






6.0新特性
- redis多线程
redis命令执行是单线程的,其它一些操作是多线程的
- 客户端缓存
服务端的数据发生变化时,通知客户端将缓存数据消除,获取最新的
- 可以设置用户权限
比如用户名,一些命令的权限
缓存穿透
例如一些首页,大批量的请求访问没有被缓存的数据,直接跳过系统设计的多级缓存,直达后台数据库
解决:
1.首次访问在没有缓存的数据缓存起来,下次请求则直接访问缓存
2.利用布隆过滤器
缓存失效(击穿)
比如:大批量的key同时缓存的,则失效时间相同,当失效时刻,大批量的请求这些key,就大量请求数据库
解决:
失效时间不要设置成一致的,要有一定的时间间隔
缓存雪崩
缓存设计不合理-->缓存崩-->数据库崩-->系统崩-->雪崩式的连带反应
解决:
缓存高可用,哨兵或集群架构,熔断降级
布隆过滤器
类似于bitmap,一个key经过几次不一样的hash运算,将每次得到的对应槽位置为1,下次获取key时,经过几次hash运算,只要有一次结果是0,则认为key不存在。
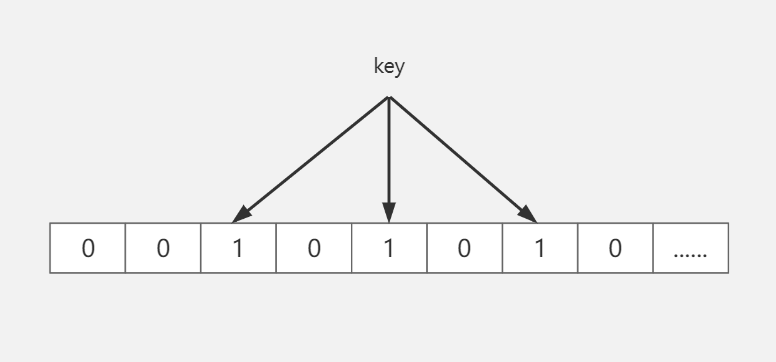
优点:
占用空间少,一个bit为一个槽位,存储的信息量很大
这种方法应用于缓存命中率比较低,数据相对固定,数据比较大的场景使用,代码维护较为复杂
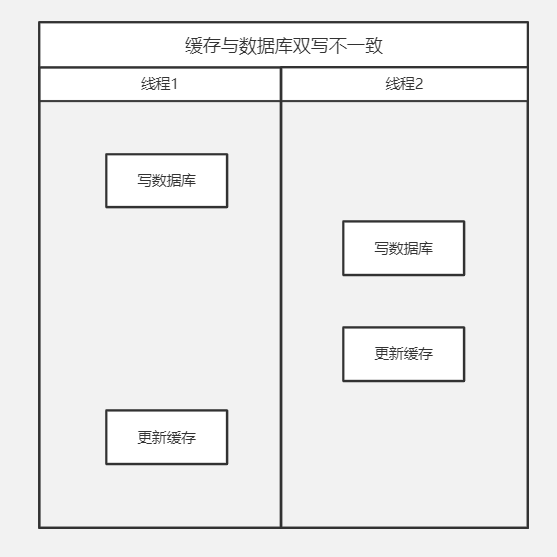
缓存与数据库双写不一致
线程1写完库,还没来得及更新缓存,这时线程2写完库且更新缓存完成,接下来线程1更新缓存完成,造成数据库是线程2的值,缓存是线程1的值
数据库和缓存读写不一致
假如去读的时候在更新缓存,写的时候删除缓存,也存在问题
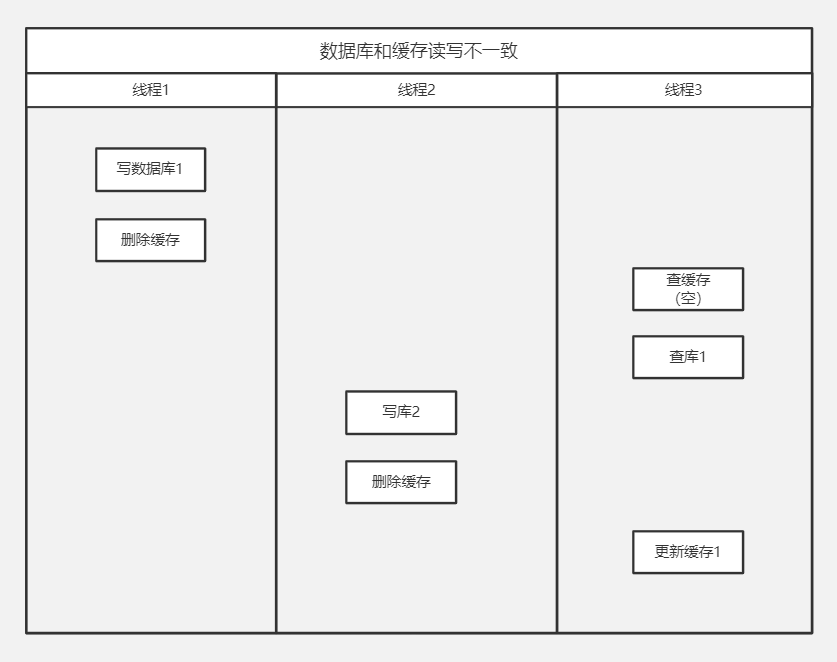
写数据库和删除数据库的时间在另一个线程查询和更新缓存之间,此时数据库是线程2的值,缓存是线程1的值。
解决:
都是小概率事件,可以强制设置缓存失效时间
如果要求强一致性,可以使用分布式读写锁(redission),保证读多写少的时候不影响读的性能。
读多写少的情况又要求一致性,建议不要用缓存,放入缓存中的应该是对数据的实时性和一致性要求不高的,如果既要求一致性,又要求有缓存,势必会增系统的复杂性。
个别情况:下单减库存,是读多写少,为减少数据库的压力,将redis缓存作为主库来使用,定时向数据库同步库存数据
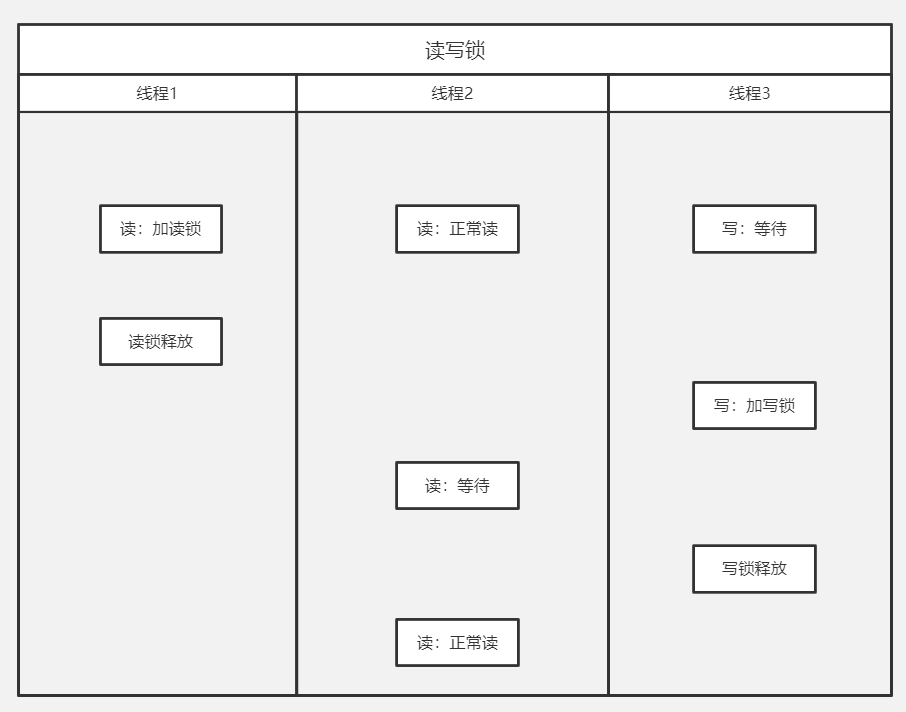
读写锁:
查缓存的时候加读锁,不影响其它线程的读,当有线程写的时候,则等待读锁释放,写的时候加写锁,其它线程读或写都等待
Redis连接池:
| 参数 | 意义 | 说明 |
| maxTotal | 最大连接数 | 连接池能开辟的最大连接数 |
| maxIdle | 最大允许空闲连接数 | 最多保留这些连接,超过这些,释放其余的空闲连接,需要的时候再重新申请连接 |
| mixIdle | 最小允许空闲连接数 | 最少保留这些连接数 |
一般使用maxTotal和maxIdle就可以
minIdle,只有手动释放空间连接,才起到作用
最大连接数的设置:假如一条命令执行需要1ms,则一个连接 支持1000QPS,如果需要10000QPS,则需要10连接(理论值一般要比这大一点)















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









