







独热编码官方合作微信:gldz_super
本专栏《AI计算机视觉进阶项目》主要以计算机视觉实战项目为主,第一个项目为口罩检测:该项目将分为几个模块进行展示。本项目已完成链接:
1.AI计算机视觉进阶项目(一)——带口罩识别检测(1)_AI炮灰的博客-CSDN博客
2.AI计算机视觉进阶项目(一)——带口罩识别检测(2)_AI炮灰的博客-CSDN博客
一、本节任务
- 对带口罩识别检测(2)中生成的npz文件数据进行读取
- one_hot独热编码
- 分为train和test数据
- 搭建CNN模型
- 训练模型
- 保存模型
二、任务实现
2.1模块导入
# 模块导入
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.python.keras import layers, Sequential
import pandas as pd
import matplotlib.pyplot as plt
2.2 数据读取
# 1.读取NPZ文件
arr = np.load('./imageData.npz')
img_list = arr['arr_0']
label_list = arr['arr_1']
print(img_list.shape, label_list.shape) # (5320, 100, 100, 3) (5320,)
2.3独热编码
# 2.one_hot独热编码:将label的类别变为二进制独热编码格式这样类别直接的距离更加合理
print(np.unique(label_list)) # 查看所有的类别
# 实例化
onehot = OneHotEncoder()
# 编码:并把标签label_list由一维变为二维
y_onehot = onehot.fit_transform(label_list.reshape(-1, 1)) # label_list由(5320,1)变为(5320, 3)
print(y_onehot.shape)
# 将y_onehot变为矩阵
y_onehot_arr = y_onehot.toarray()
print(y_onehot_arr)2.4数据集划分
# 3.分为train和test数据
x_train, x_test, y_train, y_test = train_test_split(img_list, y_onehot_arr, test_size=0.2, random_state=42)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)2.5模型搭建
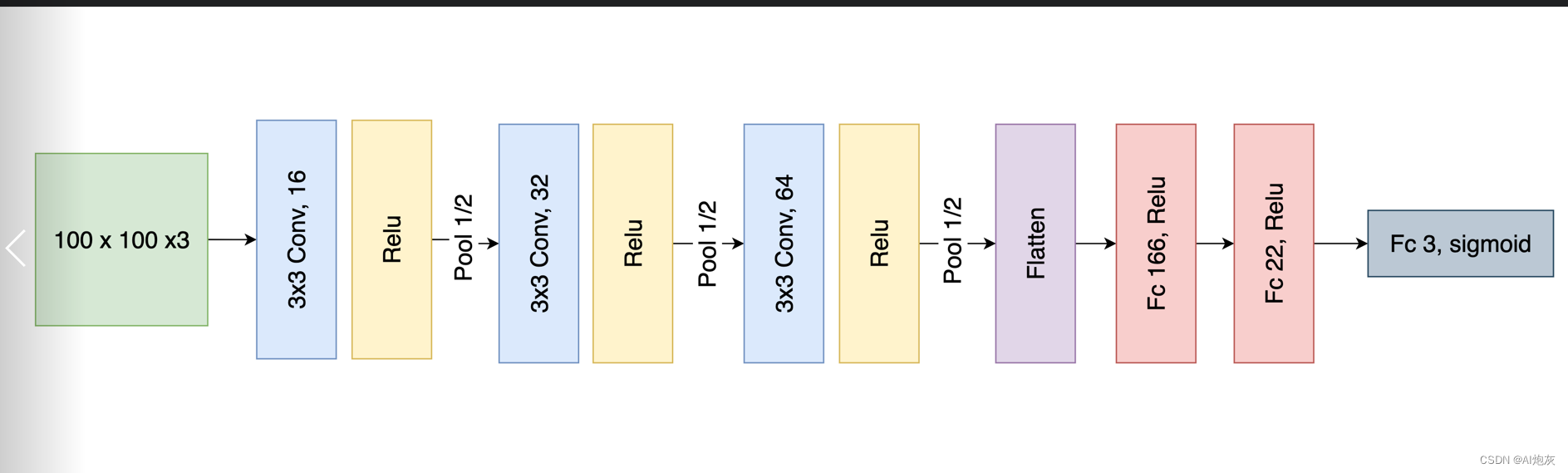
# 4.搭建模型
model = Sequential([
layers.Conv2D(16, 3, padding='same', input_shape=(100, 100, 3), activation='relu'),
layers.MaxPool2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPool2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPool2D(),
layers.Flatten(),
layers.Dense(166, activation='relu'),
layers.Dense(22, activation='relu'),
layers.Dense(3, activation='sigmoid')
])
# 编译模型
model.compile(
# optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
# loss=tf.keras.losses.categorical_crossentroy,
# metrics=['accurate']
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
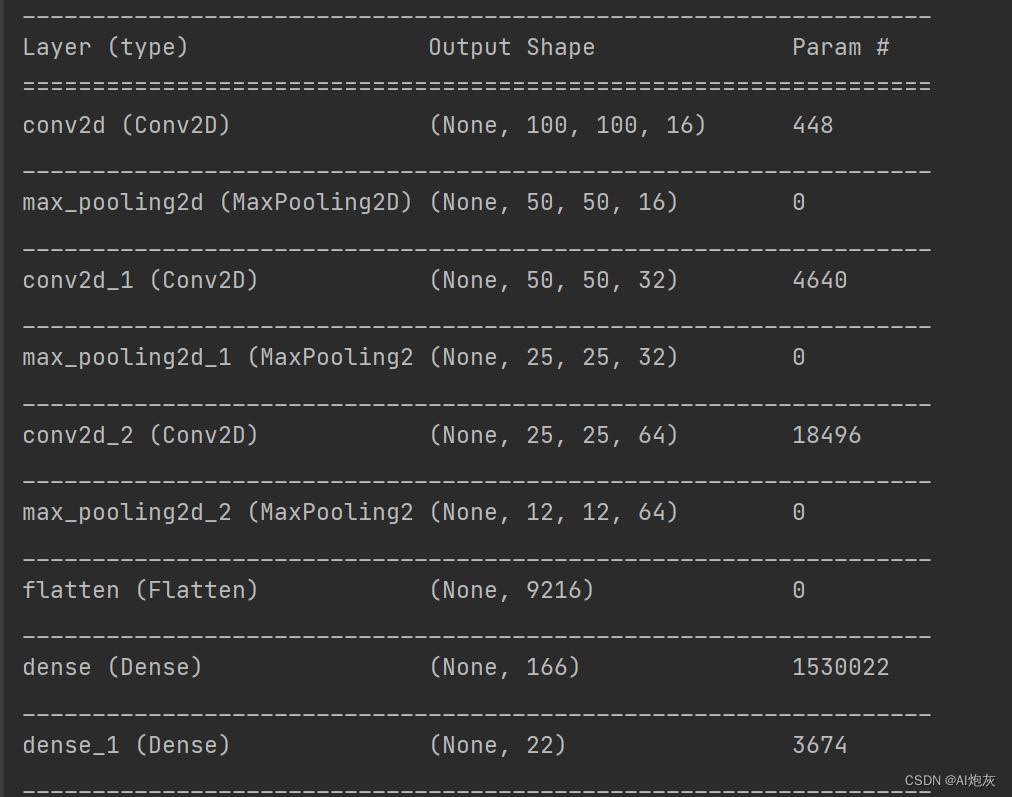
# 预览模型
model.summary()
2.6查看模型训练效果
# 5.训练模型
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test),
batch_size=30,
epochs=10
)
# 查看训练效果
history_pd = pd.DataFrame(history.history)
print(history_pd)
2.7 画出损失和精确度
# 查看损失
plt.plot(history_pd['loss'])
plt.plot(history_pd['val_loss'])
plt.title('Model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train_set', 'test_set'], loc='upper right')
plt.show()
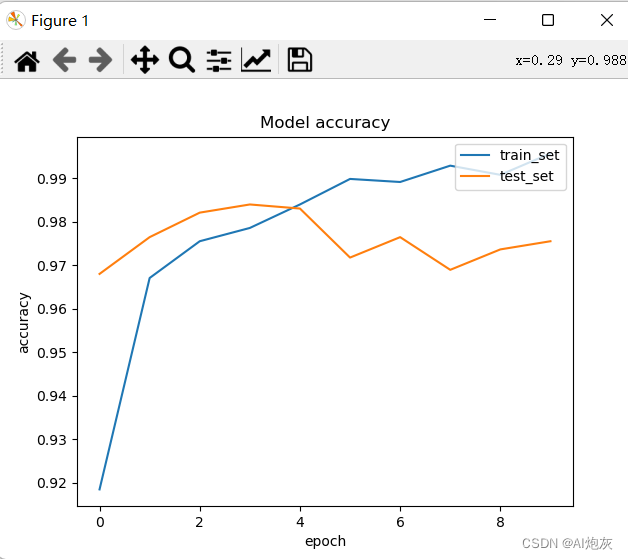
# 查看准确率
# 查看损失
plt.plot(history_pd['accuracy'])
plt.plot(history_pd['val_accuracy'])
plt.title('Model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train_set', 'test_set'], loc='upper right')
plt.show()

2.8保存模型
# 6.保存模型:为了防止每次使用都需进行训练
model.save('./face_mask_model.h5')
保存模型后后面使用就不需要每次进行训练,直接可以使用保存后得模型
三、完整代码
"""
流程:
1.读取NPZ文件
2.one_hot独热编码
3.分为train和test数据
4.搭建CNN模型
5.训练模型
6.保存模型
"""
# 模块导入
import numpy as np
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from tensorflow.python.keras import layers, Sequential
import pandas as pd
import matplotlib.pyplot as plt
# 1.读取NPZ文件
arr = np.load('./imageData.npz')
img_list = arr['arr_0']
label_list = arr['arr_1']
print(img_list.shape, label_list.shape) # (5320, 100, 100, 3) (5320,)
# 2.one_hot独热编码:将label的类别变为二进制独热编码格式这样类别直接的距离更加合理
print(np.unique(label_list)) # 查看所有的类别
# 实例化
onehot = OneHotEncoder()
# 编码:并把标签label_list由一维变为二维
y_onehot = onehot.fit_transform(label_list.reshape(-1, 1)) # label_list由(5320,1)变为(5320, 3)
print(y_onehot.shape)
# 将y_onehot变为矩阵
y_onehot_arr = y_onehot.toarray()
print(y_onehot_arr)
# 3.分为train和test数据
x_train, x_test, y_train, y_test = train_test_split(img_list, y_onehot_arr, test_size=0.2, random_state=42)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
# 4.搭建模型
model = Sequential([
layers.Conv2D(16, 3, padding='same', input_shape=(100, 100, 3), activation='relu'),
layers.MaxPool2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPool2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPool2D(),
layers.Flatten(),
layers.Dense(166, activation='relu'),
layers.Dense(22, activation='relu'),
layers.Dense(3, activation='sigmoid')
])
# 编译模型
model.compile(
# optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
# loss=tf.keras.losses.categorical_crossentroy,
# metrics=['accurate']
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 预览模型
model.summary()
# 5.训练模型
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test),
batch_size=30,
epochs=10
)
# 查看训练效果
history_pd = pd.DataFrame(history.history)
print(history_pd)
# 查看损失
plt.plot(history_pd['loss'])
plt.plot(history_pd['val_loss'])
plt.title('Model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train_set', 'test_set'], loc='upper right')
plt.show()
# 查看准确率
# 查看损失
plt.plot(history_pd['accuracy'])
plt.plot(history_pd['val_accuracy'])
plt.title('Model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(['train_set', 'test_set'], loc='upper right')
plt.show()
# 6.保存模型:为了防止每次使用都需进行训练
model.save('./face_mask_model.h5')















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











