






密度峰值聚类与其一类改进的理解
密度峰值聚类
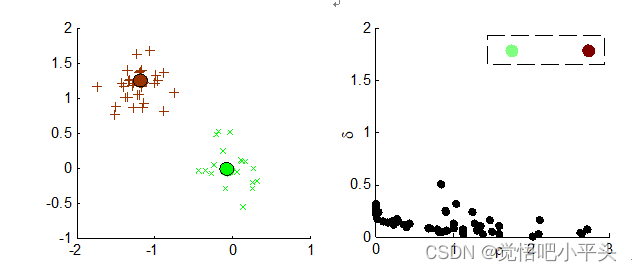
密度峰值是14年发表在science上的一篇经典文章[1],该算法整体思路非常简单但是却能有效的刻画数据的潜在中心。其具体操作就是把数据点的局部密度与相对距离作为指标绘制决策图,两个指标较高的点会在决策图的右上角凸显出来。实际上简单理解起来,该算法的核心就是,把数据集中的所有高密度区域的中心位置识别出来,对每个区域保证有且仅有一个点在决策图中凸显出来。 算法计算两个指标的具体公式与决策图绘制如下(这里简单的引用文章DPC-CE[]的描述):
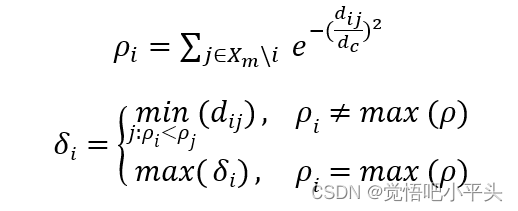
算法缺陷
密度峰值有几个比较明显的缺陷,也是目前改进算法的重点,包括了:
- 计算复杂度较高-O(n2),这使得算法难以应用在大型数据挖掘问题中;
- 链式反应严重,即一个数据点的错误归纳会导致最近邻的一系列错误分布,这一点依据中心点的选取结果,既可能是算法的优势,又可能成为算法的劣势;
- 依赖高斯分布,也就是欧氏距离的衡量标准会导致整个计算过程较为依赖数据分布是高斯型的这一假设,导致其处理很多其它类型的数据集时效果不理想,该点我认为是导致上述链式分布成为算法缺点的最重要原因。
改进算法: MDPC
该算法是发表在Information Sciences[3]的一篇文章,其对密度峰值算法做出了最直接的改进手段,即提出了一种新的相似度衡量方法。该方法集中了connectivity distance[]与欧式距离的优点,具体表现形式如下:
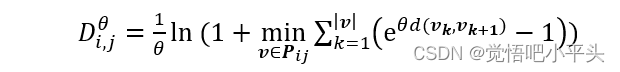
之所以说该公式结合了两个经典距离的优点,是因为该距离方法由参数θ控制,对其左右求极限,可得:
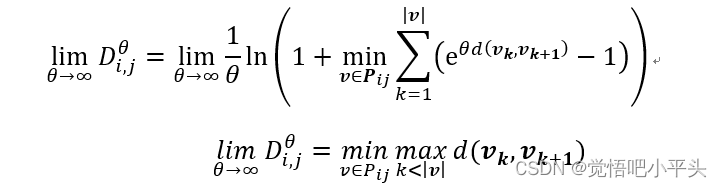
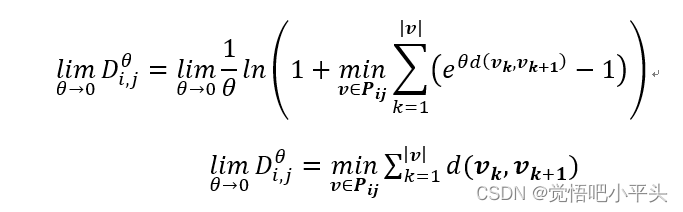
可见,当θ趋近于无穷时,该距离衡量刚好与connectivity distance描述的最小间距的最大值一致。而反之当θ趋近于0时,该公式又趋近于两点之间的欧式距离的描述。
那么在欧式距离的衡量中加入connectivity distance的意义何在呢?
其实该想法就是针对了上述缺点中的第三条,即算法过度依赖高斯分布的假设,导致在处理非高斯型数据时出现聚类中心的错误选取,从而引起链式反应的过程。该过程由下图可以描述(以数据集twomoons为例):
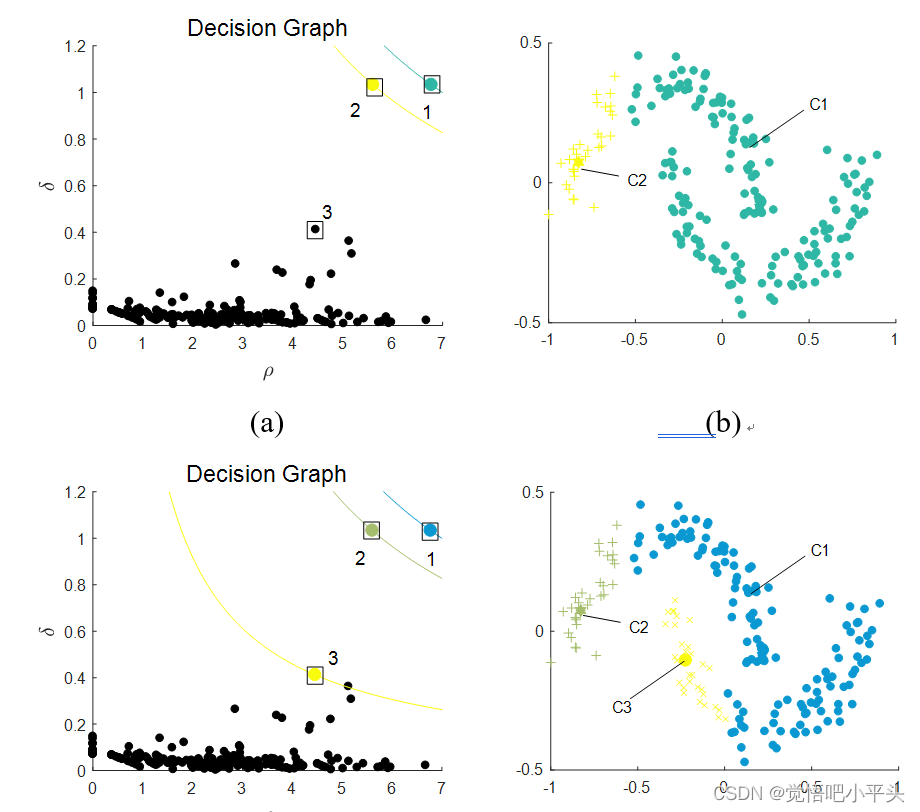
有图可见,欧氏距离的衡量是不足以描述非高斯型分布的,而connectivity distance则刚好相反,其将两点间的通道的所有间距考虑在内,实际上对点之间的联通程度进行了估计,有效地帮助算法识别任意分布的数据集。然而,单纯的使用connectivity distance,会导致类之间的噪音点对分布结果的影响极大,尤其是类间的桥连接,在connectivity distance的描述下很容易使得两个类合并。因此,MDPC提出的新的相似度衡量手段,有效地平衡了这一问题。实验证明,算法新引入的参数θ并不需要根据不同数据集进行大幅度条件,具体推荐手段可见文章。算法代码可见github[4]
引用
[1] A. Rodriguez, A. Laio, Clustering by fast search and find of density peaks, Science. 344 (6191) (2014) 1492–1496.
[2] W.J. Guo, W.H. Wang, et al., Density Peak with Connectivity Estimation. Knowledge-Based Systems. 2022. DOI: 10.1016/j.knosys.2022.108501.
[3] X.M. Tao, W.J. Guo, et al., Density Peak Clustering using global and local consistency adjustable manifold distance, Inf. Sci. 577 (2021) 769-804.
[4] https://github.com/WJ-Guo














 3351
3351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









