






最近,我在闲鱼上利用 Python 爬虫技术接了一些任务,想必你一定好奇,通过这样的方式,到底能不能挣钱,能挣多少钱?今天我就来分享一下我的经验和总结。
一、接单经历
之前 Vue 的作者尤大在微博上说:
被动收入是最能带来自由的东西,这个时代的程序员其实在创造被动收入上有天然优势,然而大部分程序员都在出卖自由为别人打工。
在闲鱼上,有很多人需要数据采集、网站爬取等技术服务,而我恰好擅长 Python 爬虫,于是便直接淘宝登录闲鱼账号,开始接单。刚开始的时候,由于没有经验和信誉,接到的任务并不多。
刚开始发布的商品都没多少人看~

但是不能放弃呀,一直挂在平台上,等着有人来找我聊,慢慢地有平台推荐,有一部分人开始了解并提需求
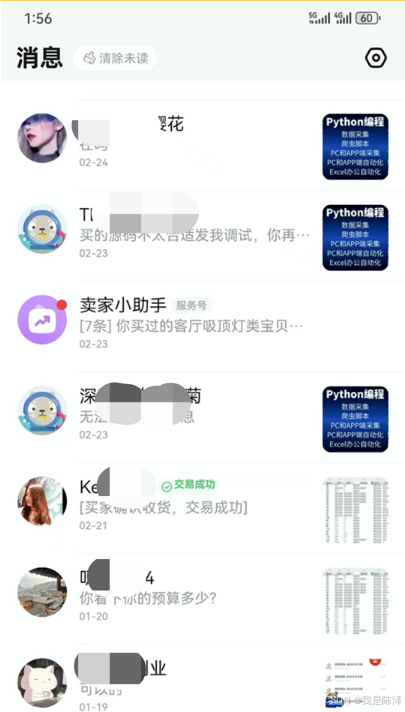
提的需求多种多样,五花八门
-
有想要王者游戏外挂的
-
有想要采集公民手机号的
-
有想要售房交易信息的
-
有抖音热门平台信息采集的
-
等等......
总之,虽然需求五花八门,我们自己要学会判断哪些能做哪些不能接,不能接的就直接拒绝不要答应他,也不要浪费时间。
二、成果与收货
通过不断地努力和积累,慢慢地我也接了几单,发布的商品有时候也通过平台曝光会有更多人找我。很大程度上,只能靠平台曝光来获取流量。

开始说接到的单子
二手房信息爬取,分为链家和房天下,给客户定制开发一个通用采集程序,一个平台600,共计1200元
说实话这个占用了很长时间,第一次合作,给他费心的好好写了程序,还讲了代码

抖音APP信息采集,260
公开工商信息采集,200
小红书APP数据采集等
武汉二手房信息采集等
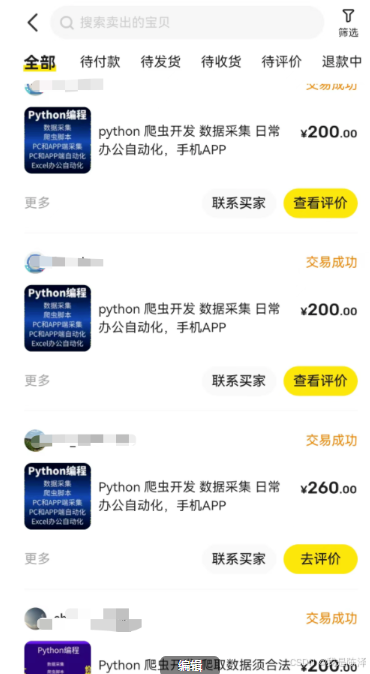
还有一些零散的需求不一一列举了。
三、总结与感悟
通过大半年的接单经历,总结了以下内容
-
对Python技术有一定要求,否则有些棘手的需求你没实力接
-
PC端相对好采集,但是要注意IP池
-
APP端最好学习逆向
-
一定不要接违法的单,接之前要先了解清楚
-
不要相信那些卖课程说的一个单子万儿八千的,不可能,大部分情况下都是几百块钱就不错了
-
尽量接小单,快速完成,快速拿钱
-
没事多赚闲鱼币,自己对发布的商品做闲鱼币推广
四、成果与收货
闲鱼 Python 爬虫接单,是一种既能提升自己技术水平,又能获得不错收益的方式。但在接单过程中,我们也需要注意保护客户隐私,维护良好的信誉,不断学习和提升自己的技术能力,才能在这个领域获得更大的成功。
以上就是我在闲鱼 Python 爬虫接单的总结和经验分享,如果你也对这方面感兴趣,不妨试试看,说不定也能获得意想不到的收获呢!
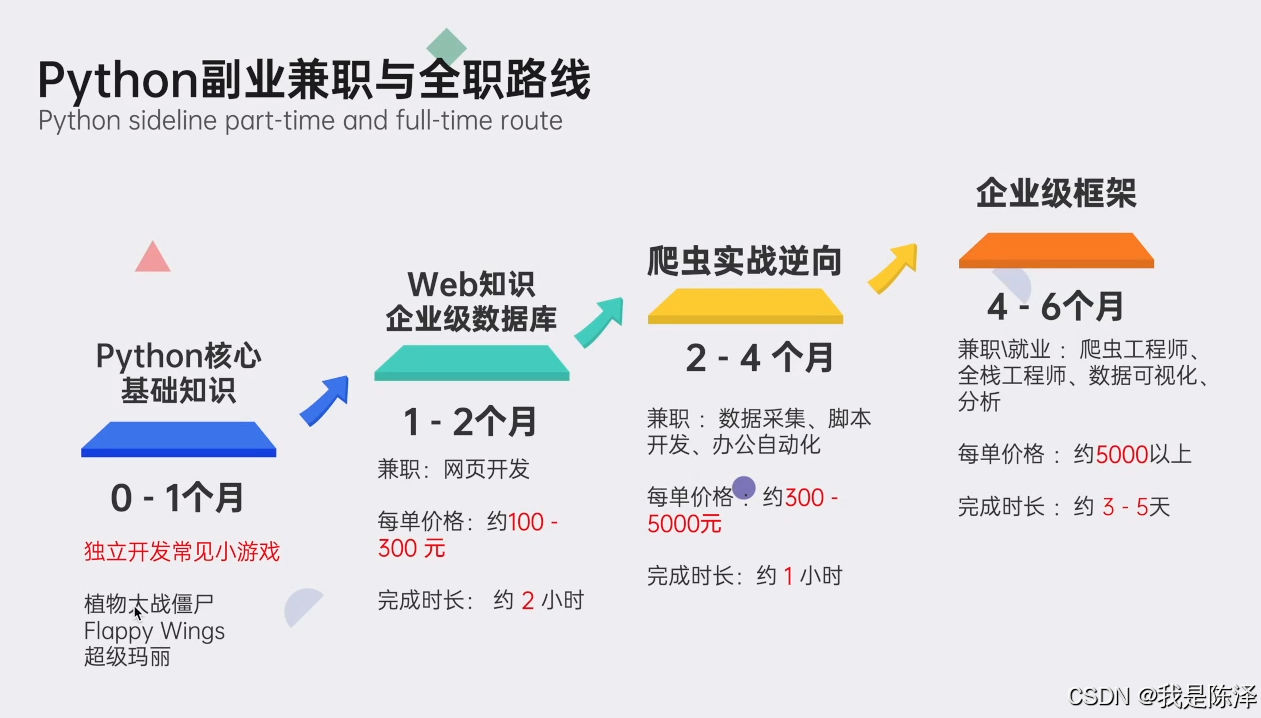
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
🌟 学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









