










Python是最受欢迎的编程语言之一,以其简单性、多功能性和可读性而闻名。
然而,在其广为人知的路径之外,隐藏着一些鲜为人知的技巧和技术,它们可以将你的Python编码技能提升到新的高度。
在本文中,我们将深入探讨十个这样的技巧,这些技巧可能不在你的日常工具包中,但可以对你的编码工作产生重大影响。
从简化字典操作到掌握路径操作,从高级迭代模式到轻量级数据结构,这些技巧中的每一个都可以让你一窥Python功能的丰富性和深度。
无论你是想要扩展知识库的经验丰富的Pythonista,还是渴望充分发挥该语言潜力的新手,这些技巧都一定会在你的Python之旅中为你提供启发和助力。
▍1、使用collections.defaultdict简化字典操作
collections.defaultdict模块允许你创建具有默认值的字典,避免关键错误并使你的代码更简洁。
from collections import defaultdict
# 没有使用defaultdict
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
# 使用defaultdict
word_count = defaultdict(int)
for word in words:
word_count[word] += 1
print(word_count)示例输出如下。
{'apple': 3, 'banana': 2, 'orange': 1}
defaultdict(<class 'int'>, {'apple': 3, 'banana': 2, 'orange': 1})▍2、使用pathlib路径操作
pathlib模块提供了一种面向对象的方法来处理文件系统路径,使你的代码更直观、更易于阅读。
from pathlib import Path
# 创建Path对象
p = Path('/usr/bin')
# 检查路径是否存在
print(p.exists())
# 遍历目录
for child in p.iterdir():
print(child)
# 组合路径
q = p / 'local' / 'bin'
print(q)如果你在基于Unix的系统上运行此脚本,你可能会看到以下输出。
True
/usr/bin/zip
/usr/bin/python3
/usr/bin/grep
/usr/bin/tar
...
/usr/bin/zcat
/usr/bin/unzip
...
/usr/bin/curl
/usr/bin/wget
...
/usr/bin/local/bin
p.exists(),True如果存在则打印/usr/bin。
for child in p.iterdir():,打印其中的每个文件和目录/usr/bin。
print(q),输出连接路径/usr/bin/local/bin。▍3、使用enumerate枚举
enumerate是一个内置函数,允许你循环可迭代对象并具有自动计数器,从而简化循环。
# 不使用enumerate
i = 0
for element in iterable:
print(i, element)
i += 1
# 使用enumerate
for i, element in enumerate(iterable):
print(i, element)
示例输出如下。
0 apple
1 banana
2 orange
0 apple
1 banana
2 orange▍4、使用zip并行迭代
zip允许你并行迭代多个可迭代对象,创建相应元素的元组,既高效又易读。
names = ['Alice', 'Bob', 'Charlie']
scores = [85, 90, 95]
# 不使用zip
for i in range(len(names)):
print(names[i], scores[i])
# 使用zip
for name, score in zip(names, scores):
print(name, score)
示例输出如下。
Alice 85
Bob 90
Charlie 95
Alice 85
Bob 90
Charlie 95▍5、使用itertools高级迭代
itertools模块包含各种可用于创建复杂迭代模式的函数,使你的代码更加强大和灵活。
import itertools
# 无限计数
for i in itertools.count(10, 2):
if i > 20:
break
print(i)
# 笛卡尔乘积
for item in itertools.product([1, 2], ['a', 'b']):
print(item)示例输出如下。
10
12
14
16
18
20
(1, 'a')
(1, 'b')
(2, 'a')
(2, 'b')▍6、使用with语句进行资源管理
with语句简化了异常处理并确保资源得到正确管理,这对于编写健壮的代码至关重要。
# 不使用with
file = open('example.txt', 'r')
try:
data = file.read()
finally:
file.close()
# 使用with
with open('example.txt', 'r') as file:
data = file.read()▍7、namedtuple轻量级数据结构
collections.namedtuple模块提供了一种简单的方法来创建轻量级、不可变的数据结构,可以使你的代码更清洁、更具自文档性。
from collections import namedtuple
# 定义一个namedtuple
Point = namedtuple('Point', ['x', 'y'])
# 创建一个实例
p = Point(10, 20)
print(p.x, p.y)示例输出如下。
10 20▍8、使用列表推导实现简洁的代码
列表推导提供了一种创建列表的简洁方法,使你的代码更具可读性,而且通常运行速度更快。
# 不使用列表表达式
squares = []
for x in range(10):
squares.append(x**2)
# 使用列表表达式
squares = [x**2 for x in range(10)]示例输出如下。
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]▍9、使用functools.lru_cache记忆法
functools.lru_cache可用于缓存昂贵的函数调用的结果,显著提高具有重复、计算密集型操作的函数的性能。
import functools
# 定义一个函数来使用递归计算斐波那契数列
@functools.lru_cache(maxsize=None) # 无限制地缓存所有结果
def fibonacci(n):
# 基本情况:斐波那契(0)为0,斐波那契(1)为1
if n < 2:
return n
# 递归情况:斐波那契(n)是斐波那契(n-1)和斐波那契(n-2)的总和
return fibonacci(n - 1) + fibonacci(n - 2)
# 使用大量输入测试该函数,以查看性能优势
if __name__ == "__main__":
import time
# 计算不使用记忆的斐波那契数35
start_time = time.time()
print(f"Fibonacci(35) without memoization: {fibonacci(35)}")
print(f"Time taken without memoization: {time.time() - start_time} seconds")
# 重置缓存以进行比较
fibonacci.cache_clear()
# 使用记忆法计算35的斐波那契
start_time = time.time()
print(f"Fibonacci(35) with memoization: {fibonacci(35)}")
print(f"Time taken with memoization: {time.time() - start_time} seconds")
# 显示缓存信息
print(f"Cache info: {fibonacci.cache_info()}")
示例输出如下。
Fibonacci(35) without memoization: 9227465
Time taken without memoization: 0.00012087821960449219 seconds
Fibonacci(35) with memoization: 9227465
Time taken with memoization: 0.000007867813110351562 seconds
Cache info: CacheInfo(hits=68, misses=36, maxsize=None, currsize=36)
▍10、使用“_”作为一次性变量
在循环或解包时,当不需要该值时,通常将“_”用作一次性变量,从而使你的代码更清晰,并表明该变量被故意忽略。
# 带有一次性变量的循环
for _ in range(5):
print("Hello, World!")
# 用一次性变量拆包
a, _, b = (1, 2, 3)
print(a, b)示例输出如下。
Hello, World!
Hello, World!
Hello, World!
Hello, World!
Hello, World!
1 3这些鲜为人知的Python技巧可以帮助你编写更高效、更易读、更Pythonic的代码。
无论你是简化字典操作、更直观地管理文件路径,还是利用高级迭代技术,这些技巧都可以增强你的开发过程。
尝试这些技巧并将它们融入你的编码实践中,以成为更熟练的Python开发人员。
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
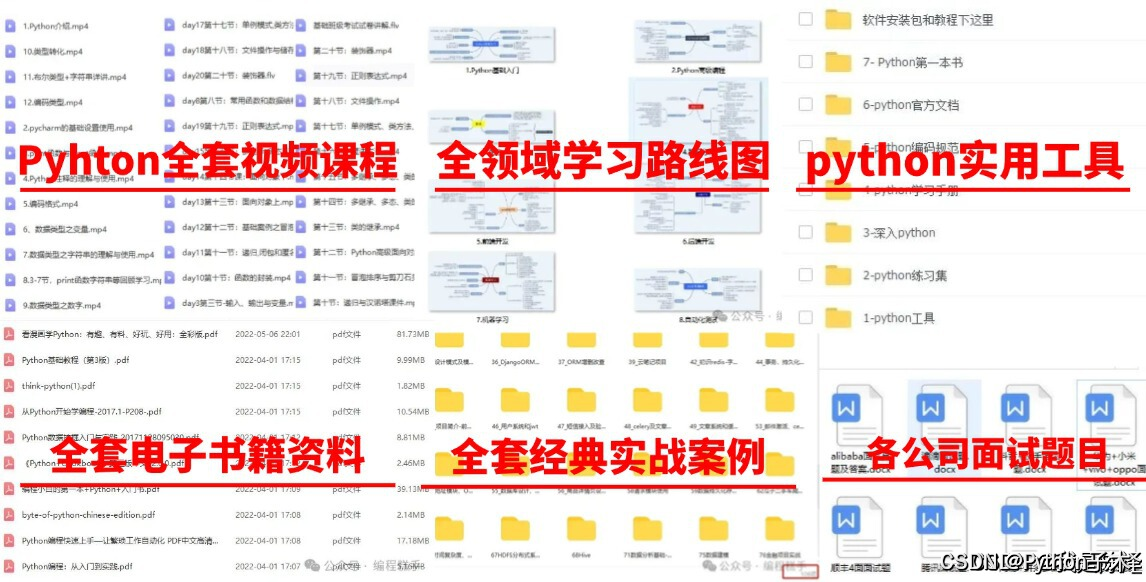
🌟 学习大礼包包含内容:
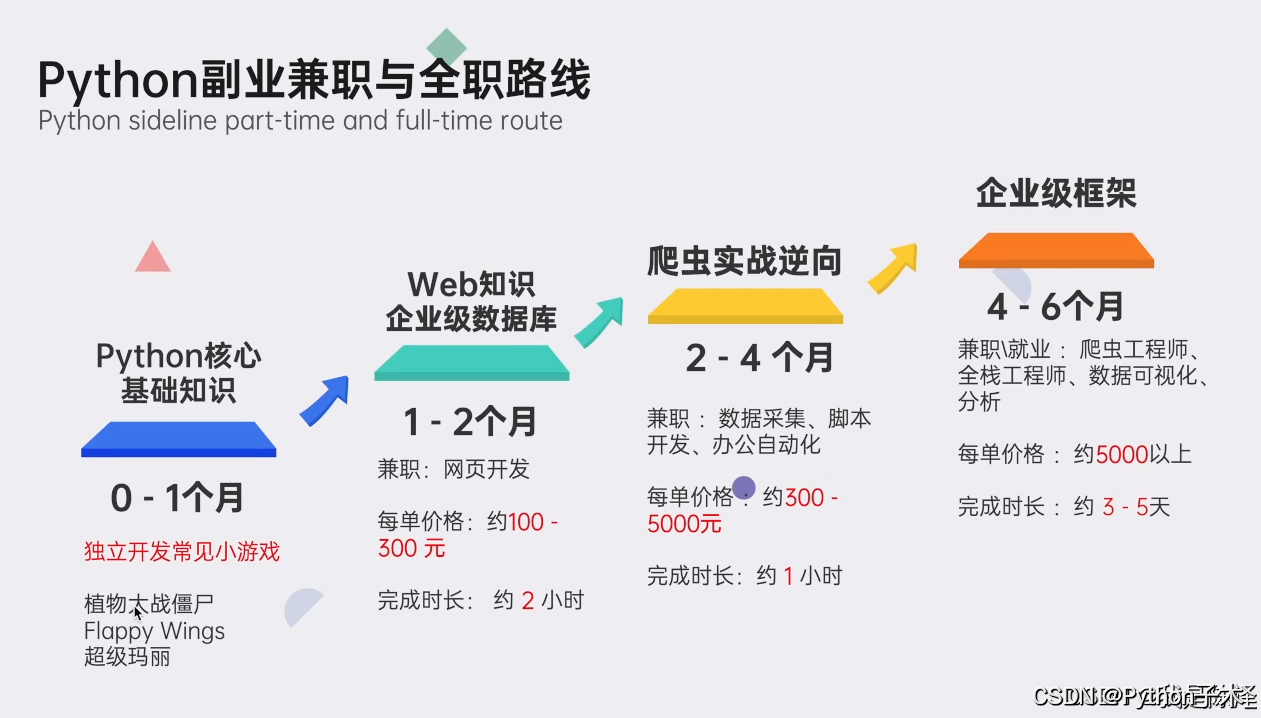
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能

















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









