






论文阅读 | CVPR2025 | GIFNet:底层任务交互破局One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
)

题目:One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
会议:Computer Vision and Pattern Recognition(CVPR)
论文:https://doi.org/10.48550/arXiv.2502.19854
代码:https://github.com/AWCXV/GIFNet
年份:2025
相关知识
多模态融合任务是指通过整合来自多种数据模态(如文本、图像、音频、视频、传感器数据等)的信息,协同完成特定目标的任务。
数字摄影任务指利用数字设备(如相机、手机)及算法,完成与图像采集、处理、分析相关的任务,涵盖前期拍摄到后期修图的全流程。
多聚焦图像融合MFIF旨在将同一场景下不同聚焦位置的图像(如近景、中景、远景)融合为一张清晰的全聚焦图像,消除单张图像的模糊区域,保留所有细节。
可见光与红外图像融合IVIF,生成一张既能保留可见光色彩信息,又具备红外图像在低光、穿透性强的综合图像。
1.摘要
-
目前的图像融合方法大多优先考虑高级任务,然而,这种高级监督在一定程度上与底层图像融合问题脱节。
-
相比之下,我们建议从数字摄影融合中利用底层视觉任务,通过像素级监督实现有效的特征交互。这种新范式为无监督多模态融合提供了有力指导,而无需依赖抽象语义,增强了任务共享特征学习,从而具有更广泛的适用性。
-
由于混合图像特征和增强的通用表示,所提出的 GIFNet 支持多种融合任务,在已见和未见场景中,单个模型都能实现高性能。
总结:应更注重底层的融合任务来提供监督信号,专注于细节保留和像素级特征对齐。
2.引言
以往的图像融合方法广泛应用多任务学习方法(MTL)。
先进的多模态图像融合研究通常采用的一种方法是利用高级视觉任务的监督信号来指导融合,这些高级模型通常配备一个融合模型,并将融合后的图像作为输入,用于迭代优化融合模型和高级模型。
然而,这种高级监督在一定程度上与底层图像融合问题脱节。(图1)

图 1. 先进多任务融合方法的通用性和效率对比。箭头中的索引是相应方法验证过的融合任务。
-
在处理不同的图像融合任务时,这种间接的方式需要训练一个针对每个任务特定特征的新融合模型。
-
高级下游任务与低级图像融合之间的语义差距,使得高级监督信号在指导以像素为重点的融合学习方面,更倾向于编码与物体类别、形状和场景布局相关的特征,而不是细粒度的图像细节。
结论:这种不匹配导致在不同的融合场景中过度依赖复杂的衔接模块 或计算密集型的预训练模型 (图 1(a)和(b)),这两种方法都资源消耗大,并且在各种融合场景中无法有效泛化。
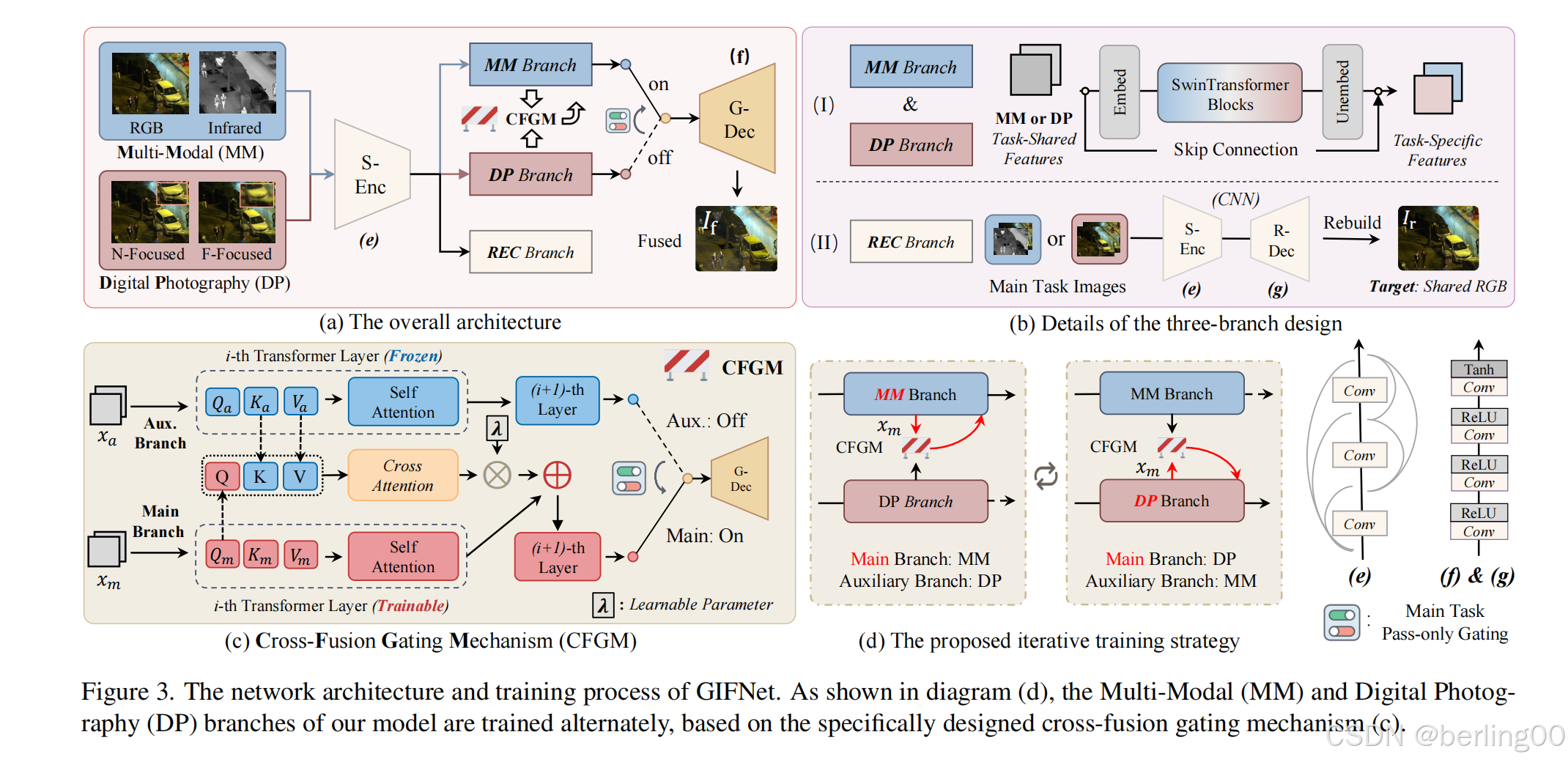
为此,我们引入了广义图像融合网络(GIFNet),这是一种三分支架构,支持底层任务交互以实现有效融合。
GIFNet 包括一个主任务分支、一个辅助任务分支和一个协调分支。主任务分支和辅助任务分支交替关注多模态和数字摄影特征,促进了有效的跨任务交互。
与先进的图像融合方法相比,GIFNet 中底层融合任务的计算成本较低,GFLOPs 降低了 96% 以上。
对于它的结构,我们之后会逐一细说。
-
与目前严重依赖高级视觉任务、优先考虑单一类别融合的方法不同,GIFNet 整合了多模态和数字摄影任务,通过单个模型扩展了其在各种融合场景中的适用性(任务无关的图像融合)。
-
底层任务交互不是放大特定任务的特征,而是增强了对通用图像处理至关重要的任务共享基础特征,使 GIFNet 即使对于单模态输入也能作为通用增强器发挥作用。

与先进的图像融合方法相比,GIFNet 中底层融合任务的计算成本较低,GFLOPs 降低了 96% 以上。且几乎适用于所有的融合场景。
GIFNet 的主要贡献包括:
-
独特地证明了底层融合任务之间的协作训练(一种此前未被重视的策略),通过利用跨任务协同效应,显著提高了性能。
-
引入了重建任务和增强的以 RGB 为重点的联合数据集,以对齐不同融合任务的特征并解决数据支持问题。
-
我们的方法显著增强了融合系统的通用性,无需耗时的特定任务适配。
-
GIFNet 率先将图像融合和单模态增强过程相结合,将图像融合模型的应用范围扩展到多模态领域之外。
3.方法
3.1公式化
图像融合范式通常可定义为:
I f = F ( I 1 , I 2 ) , ( 1 ) I_f = F(I_1, I_2), (1) If=F(I1,I2),(1)
其中 I 1 I_1 I1和 I 2 I_2 I2是输入图像, F F F表示一种图像融合方法, I f I_f If是融合后的图像。
近年来的方法常常将来自高级视觉任务的语义信息整合到多模态图像融合(IVIF)模型中,旨在提高性能。然而,这种范式带来了图像质量下降、计算成本增加以及泛化能力有限的风险(见图1和图2)。

图2. 基于高级任务的先进多任务融合方法与本文提出的底层任务交互范式的对比。前者依赖多模态特征和任务共享特征,聚焦于数字摄影任务共享特征的学习与增强;后者提供像素级监督,能呈现清晰的纹理细节,而那些聚焦语义的范式无法像我们的范式一样始终确保稳健的融合质量。
为此提出了一种新颖的方法,引入了两个创新点。
- 第一个是跨任务交互机制,它利用了各种融合任务中的底层处理操作。
- 具体来说,我们使用数字摄影图像融合任务为无监督的 IVIF 任务提供额外的特定任务特征和监督信号,从而提高融合模型的泛化性和鲁棒性。
- 我们选择多聚焦图像融合(MFIF)作为数字摄影融合的代表性示例来展示我们的 GIFNet 模型,因为在我们的交互消融实验(4.2 节)中,它在可用的融合任务中表现最佳。
- 第二个创新点是融入了单模态图像增强能力。
- 通过引入数字摄影融合任务(一张图像的不同设置),模型学会在不依赖多模态输入的情况下增强特征。通过将两个输入都设置为同一图像,我们模拟了一种类似融合的增强过程,专注于细化单张图像内的细节。这个推理过程可以表示为:
X ^ = F ( X , X ) , ( 2 ) \hat{X}=F(X, X), \quad(2) X^=F(X,X),(2)
其中, X X X 表示单模态输入, X ^ \hat{X} X^ 是增强后的输出。现有图像融合方法的应用仅局限于多模态场景。而这一新特性使我们能够利用增强后的结果来提升主流 RGB 视觉任务的性能。
3.2模型架构
当代图像融合方法由于其单一的网络设计,多个任务依赖于单一的编码器 - 解码器结构,常常在协作学习方面遇到困难。
为了解决这个问题,我们的框架引入了一种三分支架构(如图 3(a)所示)
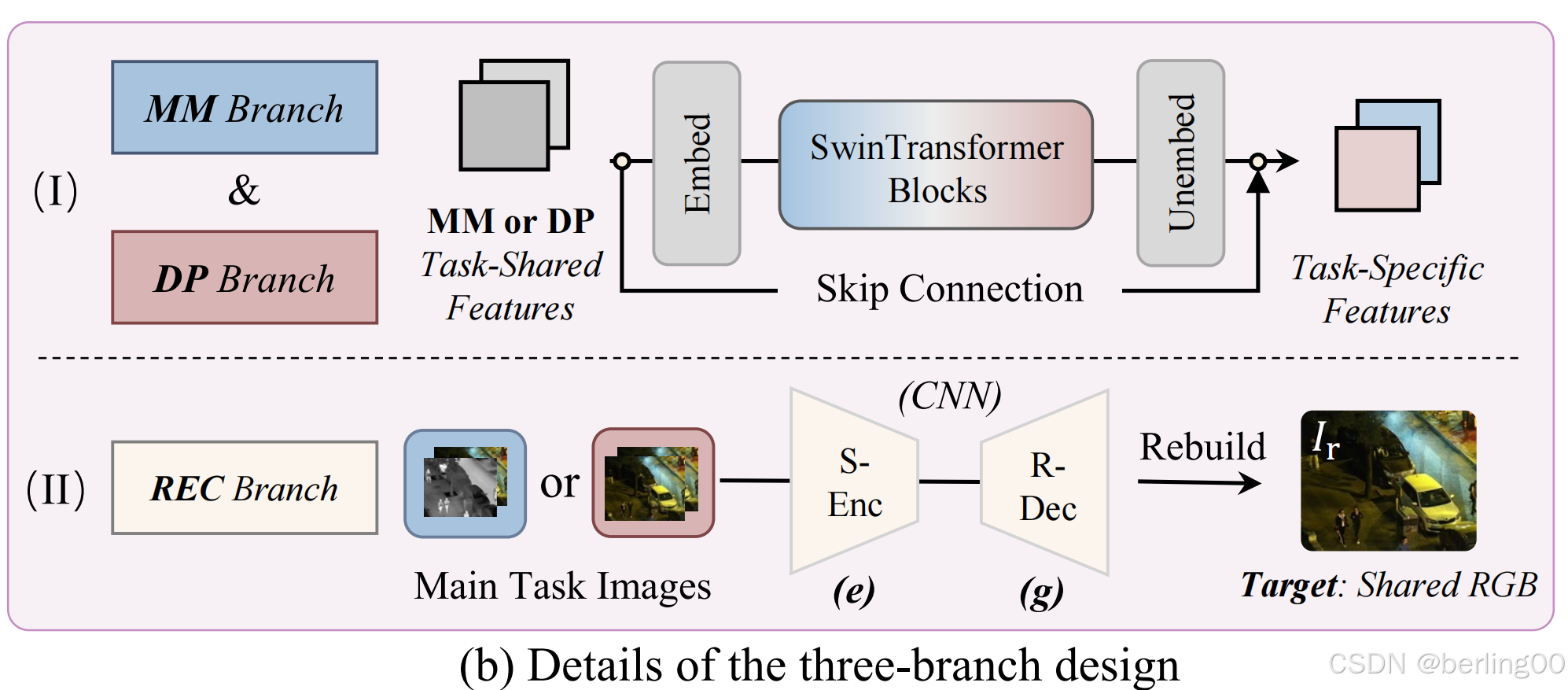
3.2.1三分支架构
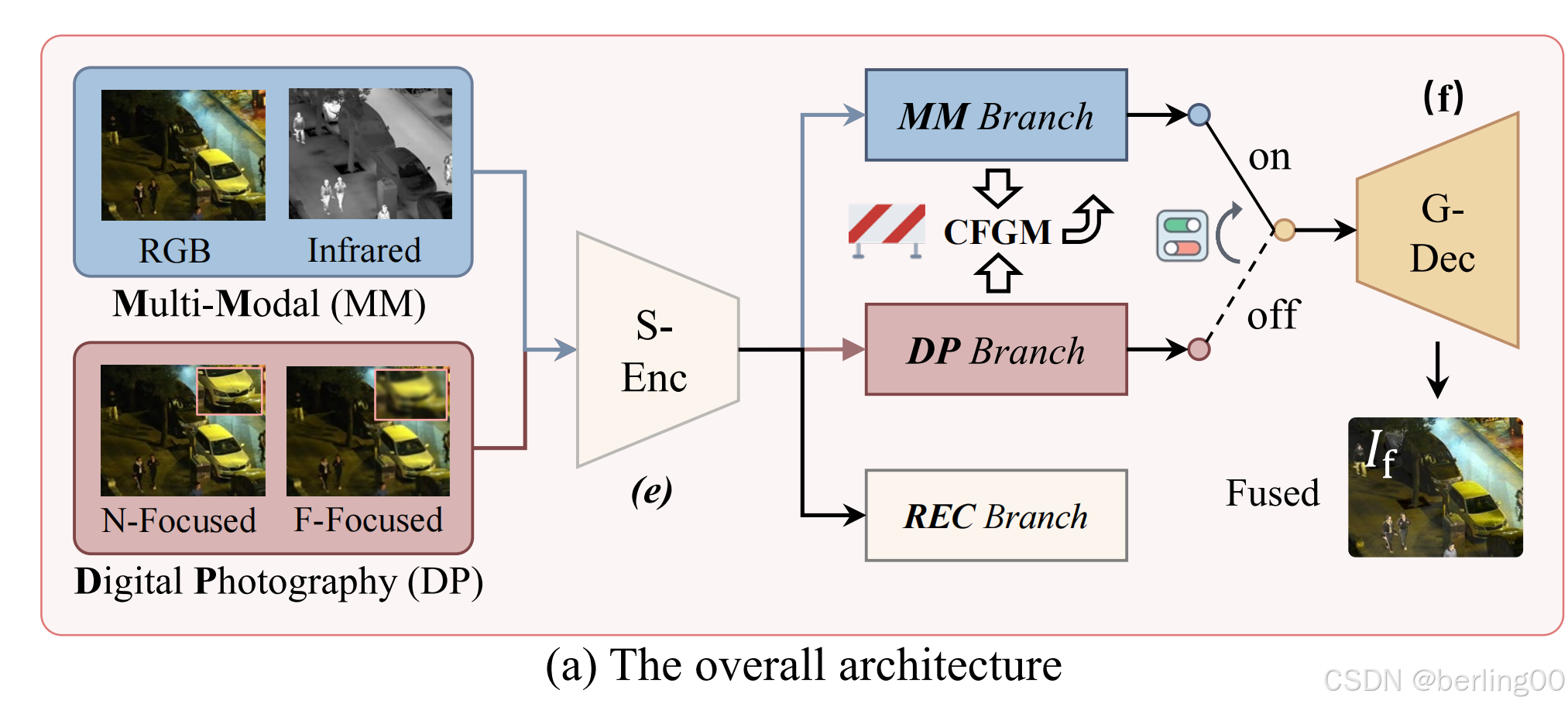
它解耦了特征提取过程,并促进了底层任务之间的交互。在我们的模型中,只有基础特征提取部分在不同任务之间共享。
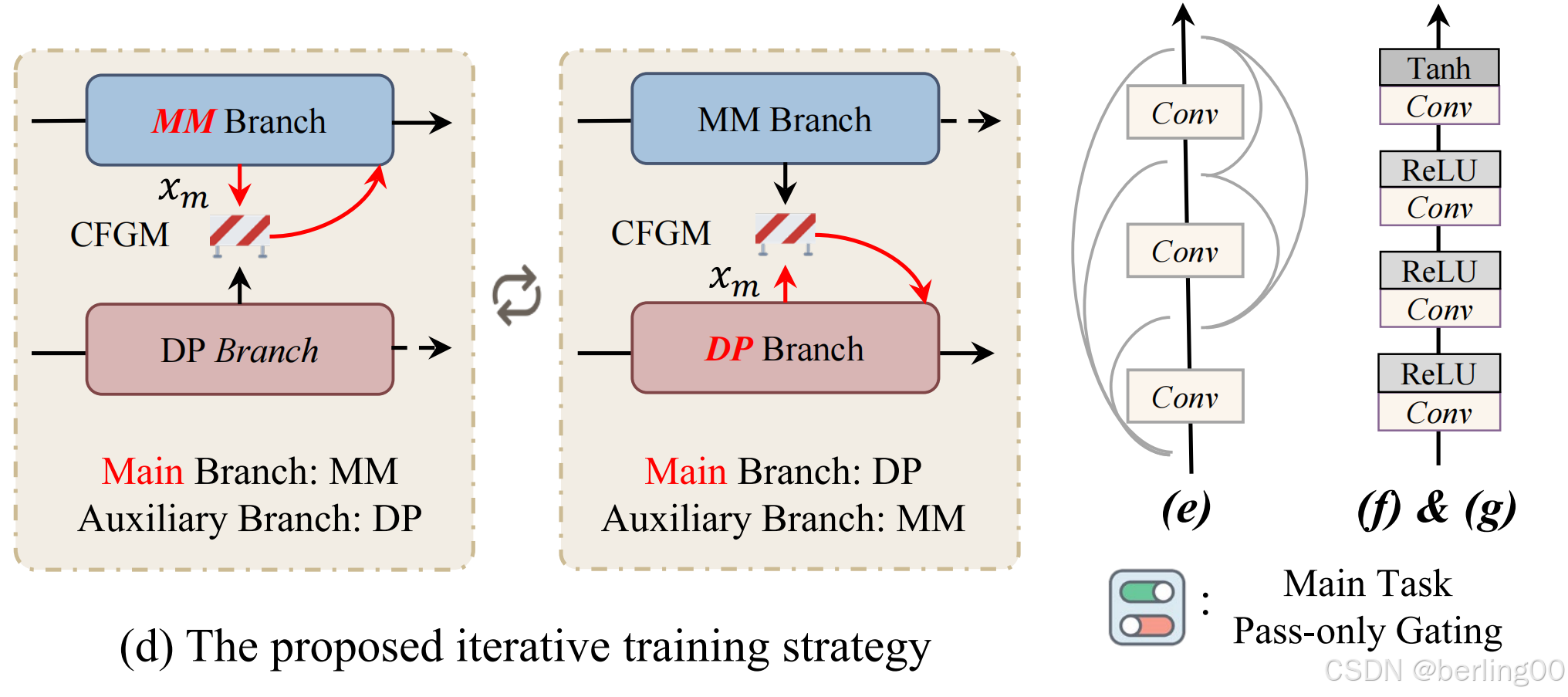
通过关注底层任务之间的交互,我们的方法允许特定任务的特征在网络内直接组合,无需额外的模块来弥合特征或语义差距。这种交互发生在多模态(MM)和数字摄影(DP)分支之间,跨任务机制在主分支和辅助分支之间交替(图 3(d))。
然后,一个门控模块有选择地将主分支的混合特征路由到全局解码器(G-Dec)以生成融合结果。重建(REC)分支通过提取任务无关的特征来支持这一过程。
3.2.2交叉融合门控机制(CFGM):
在获得这些共享特征后,MM 和 DP 分支继续提取不同融合类型的特定任务特征。所提出的交叉融合门控机制(CFGM)是控制这些分支的核心技术,使它们能够融合特定任务的特征,并自适应地稳定跨任务交互。鉴于 SwinTransformer 块具有强大的全局特征提取能力,并且在捕获任务感知特征方面取得了成功 ,我们使用它来构建 CFGM。
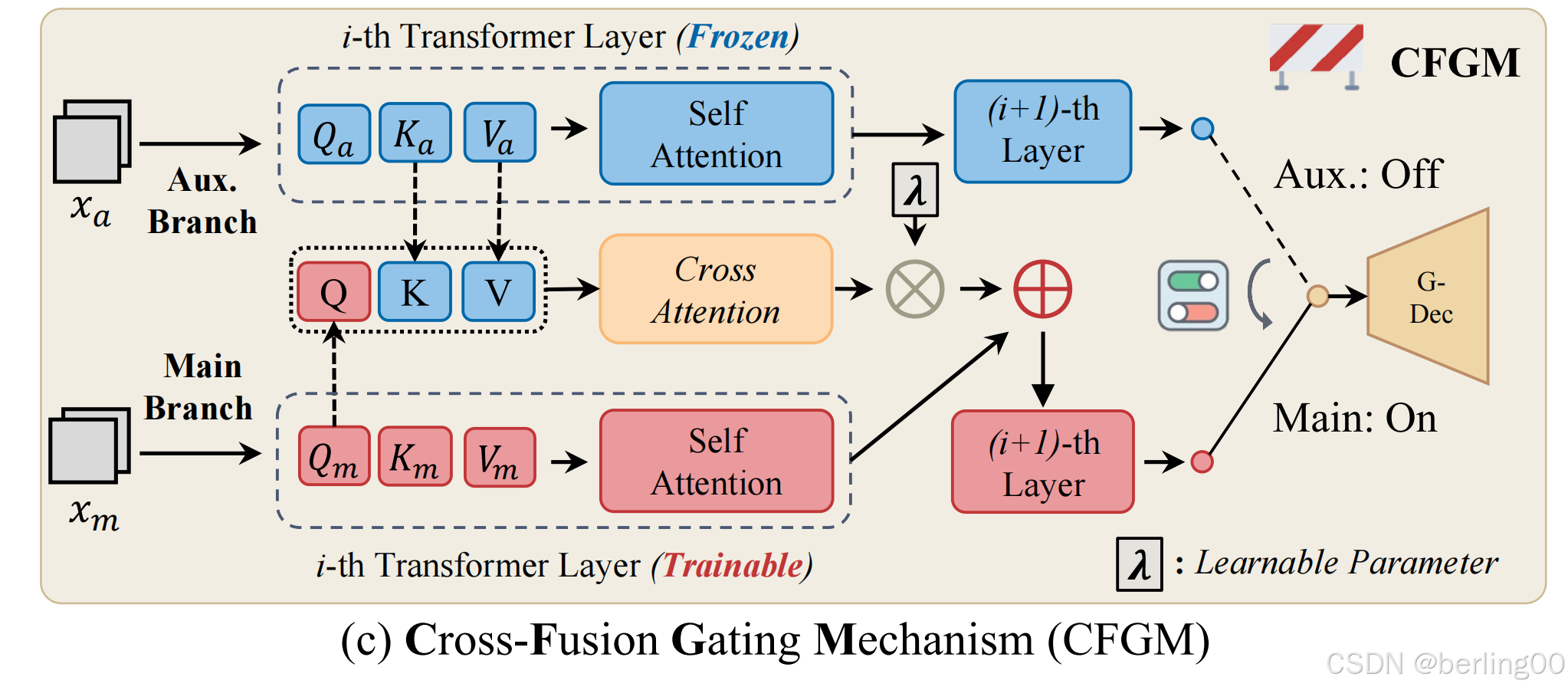
在交叉融合门控机制(CFGM)中,主分支和辅助分支通过交替更新一个分支并冻结另一个分支来进行训练(图3(c))。
3.2.3重建分支(REC):
REC 分支采用自动编码器从各种图像融合任务中导出通用特征(图 3(b)(II))。通过针对增强数据中的共享 RGB 模态进行重建,我们确保了任务共享特征的有效提取。共享编码器(S-Enc)中的密集连接最大化了特征利用率,使原始视觉信号能够传输到其他分支。其中REC分支的输入是主任务图像。
3.3训练操作
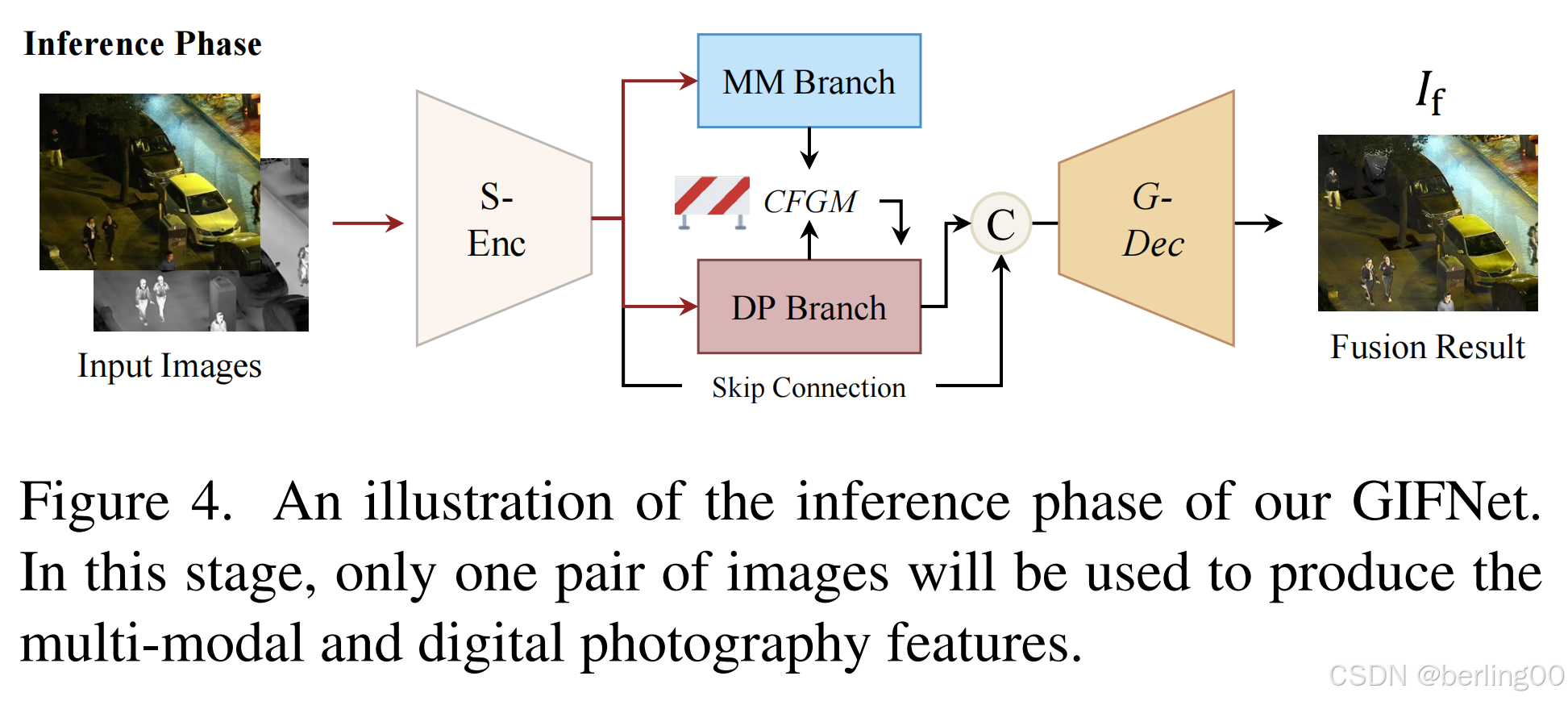
图 4. 我们的广义图像融合网络(GIFNet)推理阶段的示意图。在这个阶段,仅使用一对图像来生成多模态和数字摄影特征。
每个训练步骤中,我们有:
x m ^ = S e l f − A t t ( x m ) , ( 3 ) \hat{x_{m}}=Self-Att\left(x_{m}\right), (3) xm^=Self−Att(xm),(3)
x m = x m ^ + λ ⋅ C r o s s − A t t ( x m ^ , x a ) , ( 4 ) x_{m}=\hat{x_{m}}+\lambda \cdot Cross-Att\left(\hat{x_{m}}, x_{a}\right), \quad(4) xm=xm^+λ⋅Cross−Att(xm^,xa),(4)
其中, x m x_m xm和 x a x_a xa分别表示主任务和辅助任务的表示, λ \lambda λ是一个可学习的参数,用于控制辅助任务的影响程度。Self-Att和Cross-Att分别表示自注意力和交叉注意力操作。交互仅限于奇数层,以避免干扰SwinTransformer的窗口移位操作。
3.4损失函数
在训练过程中,我们采用两个损失函数,即由重建(REC)分支的输出 I r I_{r} Ir和融合图像 I f I_{f} If定义的公共损失 L p u b L_{pub} Lpub和私有损失 L p r i L_{pri} Lpri。每个任务分支的总损失为:
L t o t a l = L p u b + L p r i . ( 5 ) \mathcal{L}_{total }=\mathcal{L}_{pub }+\mathcal{L}_{pri. } (5) Ltotal=Lpub+Lpri.(5)
公共损失 L p u b L_{pub} Lpub通过强制重建(REC)分支输出与共享RGB模态 I v i s I_{vis} Ivis之间的一致性来指导基础特征提取:
L p u b = L s s i m ( I r , I v i s ) + L m s e ( I r , I v i s ) , ( 6 ) \mathcal{L}_{pub }=\mathcal{L}_{ssim }\left(I_{r}, I_{vis }\right)+\mathcal{L}_{mse }\left(I_{r}, I_{vis }\right), \quad(6) Lpub=Lssim(Ir,Ivis)+Lmse(Ir,Ivis),(6)
其中, L s s i m L_{ssim} Lssim和 L m s e L_{mse} Lmse分别表示结构相似性损失和均方误差损失。结构相似性损失定义为:
L s s i m ( I X , I Y ) = 1 − S S I M ( I X , I Y ) . ( 7 ) \mathcal{L}_{ssim }\left(I_{X}, I_{Y}\right)=1-SSIM\left(I_{X}, I_{Y}\right) . (7) Lssim(IX,IY)=1−SSIM(IX,IY).(7)
这里,(SSIM)表示两个图像之间的结构相似性度量。
对于DP分支(MFIF任务),由于增强的MFIF数据来自RGB图像 I v i s I_{vis} Ivis,我们有监督训练的真实标签。因此,该分支的私有损失公式为:
L p r i D P = L m s e ( I f , I v i s ) . ( 11 ) \mathcal{L}_{pri}^{DP}=\mathcal{L}_{mse}\left(I_{f}, I_{vis}\right) . (11) LpriDP=Lmse(If,Ivis).(11)
私有损失是针对每个任务唯一定义的。在迭代的任务交互过程中,只有主任务分支及其私有损失会被优化,而另一个分支则被冻结。请注意,REC分支的输入始终是主任务图像。
对于MM分支(IVIT任务),它要求融合图像保留输入图像中的信息内容,我们采用信息加权损失函数。基于卷积网络的视觉解释研究,特征图的梯度表明特定区域对最终网络决策的贡献程度。使用轻量级DenseNet分类网络,我们确定混合比例 w v i s w_{vis } wvis和 w i r w_{ir } wir:
G r a d F ( X ) = ∑ ∇ ϕ ( X ) , Grad F(X)=\sum \nabla \phi(X), GradF(X)=∑∇ϕ(X),
[ w i r , w v i s ] = s o f t m a x ( G r a d F ( I i r ) , G r a d F ( I v i s ) ) , ( 9 ) \left[w_{ir }, w_{vis }\right]=softmax\left(Grad F\left(I_{ir }\right), Grad F\left(I_{vis }\right)\right), (9) [wir,wvis]=softmax(GradF(Iir),GradF(Ivis)),(9)
其中 p h i ( X ) phi(X) phi(X)表示通过预训练的DenseNet121网络提取的模态&X&的图像特征。然后,MM分支的私有损失定义为:
L p r i M M = w i r ⋅ L m s e ( I f , I i r ) + w v i s ⋅ L m s e ( I f , I v i s ) . ( 10 ) \mathcal{L}_{pri}^{MM}=w_{ir} \cdot \mathcal{L}_{mse}\left(I_{f}, I_{ir}\right)+w_{vis} \cdot \mathcal{L}_{mse}\left(I_{f}, I_{vis}\right) . (10) LpriMM=wir⋅Lmse(If,Iir)+wvis⋅Lmse(If,Ivis).(10)
在推理阶段,与训练过程不同,单个融合任务仅需一对输入图像。我们首先提取共享图像特征,利用交叉融合门控机制(CFGM)融合两组特定表示,最终由全局解码器重建融合图像。该过程无需额外计算或参数更新,确保了实时应用的可行性。
4. 实验结果
4.1 实验设置
我们使用LLVIP数据集进行训练,该数据集包含对齐的红外和可见光图像。通过数据增强(如模糊处理、旋转、翻转)生成额外的MFIF训练样本。评估涵盖7类任务:IVIF(5个数据集)、MFIF(3个数据集)、多曝光融合(MEIF)、近红外(NIR)融合、遥感(RS)融合、医学图像融合(MRI/PET)以及单模态增强任务。采用VIF、SCD、EI、AG等11项指标进行定量评估。
4.2 消融实验
表1展示了不同模块对性能的影响。完整模型(MTL+CFGM+REC)在VIF指标上达到0.897,显著优于基线模型(0.763)。消融CFGM导致VIF下降8.2%,验证了跨任务交互的重要性。REC模块的引入使VIF提升5.4%,表明通用特征对齐的有效性。此外,MFIF辅助任务的效果优于MEIF(VIF 0.897 vs 0.862),证明了任务选择的合理性。
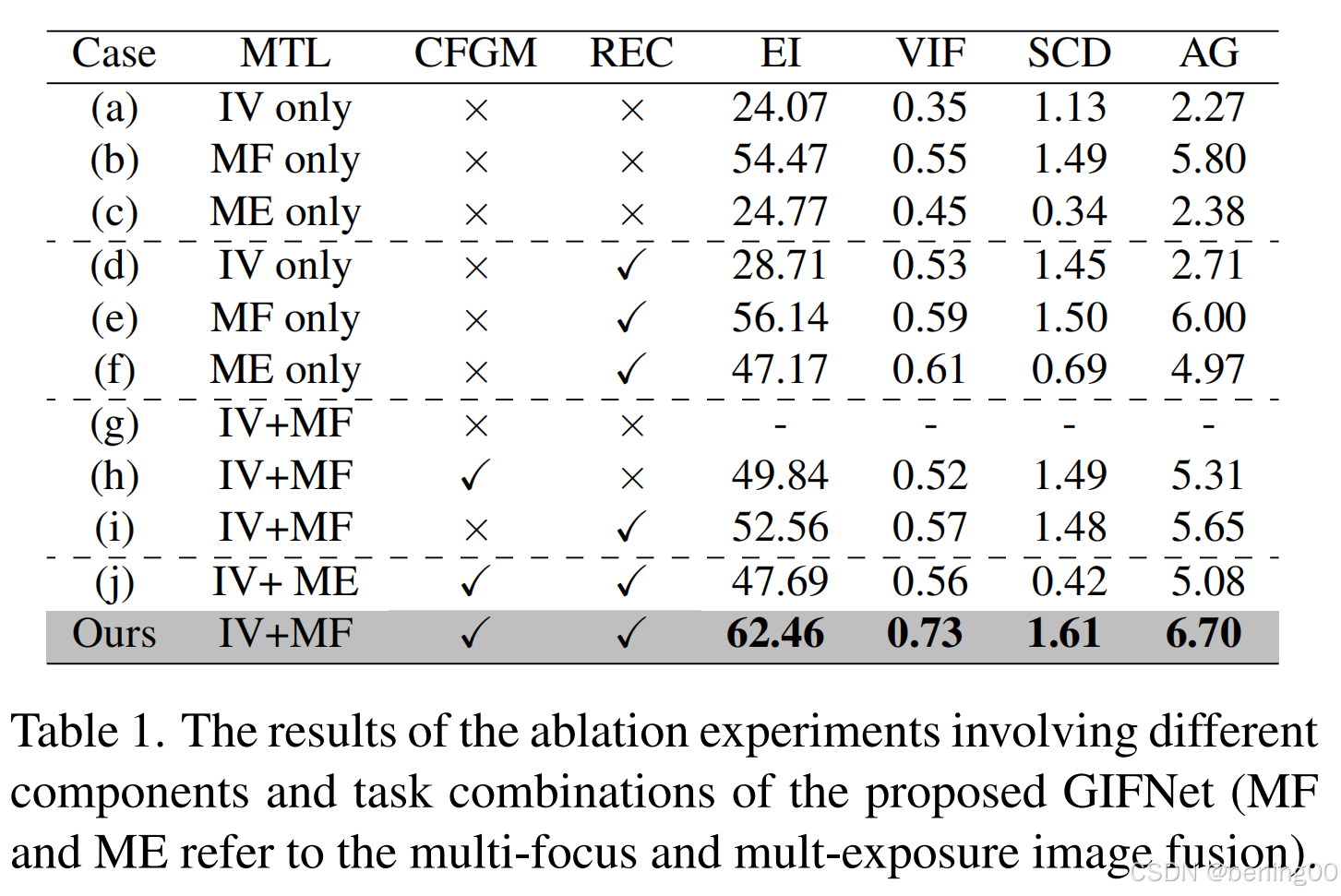
表 1. 所提出的广义图像融合网络(GIFNet)涉及不同组件和任务组合的消融实验结果(MF 和 ME 分别指多聚焦图像融合和多曝光图像融合)。
交叉融合门控机制(CFGM)模块:最后,如图5和图6所示,用传统的融合操作取代自适应的CFGM策略(其特点是有一个可学习参数λ用于控制混合比例),从定量和定性两方面都表明,我们的自适应方法能够对交互过程进行更出色的控制,从而生成更可靠的融合图像。
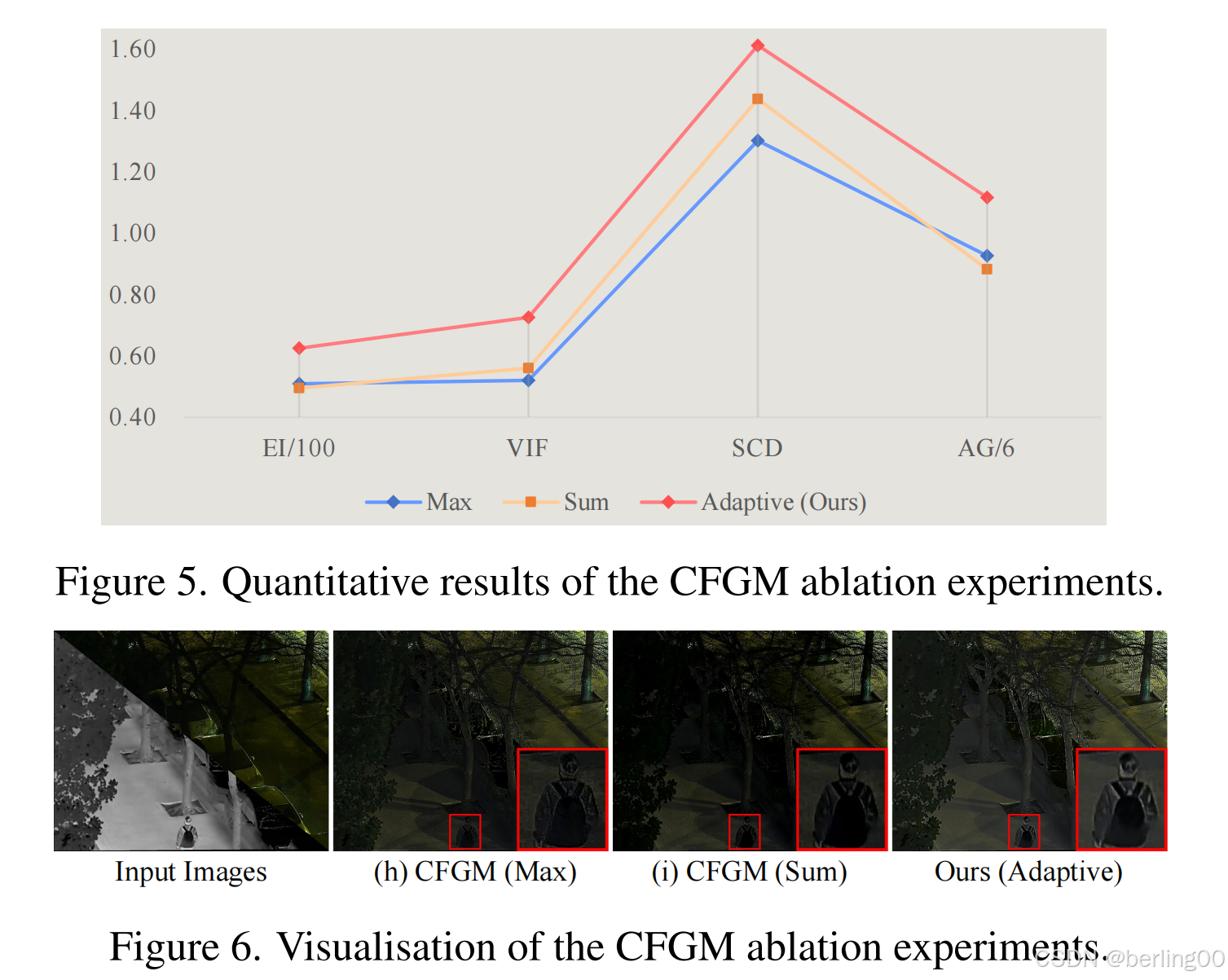
图5. 交叉融合门控机制(CFGM)消融实验的定量结果。
图6. 交叉融合门控机制(CFGM)消融实验的可视化结果。
4.3 特征可视化
图7显示,共享编码器提取的基础特征包含纹理和边缘信息。MM分支的特征保留了红外图像中的热辐射信息(如人体轮廓),而DP分支的特征增强了可见光图像的细节(如树叶纹理)。交叉融合后的特征同时包含两种模态的关键信息,验证了CFGM的有效性。

图7. 共享编码器以及两个分支在各种图像融合任务上的特征图可视化结果。
4.4 已见任务
在MFIF任务中,GIFNet在VIF指标上达到0.921,较第二名Text-IF提升25%(表2a)。在IVIF任务中,GIFNet的融合结果平衡了红外与可见光信息,在NVIQM指标上达到0.943,优于CDDFuse[43]的0.915(表2b)。视觉效果显示,GIFNet在保留红外目标(如行人)的同时,恢复了可见光图像的纹理细节(图8)。

图8. 先进方法在不同融合任务上的定性结果。
4.5 未见任务
对于未见的MEIF任务,GIFNet在VIF指标上达到0.853,较U2Fusion[34]提升46.7%(表2c)。在NIR融合任务中,GIFNet的SCD值为0.081,优于所有对比方法(表2d)。遥感融合任务中,GIFNet的AG值达到0.937,显著优于传统方法(图8)。医学图像融合任务中,GIFNet有效整合了MRI的解剖结构和PET的功能信息(表2f)。
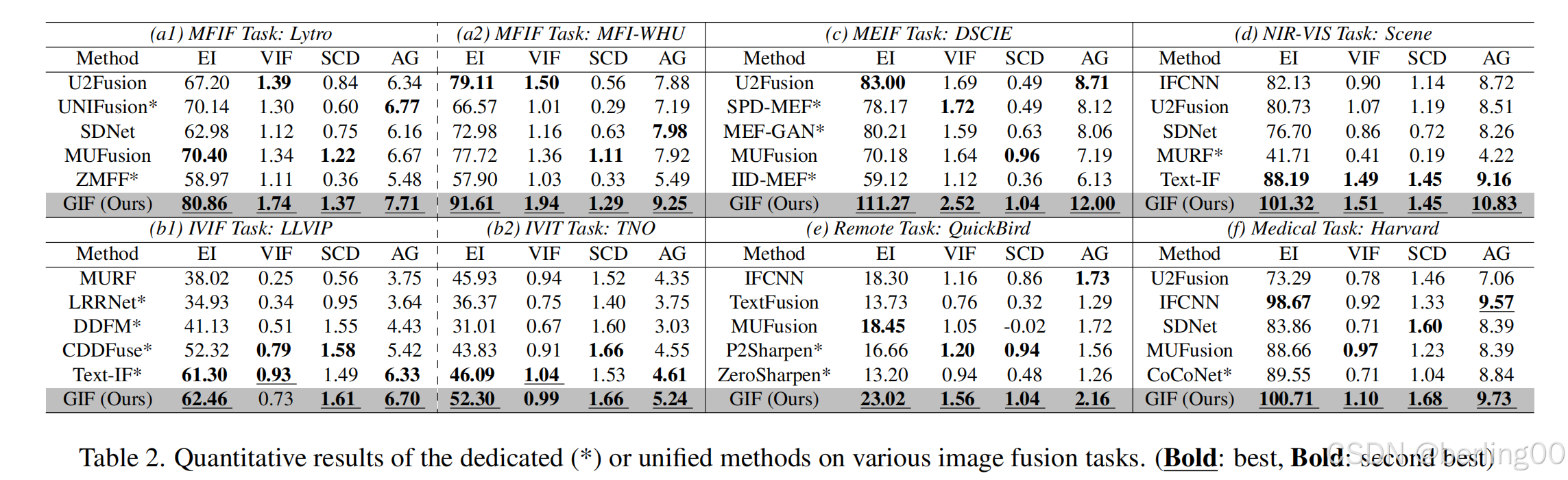
表2. 专用(*)或统一方法在各种图像融合任务上的定量结果。(加粗:最佳,加粗:次佳)
4.6 单模态增强任务
使用增强后的CIFAR100数据训练ResNet56,GIFNet的Top-1准确率达到56.18%,较原始数据提升7.3%(表3)。可视化结果显示,增强后的图像对比度更高,细节更清晰(图9)。这表明GIFNet不仅适用于多模态融合,还能作为通用图像增强器。
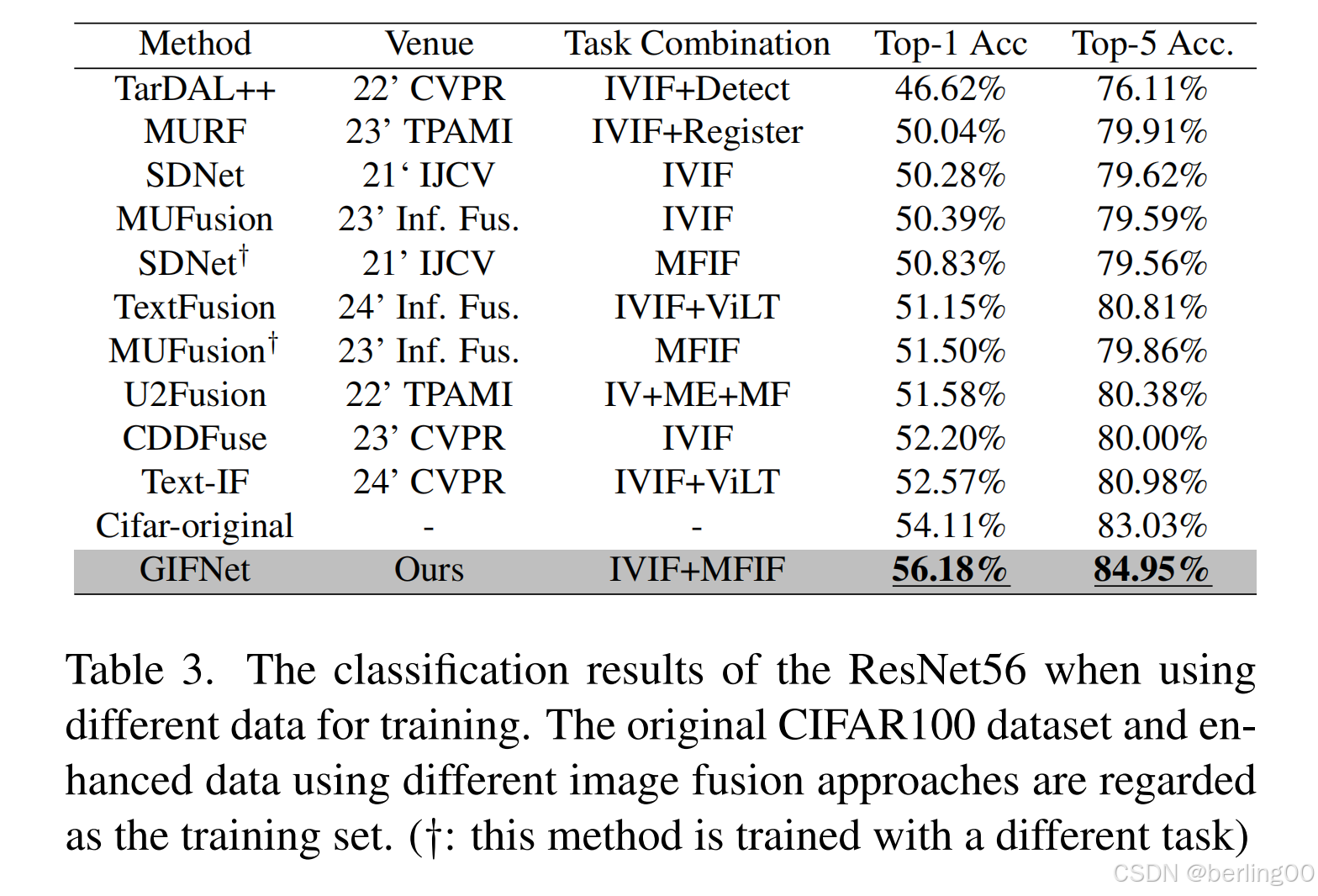
表3. 使用不同数据进行训练时,ResNet56的分类结果。原始的CIFAR100数据集以及使用不同图像融合方法增强后的数据被用作训练集。(†:此方法是使用不同的任务进行训练的)

图9. 先进的图像融合方法在CIFAR100单模态增强任务上的可视化结果。
5. 结论
本文提出了基于底层任务交互的广义图像融合框架GIFNet。通过引入交叉融合门控机制和重建任务,模型能够有效整合多模态与数字摄影特征,实现任务无关的高性能融合。GIFNet首次将图像融合技术扩展至单模态增强领域,为实际应用提供了新的可能性。未来工作将探索如何进一步提升模型在极端低光条件下的性能,并开发更轻量化的架构以适应边缘设备。

















 2954
2954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









