







今天介绍EchoMimicV2,EchoMimicV2是阿里蚂蚁集团推出的半身人体AI数字人项目,输入参考图片、音频、和手部姿势序列生成动画视频(对图片的规范要求比较高,图片规范的话效果还可以),感兴趣的还可以去了解一下EchoMimicV1,代码搬运自项目官方
1. 前言/动机
1.1 问题/挑战1:高质量的人类动画生成面临实际挑战, 如额外的控制条件、繁琐的条件注入模块,
描述:
当前常用的控制条件(如文本、音频、姿势、光流、动作图)为生成逼真动画提供了良好基础,但引入更多的辅助条件会导致两个问题:一是 多条件之间协调性差,造成训练不稳定;二是条件注入模块结构复杂,推理延迟显著增加。
解决方案:
采用音频-姿势动态协调的训练策略 以调节音频和姿势两个条件输入,并减少姿势条件的冗余性。 同时引入PHD Loss(阶段性损失)以取代对 冗余控制条件的依赖。
1.2 问题/挑战2:头部区域限制。
描述:
以往的人类动画主要聚焦于生成头部区域的视频,忽视了音频与肩膀一下身体部分的同步
解决方案:
目前有一个直接的方法,就是加入与肩部以下身体相关的条件比如半身关键点图(EMO2也使用 了),但此文章认为使用这种方法会引入更多的复杂条件加剧问题1
此文章保留了手部姿势条件作为输入用于手势动画的生成,实现了半身区域的动画驱动(其实生成的动画只有手动)
目标:简化不必要输入条件,实现优秀的人类半身动画生成。
1.3 创新点:
- 采用新颖的音频-姿态动态协调策略(APHD)
- 发现一种新的数据增强方式
- 设计阶段性去噪损失
- 提出新的评价基准
- 项目地址:https://antgroup.github.io/ai/echomimic_v2/
- github:https://github.com/antgroup/echomimic_v2?tab=readme-ov-file
2. 方法
- 输入:需要处理的图片,一段音频(不长于5秒),一段特定的手部关键点序列
- 输出:一段人物动画
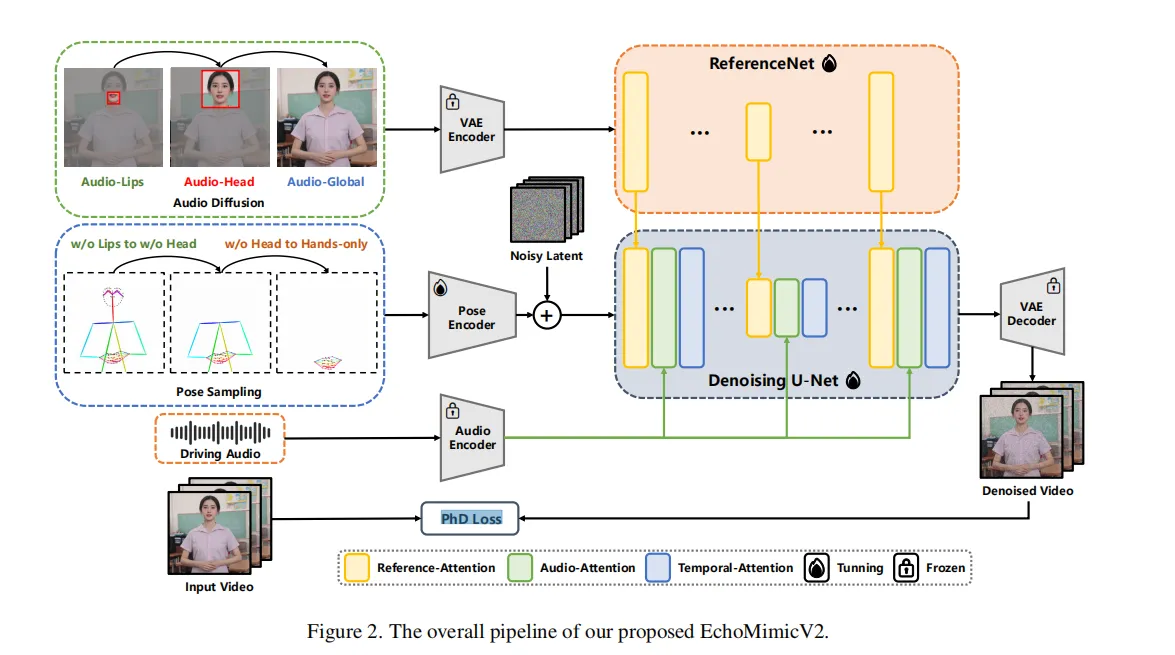
2.1 音频-姿态动态对齐( Audio-Pose Dynamic Harmonization )
2.2.1 姿态采样(Pose Sampling, PS)
- 迭代姿态采样阶段
在训练的每次迭代中,我们以逐步递增的概率对姿态条件进行 dropout(舍弃),这种渐进式的姿态 dropout 策略有助于减弱模型对姿态条件的过度依赖。 - 空间姿态采样阶段
空间维度上,文章按顺序删除部分关键点来采样姿态条件,具体顺序为:- 首先去除嘴唇部分(lips)的关键点,
- 接着是头部(head),
- 最后是身体部分(body/hands)
通过逐步降低姿态条件对嘴唇动作、面部表情和身体(如呼吸节奏)的控制力,逐步为音频驱动过程让位,使音频条件在生成中扮演更主导的角色。
class DWposeDetector:
"""
A pose detect method for image-like data.
Parameters:
model_det: (str) serialized ONNX format model path,
such as https://huggingface.co/yzd-v/DWPose/blob/main/yolox_l.onnx
model_pose: (str) serialized ONNX format model path,
such as https://huggingface.co/yzd-v/DWPose/blob/main/dw-ll_ucoco_384.onnx
device: (str) 'cpu' or 'cuda:{device_id}'
"""
def __init__(self, model_det, model_pose, device='cuda'):
self.args = model_det, model_pose, device
def release_memory(self):
if hasattr(self, 'pose_estimation'):
del self.pose_estimation
import gc; gc.collect()
def __call__(self, oriImg):
if not hasattr(self, 'pose_estimation'):
self.pose_estimation = Wholebody(*self.args)
oriImg = oriImg.copy()
H, W, C = oriImg.shape
with torch.no_grad():
candidate, score = self.pose_estimation(oriImg)
nums, _, locs = candidate.shape
candidate[..., 0] /= float(W)
candidate[..., 1] /= float(H)
body = candidate[:, :18].copy()
body = body.reshape(nums * 18, locs)
subset = score[:, :18].copy()
for i in range(len(subset)):
for j in range(len(subset[i])):
if subset[i][j] > 0.3:
subset[i][j] = int(18 * i + j)
else:
subset[i][j] = -1
faces = candidate[:, 24:92]
hands = candidate[:, 92:113]
hands = np.vstack([hands, candidate[:, 113:]])
faces_score = score[:, 24:92]
hands_score = np.vstack([score[:, 92:113], score[:, 113:]])
bodies = dict(candidate=body, subset=subset, score=score[:, :18])
pose = dict(bodies=bodies, hands=hands, hands_score=hands_score, faces=faces, faces_score=faces_score)
return pose
dwpose_detector = DWposeDetector(
model_det="your_path_to_yolox_l.onnx",
model_pose="your_path_to_dw-ll_ucoco_384.onnx",
device=device)
print('dwpose_detector init ok', device)
2.1.2 音频扩散(Audio Diffusion, AD)
在空间级别姿态采样阶段(Spatial Level Pose Sampling)中,音频条件开始逐步集成。
- 音频-嘴唇同步(Audio-Lips Synchronization)
- 音频-面部同步(Audio-Face Synchronization)
- 音频-身体关联(Audio-Body Correlation)
目标是通过逐步引入音频条件来增强动作与音频的同步,并通过不同阶段的音频控制来精细化面部和身体动作的生成。通过这种策略,系统能够在保持高质量生成的同时有效协调音频和姿态条件。
class Wav2Vec(ModelMixin):
def __init__(self, model_path):
super(Wav2Vec, self).__init__()
self.processor = Wav2Vec2Processor.from_pretrained(model_path)
self.wav2Vec = Wav2Vec2Model.from_pretrained(model_path)
self.wav2Vec.eval()
def forward(self, x):
with torch.no_grad():
return self.wav2Vec(x).last_hidden_state
# def forward(self, x):
# return self.wav2Vec(x).last_hidden_state
def process(self, x):
return self.processor(x, sampling_rate=16000, return_tensors="pt").input_values.to(self.device)
class AudioFeatureMapper(ModelMixin):
def __init__(self, input_num=15, output_num=77, model_path=None):
super(AudioFeatureMapper, self).__init__()
self.linear = nn.Linear(input_num, output_num)
if model_path is not None:
self.load_state_dict(torch.load(model_path))
def forward(self, x):
# print(x.shape)
result = self.linear(x.permute(0, 2, 1))
result = result.permute(0, 2, 1)
# result = self.linear(x)
return result
2.2 Pose Encoder + Denoising U-Net 模块
输入:初始关键点图 P_init(包括人体的骨架姿态信息)。
功能:提取人体姿态特征,并利用扩散模型中的 Denoising U-Net 生成初步的视频帧。
训练策略:第一阶段冻结音频模块,仅基于姿态训练该模块,保证视觉结构的一致性
部分参考代码
class PoseEncoder(ModelMixin):
def __init__(
self,
conditioning_embedding_channels: int,
conditioning_channels: int = 1,
block_out_channels: Tuple[int] = (16, 32, 64, 128),
):
super().__init__()
self.conv_in = InflatedConv3d(
conditioning_channels, block_out_channels[0], kernel_size=3, padding=1
)
self.blocks = nn.ModuleList([])
for i in range(len(block_out_channels) - 1):
channel_in = block_out_channels[i]
channel_out = block_out_channels[i + 1]
self.blocks.append(
InflatedConv3d(channel_in, channel_in, kernel_size=3, padding=1)
)
self.blocks.append(
InflatedConv3d(
channel_in, channel_out, kernel_size=3, padding=1, stride=2
)
)
self.conv_out = zero_module(
InflatedConv3d(
block_out_channels[-1],
conditioning_embedding_channels,
kernel_size=3,
padding=1,
)
)
def forward(self, conditioning):
embedding = self.conv_in(conditioning)
embedding = F.silu(embedding)
for block in self.blocks:
embedding = block(embedding)
embedding = F.silu(embedding)
embedding = self.conv_out(embedding)
return embedding
2.3 Audio Cross Attention 模块(音频跨模态注意力)
输入:语音音频的特征向量。
功能:通过跨模态注意力机制,将语音中的节奏、情感、停顿等信息引入视频帧生成过程,驱动面部、身体和手部动作的动态变化。
阶段性启用:在初始训练中是 masked(禁用) 的,之后与姿态模块联合训练,实现“音频-姿态”的协同控制。
class AudioCrossAttention(Attention):
def __init__(
self,
attention_mode=None,
cross_frame_attention_mode=None,
temporal_position_encoding=False,
temporal_position_encoding_max_len=24,
*args,
**kwargs,
):
super().__init__(*args, **kwargs)
assert attention_mode == "Temporal"
self.attention_mode = attention_mode
self.is_cross_attention = kwargs["cross_attention_dim"] is not None
self.pos_encoder = (
PositionalEncoding(
kwargs["query_dim"],
dropout=0.0,
max_len=temporal_position_encoding_max_len,
)
if (temporal_position_encoding and attention_mode == "Temporal")
else None
)
def extra_repr(self):
return f"(Module Info) Attention_Mode: {self.attention_mode}, Is_Cross_Attention: {self.is_cross_attention}"
def set_use_memory_efficient_attention_xformers(
self,
use_memory_efficient_attention_xformers: bool,
attention_op: Optional[Callable] = None,
):
if use_memory_efficient_attention_xformers:
if not is_xformers_available():
raise ModuleNotFoundError(
(
"Refer to https://github.com/facebookresearch/xformers for more information on how to install"
" xformers"
),
name="xformers",
)
elif not torch.cuda.is_available():
raise ValueError(
"torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is"
" only available for GPU "
)
else:
try:
# Make sure we can run the memory efficient attention
_ = xformers.ops.memory_efficient_attention(
torch.randn((1, 2, 40), device="cuda"),
torch.randn((1, 2, 40), device="cuda"),
torch.randn((1, 2, 40), device="cuda"),
)
except Exception as e:
raise e
# XFormersAttnProcessor corrupts video generation and work with Pytorch 1.13.
# Pytorch 2.0.1 AttnProcessor works the same as XFormersAttnProcessor in Pytorch 1.13.
# You don't need XFormersAttnProcessor here.
# processor = XFormersAttnProcessor(
# attention_op=attention_op,
# )
processor = AttnProcessor()
else:
processor = AttnProcessor()
self.set_processor(processor)
def forward(
self,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
video_length=None,
**cross_attention_kwargs,
):
if self.attention_mode == "Temporal":
d = hidden_states.shape[1] # d means HxW
hidden_states = rearrange(
hidden_states, "(b f) d c -> (b d) f c", f=video_length
)
if self.pos_encoder is not None:
hidden_states = self.pos_encoder(hidden_states)
# audio b, f, a, c, a=audio_length
# a = encoder_hidden_states.shape[1]
# encoder_hidden_states = rearrange(
# encoder_hidden_states, "b f a c -> (b d) f c", f=video_length
# )
encoder_hidden_states = (
repeat(encoder_hidden_states, "b n c -> (b d) n c", d=d)
if encoder_hidden_states is not None
else encoder_hidden_states
)
else:
raise NotImplementedError
hidden_states = self.processor(
self,
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
if self.attention_mode == "Temporal":
hidden_states = rearrange(hidden_states, "(b d) f c -> (b f) d c", d=d)
return hidden_states
2.4 Temporal Attention 模块(时间注意力)
功能:建模视频帧之间的时间一致性和动作连续性。
训练阶段:第二阶段中单独优化此模块,冻结其他模块,进一步提升动画流畅度和时序协调性
class TemporalTransformerBlock(nn.Module):
def __init__(
self,
dim,
num_attention_heads,
attention_head_dim,
attention_block_types=(
"Temporal_Self",
"Temporal_Self",
),
dropout=0.0,
norm_num_groups=32,
cross_attention_dim=768,
activation_fn="geglu",
attention_bias=False,
upcast_attention=False,
cross_frame_attention_mode=None,
temporal_position_encoding=False,
temporal_position_encoding_max_len=24,
):
super().__init__()
attention_blocks = []
norms = []
for block_name in attention_block_types:
attention_blocks.append(
VersatileAttention(
attention_mode=block_name.split("_")[0],
cross_attention_dim=cross_attention_dim
if block_name.endswith("_Cross")
else None,
query_dim=dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
dropout=dropout,
bias=attention_bias,
upcast_attention=upcast_attention,
cross_frame_attention_mode=cross_frame_attention_mode,
temporal_position_encoding=temporal_position_encoding,
temporal_position_encoding_max_len=temporal_position_encoding_max_len,
)
)
norms.append(nn.LayerNorm(dim))
self.attention_blocks = nn.ModuleList(attention_blocks)
self.norms = nn.ModuleList(norms)
self.ff = FeedForward(dim, dropout=dropout, activation_fn=activation_fn)
self.ff_norm = nn.LayerNorm(dim)
def forward(
self,
hidden_states,
encoder_hidden_states=None,
attention_mask=None,
video_length=None,
):
for attention_block, norm in zip(self.attention_blocks, self.norms):
norm_hidden_states = norm(hidden_states)
hidden_states = (
attention_block(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states
if attention_block.is_cross_attention
else None,
video_length=video_length,
)
+ hidden_states
)
hidden_states = self.ff(self.ff_norm(hidden_states)) + hidden_states
output = hidden_states
return output
2.5 阶段特定去噪损失(PhD Loss)
通过 阶段特定去噪损失(PhD Loss,LPhD)来提高性能。此文将多时间步去噪过程分为三个阶段,每个阶段的主要任务不同:
1)以姿势为主的阶段(早期)S1;
2)以细节为主的阶段(中期)S2;
3)以质量为主的阶段(最终)S3。
根据这些阶段,LPhD 包括三个定制的损失,分别为:姿势主导损失 Lpose、细节主导损失 Ldetail 和 低级损失 Llow,这些损失在三个阶段中依次应用。
3. 实验
3.1 数据集
训练数据集由三部分组成:完全姿势驱动数据集、半身数据集和头部数据集。
- 完全姿势驱动数据集:文章使用 HumanVid[29] 作为完全姿势驱动数据集,该数据集包含约 20,000 个高质量的以人为中心的视频,并提供了 2D 姿势注释。
- 半身数据集:半身训练数据集来源于互联网视频,重点关注半身说话场景。该数据集包含 160 小时的视频,涵盖了超过 10,000 个身份。
- 头部数据集:头部数据集来自 EchoMimic 中使用的训练数据集,包含 540 小时的讲述视频。
3.2 评估指标(Evaluation Metric)
3.2.1 视觉质量指标(Low-level Visual Quality):
- FID(Fréchet Inception Distance):衡量生成图像与真实图像在特征空间的分布差异。
- FVD(Fréchet Video Distance):衡量视频序列之间的视觉连贯性和真实性。
- PSNR(Peak Signal-to-Noise Ratio):评估图像的重构精度。
- SSIM(Structural Similarity Index):衡量图像结构相似度。
- E-FID(Expression-FID):使用 Inception 网络特征提取人脸重建参数,计算这些参数之间的FID,衡量表情真实性差异。
3.2.2 身份一致性指标(Identity Consistency)
- CSIM(Cosine Similarity):计算参考图像与生成视频帧中人脸特征之间的余弦相似度,用于评估身份保真度。
3.2.3 手部动画评估指标(Hand Animation Quality):
- HKC(Hand Keypoint Confidence):平均手部关键点的置信度,用于评估手部重建的质量。
- HKV(Hand Keypoint Variance):手部关键点的方差,衡量手部动作的丰富度与动态表现。
3.3 定性结果分析

上图展示了文章方法在处理不同人物和复杂动作时的适应性与稳定性,并呈现了与音频信号同步的自然动态表现。这些结果验证了 EchoMimicV2 在多样化人物与复杂姿态下的强泛化能力,展示了其在音频驱动人像视频生成领域的先进性能。
3.3.1 与姿态驱动方法的对比实验

EchoMimicV2 与当前领先的姿态驱动方法,包括 AnimateAnyone 与 MimicMotion 进行了定性对比,比较结果如上图所示。结果表明,EchoMimicV2 在结构完整性与身份一致性方面表现更优,尤其是在面部与手部等局部区域,生成的视觉效果更加自然与细腻。
3.3.2 与音频驱动方法的对比实验

文章选取了 Vlogger 与 CyberHost 进行比较。受限于这两种方法尚未开源,文章从其项目主页中获取了相关实验结果,并在相同参考图像条件下进行了对比。上图展示了对比结果,EchoMimicV2 在图像质量和动作自然性方面均优于 Vlogger 与 CyberHost,表现出更高的视觉保真度与运动协调性。
3.4 定性结果分析
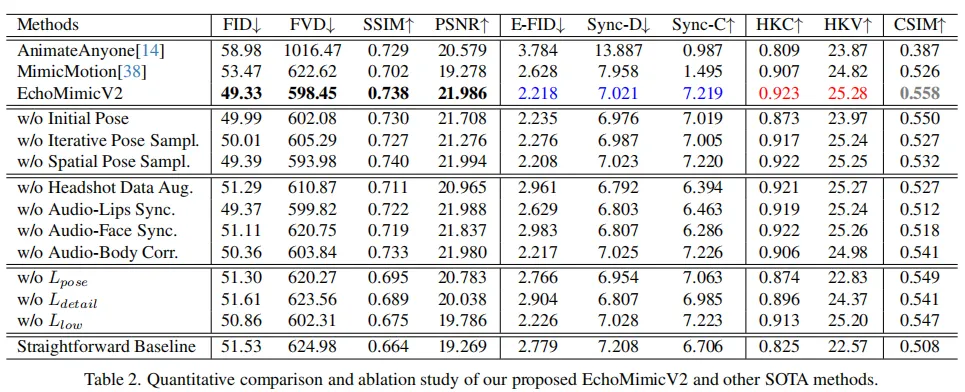
EchoMimicV2 在低层次图像质量指标(如 FID、FVD、SSIM 和 PSNR)上表现优异,表明其生成结果在视觉保真度方面具有明显优势。同时,在音频-唇形同步相关的 Sync-C 和 Sync-D 指标上亦取得了具有竞争力的结果,验证了模型在音频驱动下的协调性与同步能力。
此外,在身份一致性评估指标 CSIM 上,EchoMimicV2 同样优于对比方法,进一步强调其对参考人物面部特征的良好保持能力。值得一提的是,EchoMimicV2 在手部动画的质量评估指标 HKV(Hand Keypoint Variance) 与 HKC(Hand Keypoint Confidence) 上亦取得了最新的 SOTA 成绩,表明其在生成丰富而准确的手部动作方面具备强大优势。
4. 部署
部署请保证:
- CUDA >= 11.7, Python == 3.10
部署过程:
下载代码:
git clone https://github.com/antgroup/echomimic_v2
cd echomimic_v2
作者提供了自动部署脚本(推荐):
sh linux_setup.sh
自动部署出错也可手动部署:
- 创建新的虚拟环境
conda create -n echomimic python=3.10
conda activate echomimic
- 安装依赖:
cd echomimic_v2
pip install pip -U
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 xformers==0.0.28.post3 --index-url https://download.pytorch.org/whl/cu124
pip install torchao --index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt//注释掉里面的torch
pip install --no-deps facenet_pytorch==2.6.0
下载ffmpeg-static并配置环境变量:
export FFMPEG_PATH=/path/to/ffmpeg-4.4-amd64-static
下载权重文件:
git lfs install
git clone https://huggingface.co/BadToBest/EchoMimicV2 pretrained_weights
部署遇到的问题:
1、 出现报错 TypeError: argument of type ‘bool‘ is not iterable,解决方法如下:
pip install pydantic==2.10.6
2、export FFMPEG_PATH=/path/to/ffmpeg-4.4-amd64-static 需要添加到环境配置文件里面去(注意改为自己ffmpeg路径)
5. 测试
#进入项目文件夹
cd echomimic_v2
#激活安装好依赖的虚拟环境
conda activate echomimic
运行python infer.py --config='./configs/prompts/infer.yaml'(训练好的模块权重文件路径在infer.yaml里面配置)使用默认配置推理生成图片。
命令行运行:
python infer.py \
--ref_images_dir ./test_picture \
--refimg_name test3-3/0001.jpg \
--audio_dir ./assets/halfbody_demo/audio \
--audio_name chinese/echomimicv2_woman.wav \
--pose_dir ./assets/halfbody_demo/pose \
--pose_name 01
--cfg 3.0 -W 768 -H 768 -L 240 --steps 50 --fps 24
修改ref_images_dir和refimg_name指定自己要生成的图片,修改audio_dir和audio_name指定自己的音频文件,手势文件目前只能使用官方提供的
参数说明:
- cfg:Classifier-Free Guidance Scal,用于控制扩散模型生成时对条件的依赖程度。
实际意义:数值越大,生成结果越接近参考图(比如脸型更像);数值小则更多样、变化大。一般设置 2~4 之间比较稳妥。 - steps:扩散过程中的采样步数(即推理时去噪的迭代次数)。
实际意义:步数越多,画面越精细,但推理越慢;步数太少,画质可能模糊或有伪影。 - fps:生成视频的帧率(Frames Per Second)。
实际意义:24fps是影视行业标准,看起来流畅自然。 - W、H:输出图片(单帧)宽度和高度。
实际意义:控制生成图片的尺寸大小。 - L:推理时使用多少个pose序列(动作帧数)。
实际意义:用来控制生成的视频时长(时长=L/fps)。 - seed:随机种子,保证生成过程可复现。
实际意义:相同的seed+相同输入,生成结果一模一样;如果想要每次都有细微变化,可以随机设seed
图像和手势需要对齐,最简单的方法是用主页提供的图作为参考图,用ControlNet或者图生图生成类似的人像
作者主页提供的图是Flux+小红书Lora生成的,其中用到的Lora如下:
- 女版Lora:https://www.liblib.art/modelinfo/d9675e37370e493ab8bf52046827a2b0?via=techmoon&versionUuid=7852ee527ca34d8b940d0749a75e4b67
- 男版Lora:https://www.liblib.art/modelinfo/8963f90cea46474b84fd4bbfc990e0cc?from=search&versionUuid=61172bdb46a6412e817c5a1bf4a72f6c
总结
- 优点:支持不同尺寸图片输入,背景简洁的半身露手图片效果较好,图像和手势对齐的时候效果最好,支持多种格式音频输入(mp3和wav)
- 缺点:依赖于预定义的手部姿态序列,需要人工输入来保证生成动画的高质量(目前支持的手部姿势只有七种,而且不知道怎么生成新的手势,作者未开源)
其他注意事项:
- 人物头像顶部空白需要标准化,影响视频生成,还有人物姿态也有一定影响,人物头像顶部空白会影响视频生成效果,空白过长可能导致会拉长人物,头部变形,过短可能导致头部区域超出视频外,可以适用不格式音频(wav和MP3),音唇一致情况表现良好。
- 通过调整CFG参数来降低生成噪声。调整范围为1.5-3.0,CFG越低,视频质量越好,但是嘴型效果越差。CFG越高,视频质量越差,但是嘴型效果越好,不同手势也会影响视频生成效果




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











