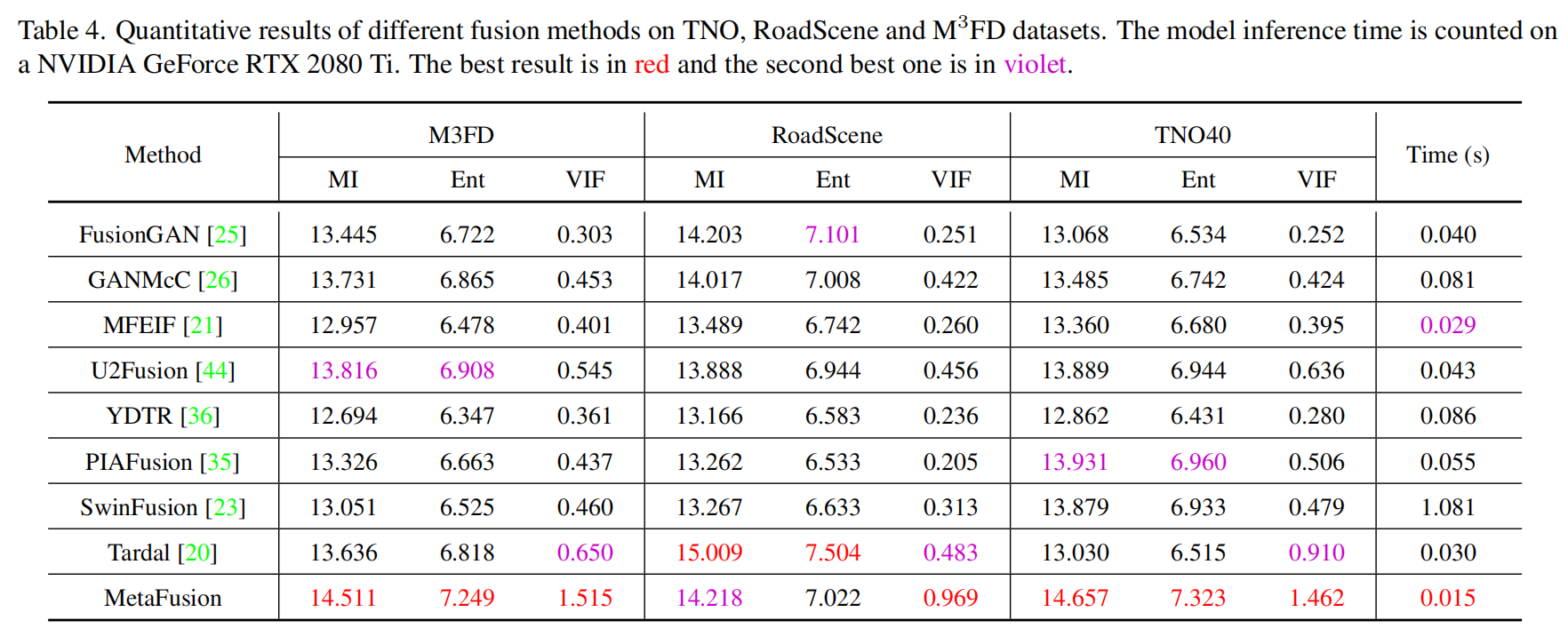
表4. 不同融合方法在TNO、RoadScene和 M 3 F D M^{3}FD M3FD数据集上的定量结果。模型推理时间是在英伟达GeForce RTX 2080 Ti上统计的。最佳结果用红色标注,第二好的结果用紫色标注。
4.总结
本文通过引入元特征嵌入模型,提出了一种联合融合与检测的学习框架。基于元学习的思想,元特征嵌入模型能够根据融合网络的能力生成目标语义特征,从而弥合这两个不同层次任务之间的特征差距。此外,进一步实施了融合任务与检测任务之间的相互促进学习,以提升它们的性能。定量和定性结果均表明,与当前最先进的方法相比,我们的方法具有更优越的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









