







1. 福建电信数据仓库项目
在福建电信数据仓库项目的实现过程中,自主开发了ETL平台,能够充分满足现有业务环境的需要,根据需求灵活配置实体,并且能够和业界的优秀ETL工具结合,充分满足客户的需求。
l 能够针对文件接口提供较好的支持,包括文件名的解析通配等等,并且可以支持接口处理阶段和仓库处理阶段的松耦合,支持接口校验。
l 引入实体的概念,每个实体针对一个客户的业务流程,支持灵活的配置。
l 脚本库的引入,脚本和实体相关,方便对业务逻辑的抽取,便于未来复用,这样就可以把握住整个ETL的核心流程。
2. 基于XML的实时数据集成(RDI)
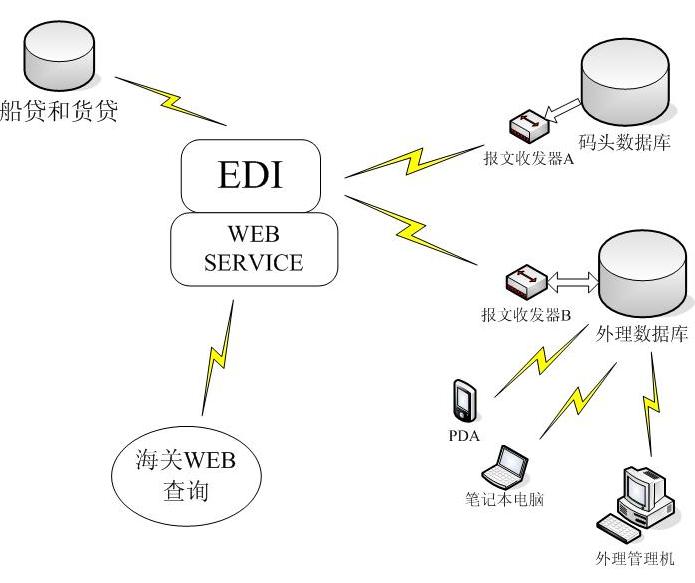
RDI产品的核心定位是在异构的企业信息环境中,快速建立一个统一的信息共享平台,解决信息孤岛问题,实现异构系统信息共享。RDI平台本质上是数据库中间件,通过对应用接口层进行包装,应用系统可以通过两类方式访问RDI平台:
l 作为Web service客户端,此时,查询语言可以是SQL或XQuery。使用这种方式,返回结果将被封装为XML文档格式。
l 作为传统关系数据库客户端,通过ODBC和JDBC接口访问RDI平台。返回结果将是标准的SQL结果集。
本项目的创新点即在于采用了SQL和XQuery作为数据查询语言,实现了对异构数据源的统一查询,这些异构数据源包括DB2、Informix、MS SQL Server、Oracle、Sybase、其他具有ODBC或JDBC接口的数据、XML文档以及SNMP数据源,而且该中间件可以实现跨平台,包括Microsoft Windows、UNIX(SUN Solaris,HP-UX,IBM AIX)、Linux。
行业借鉴经验:
谈不上是行业借鉴经验,但我个人在担任数据库管理员期间,也总结了一些对数据的监控管理调优等有用的经验,愿意与大家分享。自从成为项目组的DBA以来,我对自己的工作总结出了四个字:“胆大心细”,我想这也是对DBA工作内容的一种诠释,和大家共勉。
1. 养成好的管理习惯,形成DBA的每天工作日志
定期查看数据库的健康情况,包括应用、表空间、文件系统、系统的内存、CPU、磁盘I/O等等,这些虽然很不起眼,但却是非常重要的,要尽量在出问题以前就发现隐患并尽快采取措施,避免在问题出现以后再弥补。对于复杂的SQL语句要有分析执行计划的习惯,看看系统中有没有一些和我们所预想不一致的地方,依靠数据库的优化器是一方面,另一方面必须要有良好的SQL编写习惯。
2. 不断学习,强化技术
在数据库的管理工作当中,总会遇到各种各样的问题,这些问题可能是易于解决的问题,也可能是让人摸不着头脑的问题,不过不用担心,见过的世面越多,解决问题的能力也就越强,这对DBA的工作也提出了很高的要求,必须要坚持不断学习,加深对产品的理解。要注意技术的积累,数据库是一个庞大复杂的系统,它的复杂性是非常高的,可以说并不亚于操作系统,所以想要深入理解数据库还需要更加深入的了解,如果要是有时间和能力的话建议可以找些开源的数据库来看看代码,像一些代码行数较少的青量级内存数据库HSQLDB,这是一个用Java语言实现的数据库,个人认为这是一个非常好的学习材料,麻雀虽小,可谓五脏俱全,比如事务处理,JDBC支持,完整性约束等等,虽然现在已经不再作JAVA的开发了,但是我的Eclipse里面始终有一个HSQLDB的工程。当然如果要是想了解更复杂的开源数据库,那就非Postgre SQL了,目前Postgre SQL已经有了商业应用,我想对这些开源代码的阅读也一定会让大家加深对数据库内部机制的理解。就我本人而言,在刚接触DB2 的时候就是个门外汉,为了尽快熟悉产品,我找了很多的资料,IBM的Developerworks上有不少很好的教学文档,另外我还查阅了许多书籍,并积极和原厂商的工程师交流,尽快熟悉数据库的各种操作以及如何配置合适的数据库环境,了解数据库的各个级别的参数设置的含义,因为所有的参数都关乎用户对数据库的使用和性能的差异。学会分析诊断日志来找出问题的真正原因也是必须要掌握的,日志的级别太低虽然可以减小日志文件的体积,但对于排查错误并不好处,之所以这么说是因为必须把问题联系在一起解读才能更好地定位问题所在。另外对数据库管理员的一个要求就是对操作系统知识也要有一些了解,这对问题的诊断分析大有裨益,试想如果对操作系统的SHELL以及查错的方法不熟悉,是没法很好地驾驭数据库的。
作为一个优秀的DBA,不但要看到表象,还要学会对产品的深层次特性进行了解,比如内存模型,充分理解模型可以帮助我们解决问题。举个简单的小例子,有时开发人员会提交一些较为复杂的SQL语句,比如一个定义了过多表的视图在操作时通常会报APP_CTL_HEAP_SZ不够用,怎么办呢?打开DB2的信息中心,查询后得知这个参数叫应用程序控制堆。这个参数的作用对于不同的数据库设置有着不同的解释,对于分区数据库以及启用了内部并行性(intra_parallel=ON)的非分区数据库,此参数指定分配给应用程序的共享内存区域的平均大小。对于禁用内部并行性的非分区数据库(intra_parallel=OFF),这是将为堆分配的最大专用内存。每个分区的每个连接有一个应用程序控制堆。这到底是什么意思呢?想要更加了解这其中的原理就必须要知道的更多了,在IBM Developerworks的DB2专区中有一篇介绍DB2 内存模型的文章,讲得相当不错,通过这篇介绍性文章,我们可以较好地了解DB2内存模型的全貌。DB2 在 4 种不同的内存集(memory set)内拆分和管理内存。这 4 种内存集分别是:
- 实例共享内存(instance shared memory)
- 数据库共享内存(database shared memory)
- 应用程序组共享内存(application group shared memory)
- 代理私有内存(agent private memory)
(上图摘自IBM Developerworks)
每种内存集由各种不同的内存池(亦称堆)组成。上面提到的app_ctl_heap_sz是属于第三层,也就是属于应用程序组共享内存这个级别的。应用程序组内存集是从数据库共享内存集中分配的。其大小由 appgroup_mem_sz数据库配置参数决定。多个应用程序可以指派给同一个应用程序组。一个应用程序组内可以容纳的应用程序数有如下的计算公式: appgroup_mem_sz / app_ctl_heap_sz,实际应用程序控制堆大小都是通过一个公式计算出来的,这个公式就是 ((100 - groupheap_ratio)% * app_ctrl_heap_sz)。所以我们只要连上数据库后通过db2 get db cfg 命令,找到如下一组参数:每个应用程序的
应用程序组内存集的最大大小(4KB) (APPGROUP_MEM_SZ) = 30000
应用程序组堆的内存百分比 (GROUPHEAP_RATIO) = 70
最大应用程序控制堆大小(4KB) (APP_CTL_HEAP_SZ) = 128
如果想要让单独的应用程序享有更多的应用程序控制堆,我们可以把APP_CTL_HEAP_SZ的值加大,或是把GROUPHEAP_RATIO的值减小,这样就可以让每个应用程序获得更多的应用程序控制堆。但是在这里我要顺便提一点,修改数据库的参数并不是解决问题的唯一或是根本途径,有些问题还是应该从应用本身着手,这才是解决问题的一个重点,比如说,DB2的多分区环境有一个快速通信管理器,也就是我们通常说到的FCM,这是一个非常重要的参数,不但影响性能,而且严重的时候还会造成应用得不到足够的FCM缓冲而导致中低优先级的程序回滚,这对于一个生产环境来说是很严重的问题,大量的回滚甚至可以造成系统性能的严重下降。如果我们在发现FCM不够而导致应用程序报错以后就会试图修改DBM级的一个参数,这个参数叫做FCM_NUM_BUFFERS,顾名思义,也就是FCM的缓冲大小,调大这个参数可以在一定程度上避免上述的问题,但这并不是根本的解决方案,也就未来你还会遇到类似的问题,这时候我们不能一味地尝试去增加这个参数的大小,而必须从应用的角度着手,查看表的分区键是否合理,SQL语句的执行计划是否合适等等。
应用难点技巧:
在平常的开发管理中我们也会经常遇到不少问题,我的建议是在开发的初期一定要做好规划,越细越好,未雨绸缪,还是讲到DB2的分区键,这对于未来开发起着重要甚至是决定意义的影响,分区键定义得好意味着应用运行性能好,不会产生节点之间的大量数据广播,减小系统的压力,而如果分区键定义的不好意味着性能的下降以及数据在节点之间分布不均匀。
另外我还可以讲几点应用调优的步骤方法,我们可以遵循以下几点:
1 定期对数据库中的表进行统计信息的收集,也就是对应的runstats操作。在实际对应用调优的过程中也发现有SQL语句执行计划不准确的现象,因此,强烈建议对库中所有的数据表通过定时运行Runstats操作,保持其最新的统计信息。
2在ETL任务调度的时候,对加载任务进行原子化细分,并对各个原子任务对系统资源消耗的情况进行分析,然后根据“在系统资源的使用上不产生竞争的任务,尽量调度其并行处理”,以确保在最短的时间内完成最多的ETL原子任务。为了将A、B两类数据加载进数据库,我们可以将其任务细分为数据予处理、数据加载、建索引和Runstats 的四个过程,而其中数据予处理主要在ETL服务器上进行,它主要消耗ETL服务器的CPU和IO资源,而建索引和Runstats过程则主要在数据库服务器上进行,它们消耗的是数据库服务器的CPU和IO系统资源,由于这两类任务在资源要求上没有竞争,因此它们是可以并行调度执行的。在理想情况下,经过并行调度后,ETL的性能可以提高约50%。
3合理选择分区键,提高Join操作速度,以下是选择分区键的一些建议:
• 选用Join频度最高的字段作为分区键
• 分区键可以基本保证各分区内数据均匀分布
• 分区键的数值分布范围大
• 分区键效率:整型 > 字符型 > 浮点型
建议检查应用程序,找出造成第4种Join的SQL,对相关数据表的分区键重新考虑,原则是对大表Join,至少其中一张表应该按照分区键Join。
4根据对部分SQL查询计划的分析,系统中部分字典表(单分区表)由于没有创建对应的Replicated表,在进行Join操作的时候会进行BroadCast Join。DB2中通过对字典表等数据量较小、数据偏静态的数据表构建Replicated Table,从而将Broadcast Join转化为Replicated Join是一种常用的优化方法。
CREATE TABLE QRY.R_CHANNEL_TYPE_CD
AS (select * from qry.CHANNEL_TYPE_CD)
DATA INITIALLY DEFERRED
REFRESH IMMEDIATE
ENABLE QUERY OPTIMIZATION
MAINTAINED BY SYSTEM
DATA CAPTURE NONE
IN DATS
REPLICATED;















 3587
3587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









