







上一篇博客简单介绍了分布式的发展历史和基本概念
本篇博客则将以电商系统为例,详细介绍分布式发展的过程
假设我们的电商系统中只有三个模块:用户模块,交易模块和商品模块
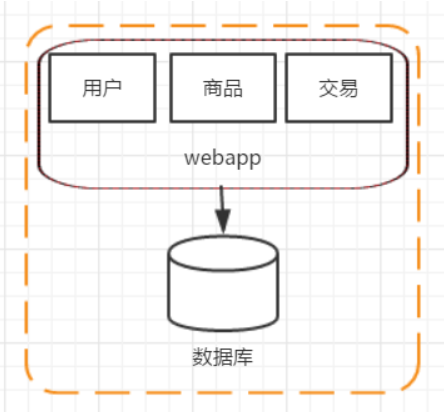
阶段一:单应用架构
在网站创建初期,经常把所有的东西都在一台机器上部署,这个时候的架构是单应用架构,优点是效率非常高
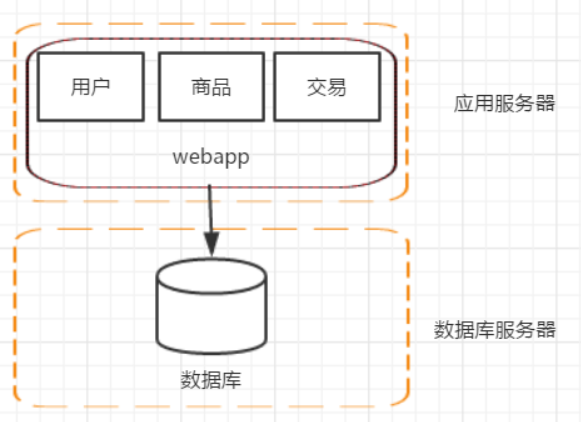
阶段二:应用服务器和数据库服务器分离
网站上线了,随着时间推移,访问量开始逐渐增大,服务器逐渐的就扛不住了,这个时候就要考虑加机器了,这就进入了第二阶段。这个阶段增加机器的主要目的是将web服务器和数据库服务器进行拆分,这样不仅提高了单机的负载能力,也提高了容灾能力
第三阶段:应用服务器集群
然而随着访问量的持续增加,单台服务器已经无法满足需求。假设数据库服务器的还未遇到性能问题
此时可以增加应用服务器,这就进入第三阶段——应用服务器集群。
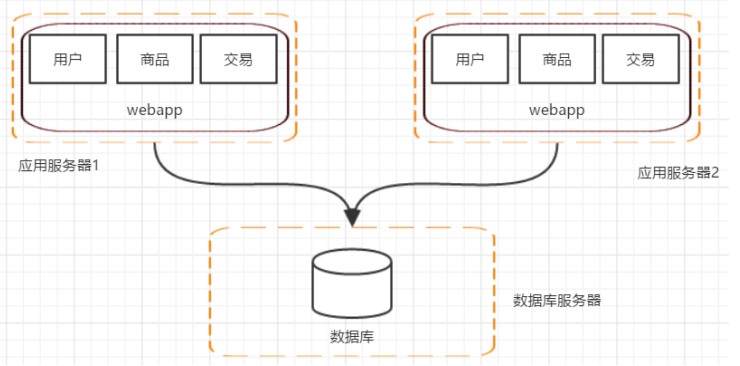
在这个阶段有些问题就逐渐显现出来了,比如:
(1)用户的请求该由哪一台机器进行处理? ——负载均衡(F5/apache/nginx)
(2)如果用户每次请求的机器不同,那么session如何维护?
1、session同步
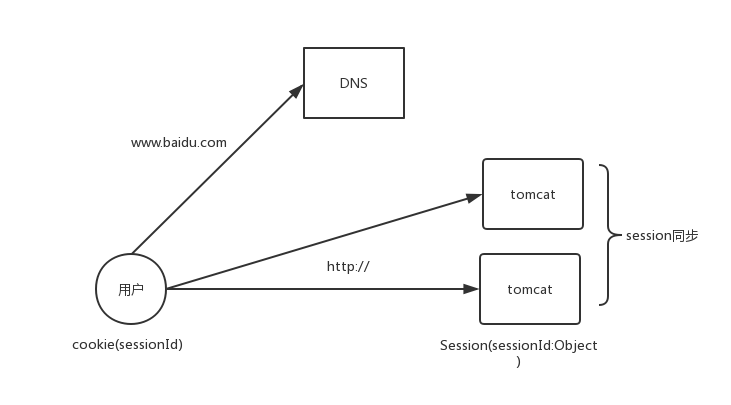
2、通过第三方存储(redis等)存储session
3、跳过容器对象
这样架构就变为了以下模式。
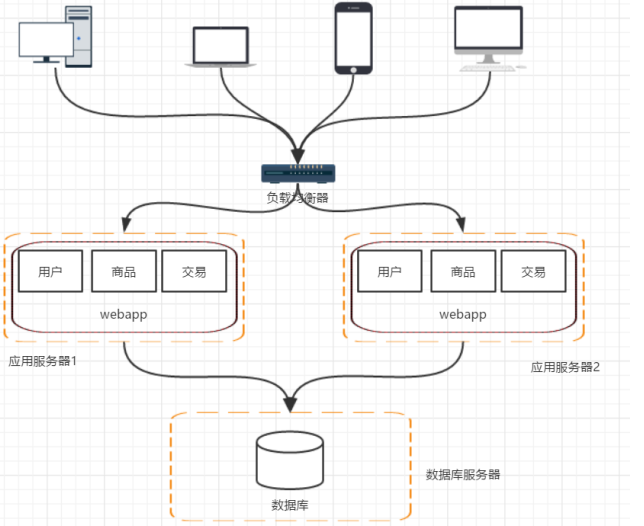
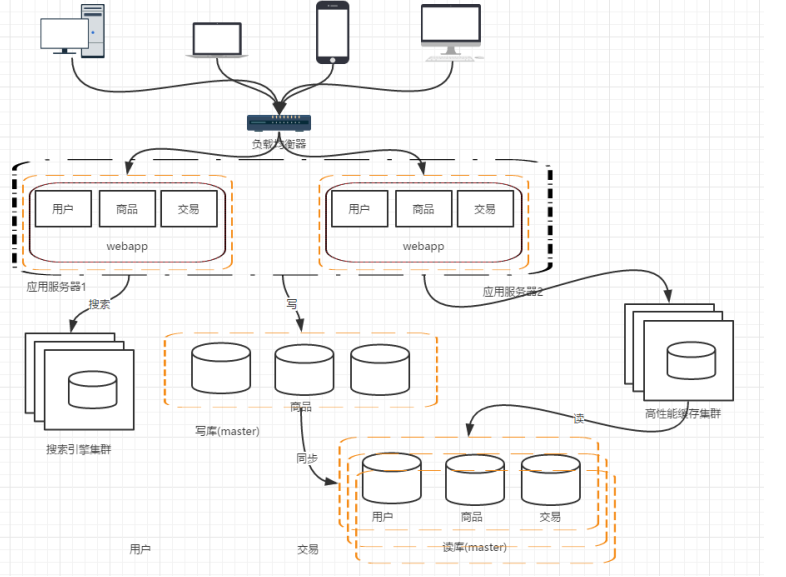
阶段四:数据库读写分离
随着业务量进一步增加,数据库服务器的I/O能力会存在瓶颈。
首先考虑的是加机器,但是如果直接一分为二,每次读写还要额外判断数据应该在哪台机器上。
基于电商系统数据库读多写少的特点,可以将一个服务器作为写库,另一个库设为读库,
并设置主从同步进行复制。
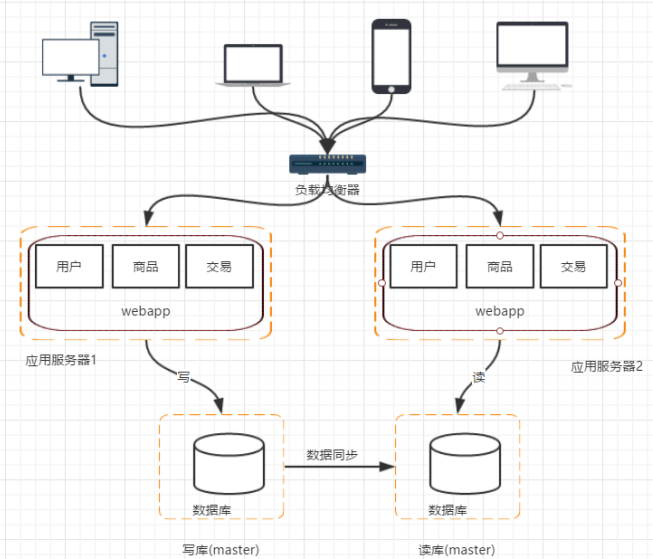
这样也会带来数据库不一致的问题,这个问题后期有时间会单独讨论。
实际上,如果读库的量远大于写库的访问量,需要设置多个读库时,可以采取以下的结构
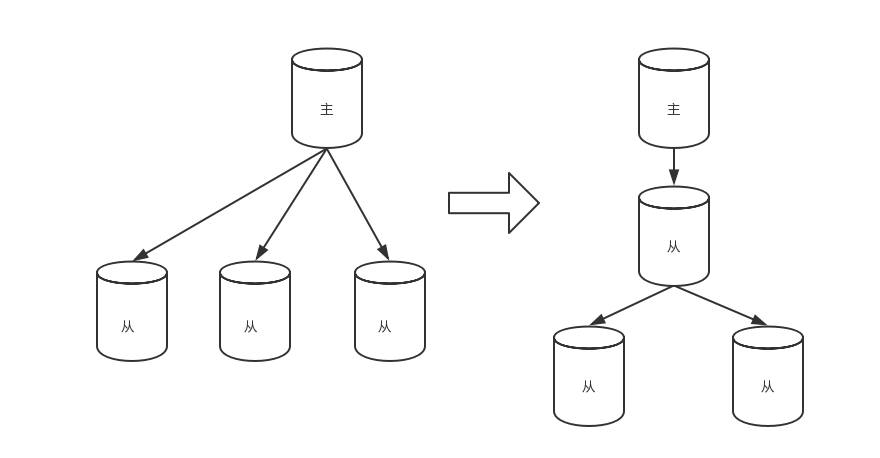
阶段五:引入缓存机制
对于热点数据,没必要每次都去数据库中读取,应该使用 redis、memcache等将这些数据缓存起来
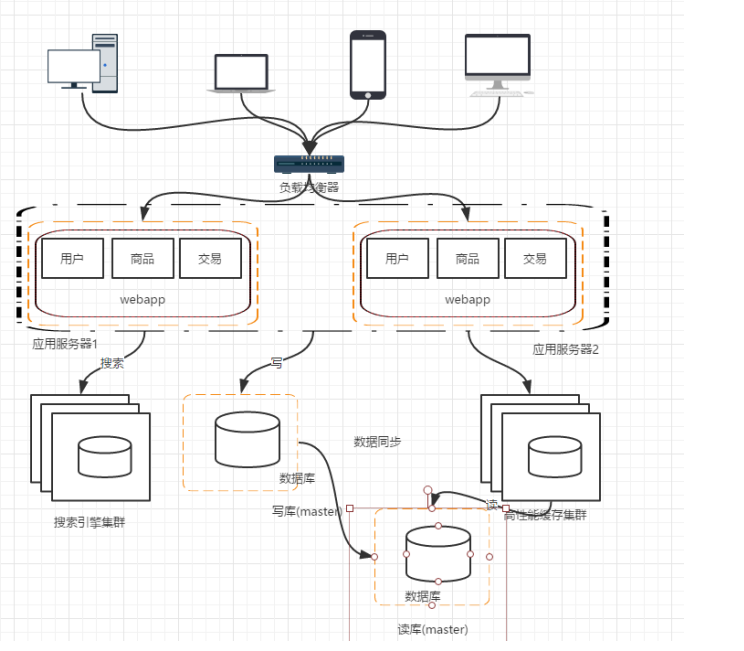
至此,分布式架构的基本框架已经形成。
阶段六:数据库的水平、垂直拆分
数据库永远是最容易造成瓶颈的地方之一,例如阿里巴巴09年“去IOE运动”就是为了解决数据库扩展性瓶颈问题。
在整个架构的编号过程中,所有的数据还是在同一个数据库中的,因此我们可以考虑对数据进行拆分
其中:
垂直拆分就是把不同业务的数据拆分到不同的数据库中
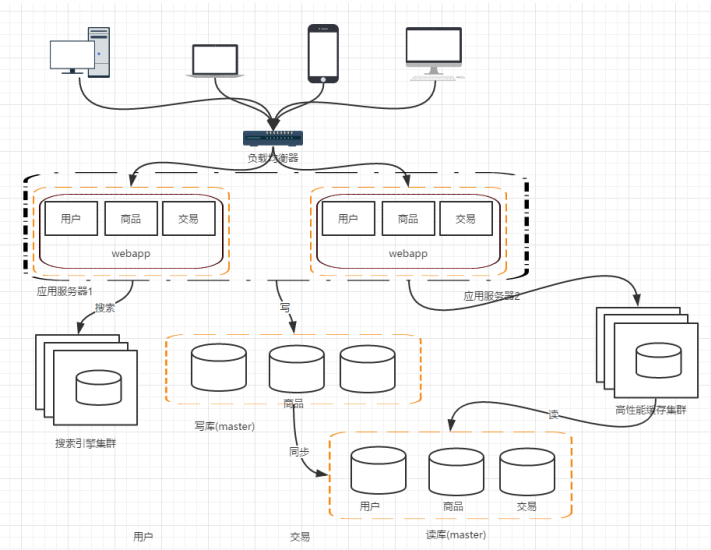
水平拆分则是把同一个表中的数据拆分到两个甚至更多的数据库中,有些公司的数据库是按照日期分为31*N个数据库
阶段七:应用拆分阶段
随着需求的不断提出,应用的体量也越来越大,因此需要按照领域对业务进行拆分
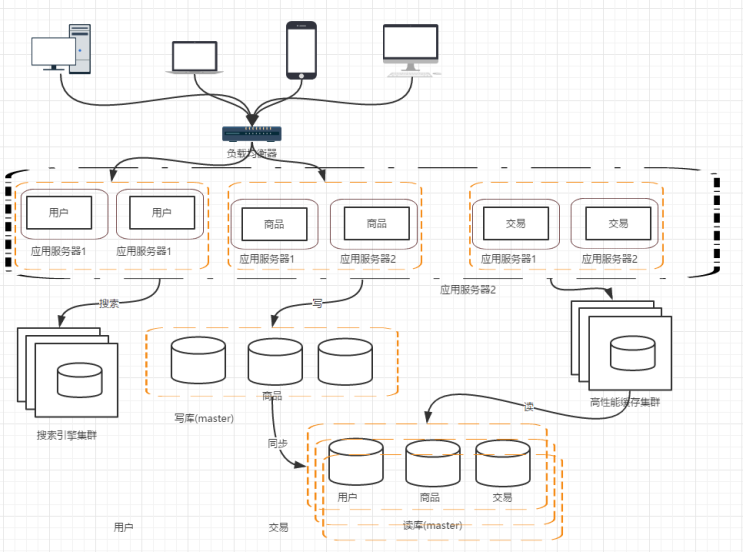
至此,完整的分布式架构演进过程结束
tips:分布式架构和微服务架构
分布式:
-
- 不同模块部署在不同服务器上
- 作用:分布式解决网站高并发带来问题
而微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成。系统中的各个微服务可被独立部署,各个微服务之间是松耦合的。每个微服务仅关注于完成一件任务并很好地完成该任务。在所有情况下,每个任务代表着一个小的业务能力。
微服务是可以部署在一台服务器上的。
如果有兴趣,可以加群一起学习。















 2073
2073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









