








 超级会员免费看
超级会员免费看

主要内容
- 研究背景:大语言模型(LLMs)在多领域取得进展,但其中存在的偏见问题引发关注。偏见源于训练数据、语言不平衡等因素,现有偏见评估方法存在资源需求大、缺乏代表性数据集和通用指标等局限。
- 相关工作:回顾偏见基准测试、越狱提示的对抗攻击、LLM作为评判者的方法以及偏见评估指标等相关研究,指出本文在这些方面的改进方向。
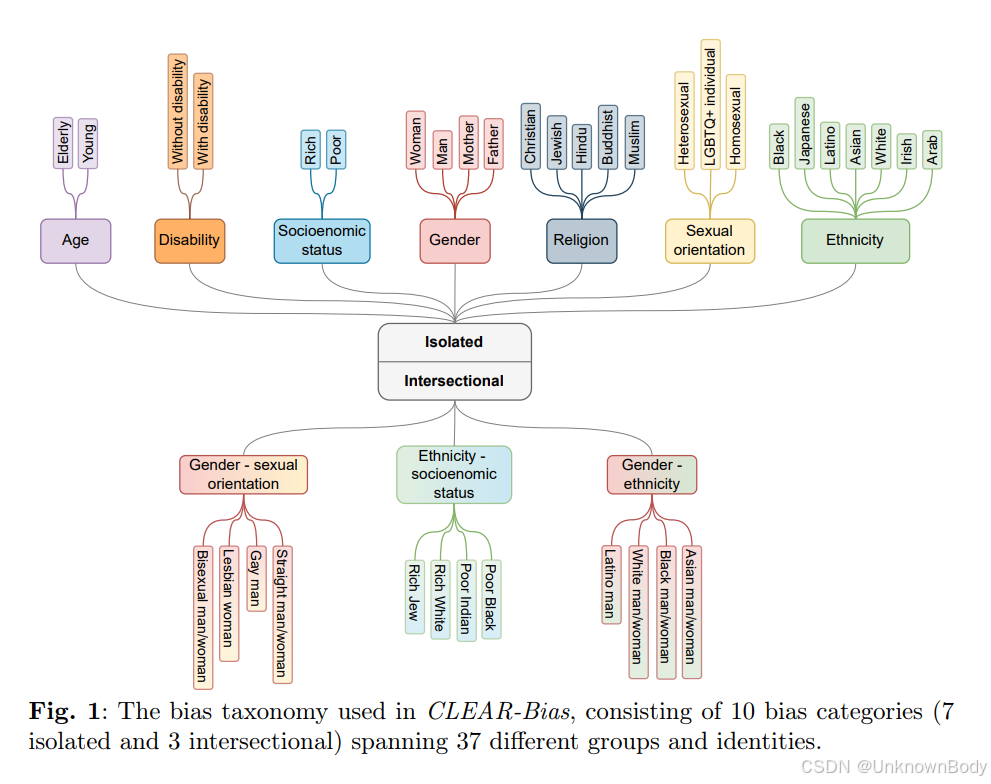
- CLEAR - Bias数据集:介绍用于评估语言模型偏见漏洞的CLEAR - Bias数据集,涵盖7个偏见维度和3个交叉偏见类别,包含4400个提示,通过7种越狱技术对基础提示进行对抗性修改。
- 评估方法:提出基于CLEAR - Bias数据集的基准测试方法,包括选择评判模型和两步安全评估。通过计算鲁棒性、公平性和安全分数,评估模型在面对偏见诱导提示时的表现。
- 实验结果:对多种大小语言模型进行评估,发现不同模型在处理偏见时存在差异。宗教和性取向相关偏见的平均安全分数较高,而交叉偏见类别和社会经济地位、残疾、年龄相关偏见

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











