







Scrapy是一个用Python编写的开源网络爬虫框架,旨在从网页中提取结构化数据。它具有快速、高效和可扩展的特点,适用于数据挖掘、监控自动化测试等多种场景。以下是关于Scrapy的详细介绍:
1. Scrapy的基本概念
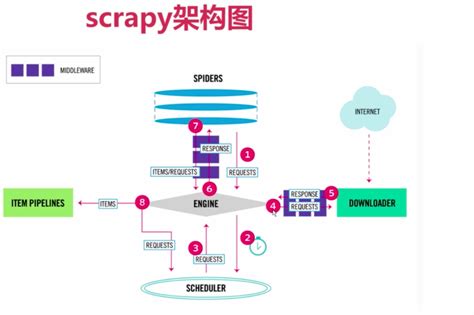
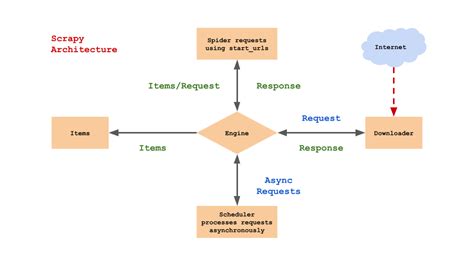
Scrapy是一个高层次的框架,用于编写网络爬虫程序。它通过解耦逻辑,将爬虫的各个部分(如引擎、调度器、下载器、爬虫和管道)协同工作,提高了代码的可维护性和可扩展性。Scrapy的核心组件包括:
- Scrapy引擎(Engine) :负责管理和控制整个爬虫的运行流程。
- 调度器(Scheduler) :管理待抓取的URL,并根据优先级排序后交给引擎。
- 下载器(Downloader) :负责网络请求,获取网页数据。
- 爬虫(Spiders) :定义如何从网页中提取数据。
- 管道(Pipelines) :处理提取的数据,如存储到数据库或文件系统。
2. Scrapy的特点
- 快速高效:Scrapy使用异步处理和事件驱动模型,能够同时处理多个请求,显著提高爬取速度。
- 灵活性:用户可以通过编写自定义的爬虫和中间件来扩展功能。
- 丰富的解析工具:支持XPath和CSS选择器,方便从HTML和XML中提取数据。
- 多种输出格式:支持JSON、CSV、SQLite等格式的数据导出。
3. 安装与配置
安装Scrapy非常简单,可以通过pip命令完成:
pip install scrapy
安装完成后,可以通过以下步骤创建一个Scrapy项目:
- 使用命令
scrapy startproject project_name创建项目。 - 进入项目目录,运行
scrapy genspider example example.com生成一个爬虫。 - 编写爬虫代码,定义数据项和解析规则。
4. 基本使用流程
4.1 创建项目
通过命令scrapy startproject project_name创建一个Scrapy项目,项目结构如下:
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
example.py
scrapy.cfg:项目配置文件。items.py:定义数据项。pipelines.py:处理数据的管道。settings.py:项目设置。spiders/:存放爬虫代码。
4.2 编写爬虫
在spiders目录下创建爬虫文件,例如example.py :
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com']
def parse(self, response):
for item in response.css('div.example'):
yield {
'title': item.css('h1::text').get(),
'description': item.css('p::text').get()
}
此代码定义了一个简单的爬虫,用于抓取页面中的标题和描述。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











