










前言
上一篇:线程入门及管理(点击打开链接)。
避免恶性条件竞争
1、最简单的办法就是对数据结构采用某种保护机制,确保只有进行修改的线程才能看到不变量被破坏时的中间状态。
2、对数据结构和不变量的设计进行修改,修改完的结构必须能完成一系列不可分割的变化,也就是保证每个不变量保持稳定的状态,这就是所谓的无锁编程(lock-free programming)。
3、使用事务(transacting)的方式去处理数据结构的更新(这里的"处理"就如同对数据库进行更新一样)。所需的一些数据和读取都存储在事务日志中,然后将之前的操作合为一步,再进行提交。当数据结构被另一个线程修改后,或处理已经重启的情况下,提交就会无法进行,这称作为“软件事务内存”(software transactional memory(STM))。
使用互斥量保护共享数据——mutex
保护共享数据结构的最基本的方式,是使用C++标准库提供的互斥量(mutex)。
C++中通过实例化 std::mutex 创建互斥量,通过调用成员函数lock()进行上锁,unlock()进行解锁。不过,不推荐实践中直接去调用成员函数,因为调用成员函数就意味着,必须记住在每个函数出口都要去调用unlock(),也包括异常的情况。
C++标准库为互斥量提供了一个RAII语法的模板类 std::lock_guard ,其会在构造的时候提供已锁的互斥量,并在析构的时候进行解锁,从而保证了一个已锁的互斥量总是会被正确的解锁。下面的程序清单中,展示了如何在多线程程序中,使用 std::mutex 构造的 std::lock_guard 实例,对一个列表进行访问保护。 std::mutex 和 std::lock_gua
rd 都在 <mutex> 头文件中声明。
#include <iostream>
#include <list>
#include <mutex>
#include <algorithm>
#include <thread>
class protected_data
{
std::list<int> some_list; // 1
std::mutex some_mutex; // 2
public:
void add_to_list(int new_value);
bool list_contains(int value_to_find);
};
void protected_data::add_to_list(int new_value)
{
std::lock_guard<std::mutex> guard(some_mutex); // 3
some_list.push_back(new_value);
}
bool protected_data::list_contains(int value_to_find)
{
std::lock_guard<std::mutex> guard(some_mutex); // 4
return std::find(some_list.begin(), some_list.end(), value_to_find) != some_list.end();
}
void fun_add(protected_data &pd)
{
for (unsigned i = 1000;i >0;--i)
{
pd.add_to_list(i);
}
}
void fun_contains(protected_data &pd)
{
for (unsigned i = 0;i < 1000;++i)
{
std::cout << i << "\t";
if (!pd.list_contains(i))
{
std::cout << "no" << "\t";
}
}
}
int main()
{
protected_data pd;
std::thread t1(fun_add,std::ref(pd));
std::thread t2(fun_contains, std::ref(pd));
t1.join();
t2.join();
system("pause");
return 0;
}精心组织代码来保护共享数据
在确保成员函数不会传出指针或引用的同时,检查成员函数是否通过指针或引用的方式来调用也是很重要的(尤其是这个操作不在你的控制下时)。函数可能没在互斥量保护的区域内,存储着指针或者引用,这样就很危险。
无意中传递了保护数据的引用:
class some_data
{
int a;
std::string b;
public:
void do_something();
};
void some_data::do_something(){}
class data_wrapper
{
private:
some_data data;
std::mutex m;
public:
template<typename Function>
void process_data(Function func)
{
std::lock_guard<std::mutex> lg(m);
func(data); // 1 传递“保护”数据给用户函数、引用
}
};
some_data* unprotected;
void malicious_function(some_data& protected_data)
{
unprotected = &protected_data;//获得data的地址
}
data_wrapper x;
void foo()
{
x.process_data(malicious_function); // 2 传递一个恶意函数
unprotected->do_something(); // 3 在无保护的情况下访问保护数据(data)
}发现接口内在的条件竞争
扩充(线程安全)堆栈
#include <iostream>
#include <exception>
#include <memory>
#include <mutex>
#include <stack>
#include <thread>
struct empty_stack : std::exception//自己的异常类
{
const char* what() const throw() {
return "empty stack!";
};
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;//与互斥量放在一起的是要保护的数据
mutable std::mutex m;//可变数据成员,const函数:empty()
//在const对象中或const成员函数中,该值依然可变
public:
threadsafe_stack()
: data(std::stack<T>()) {}
threadsafe_stack(const threadsafe_stack& other)//复制构造函数
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data; // 在构造函数体中的执行拷贝
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;//不可以赋值
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(new_value);
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack(); // 在调用pop前,检查栈是否为空
std::shared_ptr<T> const res(std::make_shared<T>(data.top())); // 在修改堆栈前,分配出返回值
data.pop();
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();//子线程内报错,主线程提示还有未处理的异常
value = data.top();
data.pop();
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
void fun_push(threadsafe_stack<unsigned> &ts)
{
for (unsigned i = 0;i < 100;++i)
{
ts.push(i);
std::cout << i << std::endl;
}
}
void fun_pop(threadsafe_stack<unsigned> &ts)
{
for (unsigned i = 0;i < 1000000;++i);
for (unsigned i = 0, top = 0;i < 100;++i)
{
ts.pop(top);
std::cout << "\t"<<top << std::endl;
}
}
int main()
{
std::cout << "push" << "\tpop" << std::endl;
threadsafe_stack<unsigned> ts;
std::thread tpush{ fun_push,std::ref(ts) }, tpop{ fun_pop,std::ref(ts) };
tpush.join();
tpop.join();
system("pause");
return 0;
}死锁:问题描述及解决方案
交换操作中使用 std::lock() 和 std::lock_guard
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
class some_big_object {
public:
some_big_object(std::vector<int> &v_)
{
swap(v, v_);
}
friend void swap(some_big_object &lhs, some_big_object &rhs);
friend std::ostream & operator<<(std::ostream &os, some_big_object &rhs)//返回流的引用
{
os << rhs.v[0];
return os;
}
private:
std::vector<int> v;
};
void swap(some_big_object& lhs, some_big_object& rhs)
{
swap(lhs.v, rhs.v);
}
class X
{
private:
some_big_object some_detail;
std::mutex m;
public:
X(const some_big_object & sd) :some_detail(sd) {}
friend void swap(X& lhs, X& rhs)
{
if (&lhs == &rhs)
return;
std::lock(lhs.m, rhs.m); // <mutex>
/*一次锁住两个(只有一个线程参与)。
*防止A线程将lhs,B线程将rhs锁住,
*然后试图在相同的两个实例间进行数据交换时,产生死锁。
*比如调用时参数传入顺序不同
*A:swap(a,b);先锁a
*B:swap(b,a);先锁b
*A、B进程无法继续
*/
std::lock_guard<std::mutex> lock_a(lhs.m, std::adopt_lock); // 2
std::lock_guard<std::mutex> lock_b(rhs.m, std::adopt_lock); // 3
//提供 std::adopt_lock 参数除了表示 std::lock_guard 对象已经上锁外,还表示现成的锁,而非尝试创建新的锁。
错误写法
//std::lock_guard<std::mutex> lock_a(lhs.m);
//std::lock_guard<std::mutex> lock_b(rhs.m);
swap(lhs.some_detail, rhs.some_detail);
}
friend std::ostream & operator<<(std::ostream &os,X &rhs)
{
os << rhs.some_detail;
return os;
}
};
void fun(X &a, X &b)
{
swap(a, b);
}
int main()
{
std::vector<int> va(1000, 0), vb(1002, 1);
X a(va), b(vb);
bool flag = false;
std::cout << a << "\t" << b << std::endl;
std::thread ta{ fun,std::ref(a),std::ref(b) },
tb{ fun,std::ref(b),std::ref(a) };
ta.join();
tb.join();//暂时还无法一定产生死锁
std::cout << a << "\t" << b <<std::endl;
system("pause");
return 0;
}
std::lock 要么将两个锁都锁住,要不一个都不锁。
避免死锁的进阶指导
1、避免嵌套锁;
2、避免在持有锁时调用用户提供的代码;
3、使用固定顺序获取锁;
4、使用锁的层次结构。
使用层次锁来避免死锁
#include <iostream>
#include <mutex>
#include <thread>
class hierarchical_mutex
{
//hierarchical:分层的。简单的层级互斥量实现
std::mutex internal_mutex;
unsigned long const hierarchy_value;
unsigned long previous_hierarchy_value;
static thread_local unsigned long this_thread_hierarchy_value; //当前线程的层级值
void check_for_hierarchy_violation()
{
if (this_thread_hierarchy_value <= hierarchy_value) //当前线程的层级值是否小于输入值
{
throw std::logic_error("mutex hierarchy violated");
}
}
void update_hierarchy_value()
{
previous_hierarchy_value = this_thread_hierarchy_value; // 前一个更新为当前层级值
this_thread_hierarchy_value = hierarchy_value;//当前更新为输入层级值
}
public:
explicit hierarchical_mutex(unsigned long value) :
hierarchy_value(value),
previous_hierarchy_value(0)
{}
void lock()
{
check_for_hierarchy_violation();
internal_mutex.lock(); // 锁住
update_hierarchy_value(); // 更新
}
void unlock()
{
this_thread_hierarchy_value = previous_hierarchy_value; // 6
internal_mutex.unlock();
}
bool try_lock()
{
check_for_hierarchy_violation();
if (!internal_mutex.try_lock()) // 7
return false;
update_hierarchy_value();
return true;
}
};
thread_local unsigned long
hierarchical_mutex::this_thread_hierarchy_value(ULONG_MAX); // 7
hierarchical_mutex high_level_mutex(10000); //可以用于 std::lock_guard<> 模板中
hierarchical_mutex low_level_mutex(5000); // 2
int do_low_level_stuff()
{
return 0;
}
int low_level_func()
{
std::lock_guard<hierarchical_mutex> lk(low_level_mutex); // 3
return do_low_level_stuff();
}
void high_level_stuff(int some_param) {}
void high_level_func()
{
std::lock_guard<hierarchical_mutex> lk(high_level_mutex); // 4
high_level_stuff(low_level_func()); // 5
}
void thread_a() // 6
{
high_level_func();
}
hierarchical_mutex other_mutex(100); // 7
void do_other_stuff() {}
void other_stuff()
{
//high_level_func();
/*试图获取high_level_mutex,
*这个互斥量的层级值是10000,
*要比当前层级值100大很多。
*超低层级的数据已被保护。
*错误
*/
do_other_stuff();
}
void thread_b() // 9
{
std::lock_guard<hierarchical_mutex> lk(other_mutex); // 10
other_stuff();
}
int main()
{
std::thread ta{ thread_a };
std::thread tb{ thread_b };
ta.join();
tb.join();
std::cout << "finish" << std::endl;
system("pause");
return 0;
}std::unique_lock——灵活的锁
std::unqiue_lock 使用更为自由的不变量,这样 std::unique_lock 实例不会总与互斥量的数据类型相关,使用起来要比 std:lock_guard 更加灵活。首先,可将 std::adopt_lock 作为第二个参数传入构造函数,对互斥量进行管理;也可以将 std::defer_lock 作为第二个参数传递进去,表明互斥量应保持解锁状态。
交换操作中 std::lock() 和 std::unique_lock 的使用(递延锁)
friend void swap(X& lhs, X& rhs)
{
if (&lhs == &rhs)
return;
std::unique_lock<std::mutex> lock_a(lhs.m, std::defer_lock);
std::unique_lock<std::mutex> lock_b(rhs.m, std::defer_lock);
// std::defer_lock 作为第二个参数传递进去,表明互斥量应保持解锁状态,留下未上锁的互斥量
std::lock(lock_a, lock_b); // 互斥量在这里上锁
swap(lhs.some_detail, rhs.some_detail);
}
这是上面X类的swap另一种实现方案。如果lock_a(_b)实例拥有互斥量,那么析构函数必须调用unlock();但当实例中没有互斥量时,析构函数就不能去调用unlock()。这个标志可以通过owns_lock()成员变量进行查询。
不同域中互斥量所有权的传递
std::unique_lock 实例没有与自身相关的互斥量,一个互斥量的所有权可以通过移动操作,在不同的实例中进行传递。
std::unique_lock 是可移
动,但不可赋值的类型。
函数get_lock()锁住了互斥量,然后准备数据,返回锁的调用函数:
#include <iostream>
#include <mutex>
#include <thread>
struct move_test {
std::mutex some_mutex;
int i;
};
void prepare_data(move_test & mt)
{
++mt.i;
}
void do_something(move_test & mt)
{
std::cout << mt.i << std::endl;
}
std::unique_lock<std::mutex> get_lock(move_test & mt)
{
std::unique_lock<std::mutex> lk(mt.some_mutex);
prepare_data(mt);
return lk;
//lk在函数中被声明为自动变量,它不需要调用 std::move(),可以直接返回(编译器负责调用移动构造函数)
}
void process_data(move_test & mt)
{
//get_lock(mt);
std::unique_lock<std::mutex> lk(get_lock(mt)); // 锁的实例转移到此处,直至本函数结束销毁实例才解锁。
do_something(mt);
}
int main()
{
move_test mt;
mt.i = 0;
std::thread t{ process_data,std::ref(mt) };//引用--std::ref()
mt.some_mutex.lock();
prepare_data(mt);
do_something(mt);
mt.some_mutex.unlock();
t.join();
system("pause");
return 0;
}
锁的粒度
锁的粒度是一个“摆手术语”(hand-waving term),用来描述通过一个锁保护着的数据量大小。一个细粒度锁(a fine-grained lock)能够保护较小的数据量,一个粗粒度锁(a coarse-grained lock)能够保护较多的数据量。class Y
{
private:
int some_detail;
mutable std::mutex m;//在const成员函数中锁变量
int get_detail() const
{
std::lock_guard<std::mutex> lock_a(m); // 锁
return some_detail;
}
public:
Y(int sd) :some_detail(sd) {}
friend bool operator==(Y const& lhs, Y const& rhs)
{
if (&lhs == &rhs)//判断不是同一对象!!!
return true;
const int lhs_value = lhs.get_detail(); // 锁住变量,赋值运算符(int成本较低)
const int rhs_value = rhs.get_detail();
return lhs_value == rhs_value; //比较复制品
}
};
当操作符返回true时,那就意味着在这个时间点上的lhs.some_detail与在另一个时间点的rhs.some_detail相同。这两个值在读取之后,可能会被任意的方式所修改;两个值会在②和③出进行交换,这样就会失去比较的意义。等价比较可能会返回true,来表明这两个值时相等的,实际上这两个值相等的情况可能就发生在一瞬间。这样的变化要小心,语义操作是无法改变一个问题的比较方式:当你持有锁的时间没有达到整个操作时间,就会让自己处于条件竞争的状态。
有时,只是没有一个合适粒度级别,因为并不是所有对数据结构的访问都需要同一级的保护。这个例子中,就需要寻找一个合适的机制,去替换 std::mutex 。
有时,只是没有一个合适粒度级别,因为并不是所有对数据结构的访问都需要同一级的保护。这个例子中,就需要寻找一个合适的机制,去替换 std::mutex 。
保护共享数据的替代设施
共享数据在并发访问和初始化时(都需要保护),但是之后需要进行隐式同步。这可能是因为数据作为只读方式创建,所以没有同步问题;或者因为必要的保护作为对数据操作的一部分,所以隐式的执行。任何情况下,数据初始化后锁住一个互斥量,纯粹是为了保护其初始化过程(这是没有必要的),并且这会给性能带来不必要的冲击。出于以上的原因,C++标准提供了一种纯粹保护共享数据初始化过程的机制。
保护共享数据的初始化过程
延迟初始化(Lazy initialization)在单线程代码很常见——每一个操作都需要先对源进行检查,为了了解数据是否被初始化,然后在其使用前决定,数据是否需要初始化:
std::shared_ptr<some_resource> resource_ptr;
void foo()
{
if (!resource_ptr)
{
resource_ptr.reset(new some_resource); // 1
}
resource_ptr->do_something();
}
使用一个互斥量的延迟初始化(线程安全)过程:
std::shared_ptr<some_resource> resource_ptr;
std::mutex resource_mutex;
void foo()
{
std::unique_lock<std::mutex> lk(resource_mutex); // 所有线程在此序列化
if (!resource_ptr)
{
resource_ptr.reset(new some_resource); // 只有初始化过程需要保护
}
lk.unlock();
resource_ptr->do_something();
}void undefined_behaviour_with_double_checked_locking()
{
if (!resource_ptr) // 1,此时有可能别的线程执行3,初始化
{
std::lock_guard<std::mutex> lk(resource_mutex);
if (!resource_ptr) // 2
{
resource_ptr.reset(new some_resource); // 3
}
}
resource_ptr->do_something(); // 4,那么在这里得到的结果就不同了
}std::shared_ptr<some_resource> resource_ptr;
std::once_flag resource_flag; // 1
void init_resource()
{
resource_ptr.reset(new some_resource);
}
void foo()
{
std::call_once(resource_flag, init_resource); // 可以完整的进行一次初始化
resource_ptr->do_something();
}
在这种情况下,初始化通过调用函数完成,同样这样操作使用类中的函数操作符来实现同样很简单。如同大多数在标准库中的函数一样,或作为函数被调用,或作为参数被传递, std::call_once 可以和任何函数或可调用对象一起使用。
使用 std::call_once 作为类成员的延迟初始化(线程安全)
使用 std::call_once 作为类成员的延迟初始化(线程安全)
class X
{
private:
connection_info connection_details;
connection_handle connection;
std::once_flag connection_init_flag;
void open_connection()
{
connection = connection_manager.open(connection_details);
}
public:
X(connection_info const& connection_details_) :
connection_details(connection_details_)
{}
void send_data(data_packet const& data) // 1
{
std::call_once(connection_init_flag, &X::open_connection, this); // 2,传入this指针(成员函数),延迟初始化
connection.send_data(data);
}
data_packet receive_data() // 3
{
std::call_once(connection_init_flag, &X::open_connection, this); // 2
return connection.receive_data();
}
};
值得注意的是, std::mutex 和 std::one_flag 的实例就不能拷贝和移动,所以当你使用它们作为类成员函数,如果你需要用到他们,你就得显示定义这些特殊的成员函数。
static类型初始化
初始化及定义完全在一个线程中发生,并且没有其他线程可在初始化完成前对其进行处理,条件竞争终止于初始化阶段,这样比在之后再去处理好的多。在只需要一个全局实例情况下,这里提供一个 std::call_once 的替代方案:class my_class;
my_class& get_my_class_instance()
{
static my_class instance; // 线程安全的初始化过程
return instance;
}保护很少更新的数据结构
“读者-写者锁”(reader-writer mutex),其允许两种不同的使用方式:一个“作者”线程独占访问和共享访问,让多个“读者”线程并发访问。使用 boost::shared_mutex 来做同步。对于更新操作,可以使用 std::lock_guard<boost::shared_mutex> 和 std::unique_lock<boost::shared_mutex> 上锁。作为 std::mutex 的替代方案,与 std::mutex 所做的一样,这就能保证更新线程的独占访问。因为其他线程不需要去修改数据结构,所以其可以使用 boost::shared_lock<boost::shared_mutex> 获取访问权。
唯一的限制:当任一线程拥有一个共享锁时,这个线程就会尝试获取一个独占锁,直到其他线程放弃他们的锁;同样的,当任一线程拥有一个独占锁时,其他线程就无法获得共享锁或独占锁,直到第一个线程放弃其拥有的锁。
使用 boost::shared_mutex 对数据结构进行保护
#include <iostream>
#include <thread>
#include <map>
#include <string>
#include <mutex>
#include <boost/thread/shared_mutex.hpp>
#include <boost/thread/thread.hpp>
class dns_entry {
std::string s;
public:
dns_entry() = default;//默认构造函数
dns_entry(const std::string &_s):s(_s){}
std::string get() const
{
return s;
}
};
class dns_cache
{
std::map<std::string, dns_entry> entries;
mutable boost::shared_mutex entry_mutex;
public:
dns_entry find_entry(const std::string & domain) const
{
boost::shared_lock<boost::shared_mutex> lk(entry_mutex); // 1,保护共享和只读权限,其他线程只可以find,不可以update
std::cout << "共享\t" << domain << std::endl;
const std::map<std::string, dns_entry>::const_iterator it =
entries.find(domain);
std::cout << "共享锁\t" << domain <<"释放"<< std::endl;
return (it == entries.end()) ? dns_entry() : it->second;
}
void update_or_add_entry(const std::string & domain,
const dns_entry & dns_details)
{
std::lock_guard<boost::shared_mutex> lk(entry_mutex); // 2,提供独占访问权限,其他线程不能对其进行任何操作
std::cout << "独占锁......" << domain << "......" << dns_details.get() << std::endl;
entries[domain] = dns_details;
std::cout << "独占锁......" << domain << "......" << dns_details.get() <<"......释放"<< std::endl;
}
};
void funA(const char &c,dns_cache &dns_c)
{
std::string s{ "dm" };
for (unsigned i = 0;i < 5;++i)
{
dns_entry ds{ "dns_d" + s };
dns_c.update_or_add_entry(s, ds);
s += c;
}
}
void funB(const char &c, const dns_cache &dns_c)
{
std::string s{ "dm" };
for (unsigned i = 0;i < 5;++i)
{
dns_entry de=dns_c.find_entry(s);
s += c;
}
}
int main()
{
dns_cache dc;
char c1 = 'a', c2 = 'b';
std::thread t1{ funA,std::ref(c1),std::ref(dc) }, t2{ funA,std::ref(c2),std::ref(dc) },//update
t3{ funB,std::ref(c1),std::ref(dc) }, t4{ funB,std::ref(c2),std::ref(dc) };//find
system("pause");
return 0;
}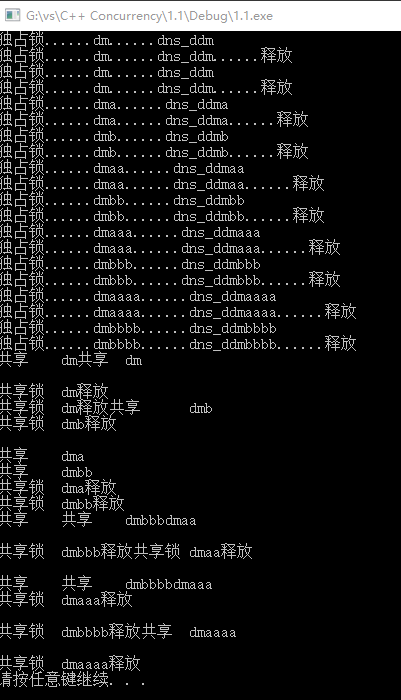
通过上图可以看出,独占锁都是一对一,开始和结束。而共享锁则没有规律可寻。符合要求。
嵌套锁
在某些情况下,一个线程尝试获取同一个互斥量多次,而没有对其进行一次释放是可以的。之所以可以,是因为C++标准库提供了 std::recursive_mutex 类。其功能与 std::mutex 类似,除了你可以从同一线程的单个实例上获取多个锁。互斥量锁住其他线程前,你必须释放你拥有的所有锁,所以当你调用lock()三次时,你也必须调用unlock()三次。正确使
用 std::lock_guard<std::recursive_mutex> 和 std::unique_lock<std::recursice_mutex> 可以帮你处理这些问题。
用 std::lock_guard<std::recursive_mutex> 和 std::unique_lock<std::recursice_mutex> 可以帮你处理这些问题。
大多数情况下,当你需要嵌套锁时,就要对你的设计进行改动。嵌套锁一般用在可并发访问的类上,所以其拥互斥量保护其成员数据。每个公共成员函数都会对互斥量上锁,然后完成对应的功能,之后再解锁互斥量。不过,有时成员函数会调用另一个成员函数,这种情况下,第二个成员函数也会试图锁住互斥量,这就会导致未定义行为的发生。“变通的”(quickand-dirty)解决方案会将互斥量转为嵌套锁,第二个成员函数就能成功的进行上锁,并且函数能继续执行。
但是,这样的使用方式是不推荐的,因为其过于草率,并且不合理。特别是,当锁被持有时,对应类的不变量通常正在被修改。这意味着,当不变量正在改变的时候,第二个成员函数还需要继续执行。一个比较好的方式是,从中提取出一个函数作为类的私有成员,并且让其他成员函数都对其进行调用,这个私有成员函数不会对互斥量进行上锁(在调用前必须获得锁)。然后,你仔细考虑一下,在这种情况调用新函数时,数据的状态。















 1588
1588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









