







缓存算法
缓存算法是一种淘汰算法,用于决定缓存系统中哪些数据应该被删去。
常见算法类型包括LFU、LRU、ARC、FIFO、
LFU(Least Frequently Used ,最少使用算法):
这个缓存算法使用一个计数器来记录条目被访问的频率。通过使用LFU缓存算法,最低访问数的条目首先被移除。这个方法并不经常使用,因为它无法对一个拥有最初高访问率之后长时间没有被访问的条目缓存负责。
LRU (Least recently used,最近最少使用算法)
是一种常用的淘汰算法,选择最近最久未使用的数据予以淘汰。
FIFO(先进先出算法)
ARC(Adjustable Replacement Cache,适应性缓存算法)
是在LRU和LFU的基础上支持适应性调整的优化算法。
bigcache源码分析:
配置项
// Config for BigCache
type Config struct {
// Shards 分片数量,必须是2得次方
Shards int
// LifeWindow 过期时间
LifeWindow time.Duration
// CleanWindow 定时扫描间隔时间
CleanWindow time.Duration
// MaxEntriesInWindow 允许存在得最大缓存数量,用于初始化分片大小
MaxEntriesInWindow int
// MaxEntrySize 单个缓存得最大长度限制,用于初始化分片大小
MaxEntrySize int
// StatsEnabled 是否计算缓存资源被请求的次数
StatsEnabled bool
// Verbose 是否打印相关日志
Verbose bool
// Hasher 将字符串转化为int64,默认使用fnv64
Hasher Hasher
// HardMaxCacheSize 内存限制大小(MB)
HardMaxCacheSize int
// OnRemove 删除最老元素得回调函数,优先级第二
OnRemove func(key string, entry []byte)
// OnRemoveWithMetadata 删除最老元素得回调函数,优先级最高
OnRemoveWithMetadata func(key string, entry []byte, keyMetadata Metadata)
// OnRemoveWithReason 删除最老元素得回调函数,优先级第三
OnRemoveWithReason func(key string, entry []byte, reason RemoveReason)
onRemoveFilter int
// Logger 当Verbose为true时启用得log日志
Logger Logger
}
关于容量配置参数:MaxEntriesInWindow,MaxEntrySize,HardMaxCacheSize三者关系:
单个shard的最大容量m:HardMaxCacheSize/Shards
初始化的容量:MaxEntriesInWindow/Shards * MaxEntrySize
当添加元素d现有容量q不足时,会按照如下扩容:
q=(q+d)*2进行扩容,达到最大容量时不可再扩.
简单的缓存
Go map 与 sync.Mutex的结合使用就可以实现一个简单的缓存。
Go map 结合 sync.Mutex 是应对缓存的常见形式。
虽然实现简单,但这也会产生如下问题:
1.map并不是并非安全的,即使加入sync.RWMutex锁虽然对读写进行了优化,但是对于并发的写入,最终还是把写变成了串行,一旦写的并发量大的时候,即使写不同的 key, 对应的 goroutine 也会 block 住, 产生严重的锁竞争问题。
2.对于 Go 语言中的 map, 垃圾回收器在 mark 和 scan 阶段检查 map 中的每一个元素, 如果缓存中包含数百万的缓存对象,垃圾回收器对这些对象的无意义的检查导致不必要的内存扫描开销。
3.不能对内存的使用量做限制。
分片
上面提到的锁竞争,是一个瓶颈,并且不可控的。
bigcache使用 shard (分片)解决锁竞争的问题,每个分片一把锁。很多大并发场景下为了减小并发的压力都会采用这种方法,有许多这样的场景比如数据库的分片。
对于每一个缓存对象,根据它的 key 计算它的哈希值: hash(key) % N, N是分片数量。理想情况下 N 个 goroutine 每次请求正好平均落在各自的分片上,这样就不会有竞争了,即使有多个 goroutine 落在同一个分片上,如果 hash 比较平均的话,单个 shard 的压力也会比较小。
竞争小了之后,延迟可以大大提高,因为等待获取锁的时间变小了
bigcache中分片数量N 是 2 的幂, 默认配置为1024。这样设计的好处就是计算余数可以使用位运算快速计算。
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {
return c.shards[hashedKey&c.shardMask]
}
因为对于 2 的幂 N,对于任意的x, 下面的公式成立:
x mod N = (x & (N-1)) // 只需要使用一次按位 AND (&)就可以求得它的余数
忽略内存开销
针对gc对于map的内存扫描开销问题,bigcache 提供了一个默认的 Hash 的实现,采用 fnv64a 算法。这个算法的好处是采用位运算的方式在栈上进行运算,避免在堆上分配。
// Sum64 gets the string and returns its uint64 hash value.
func (f fnv64a) Sum64(key string) uint64 {
var hash uint64 = offset64
for i := 0; i < len(key); i++ {
hash ^= uint64(key[i])
hash *= prime64
}
return hash
}
如果 map 对象中的 key 和 value 不包含指针,那么垃圾回收器就会对它们进行优化:
如果把 map 定义成 map[int]int,就会发现 gc 的耗时就会降下来了。
但是我们没办法要求用户的缓存对象只能包含int、bool这样的基本数据类型。
解决办法就是使用哈希值作为map[int]int的 key。把缓存对象序列化后放到一个预先分配的大的字节数组中,然后将它在数组中的 offset 作为map[int]int的 value。
所以bigcache的对象不包含指针,虽然也是分配在堆上,但是垃圾回收可以无视它们。
添加缓存项过程
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {
currentTimestamp := uint64(s.clock.Epoch())
s.lock.Lock()
// 查找是否已经存在了对应的缓存对象,如果存在,将它的值置为空
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry)
}
}
// 触发是否要移除最老的缓存对象
if oldestEntry, err := s.entries.Peek(); err == nil {
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)
}
// 将对象放入到一个字节数组中,如果已有的字节数组(slice)可以放得下此对象,则重用,否则新建一个字节数组
w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)
for {
// 尝试放入到字节队列中,成功则加入到map中
if index, err := s.entries.Push(w); err == nil {
s.hashmap[hashedKey] = uint32(index)
s.lock.Unlock()
return nil
}
// 如果空间不足,移除最老的元素
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
}
}
在添加元素过程中会加锁,保证并发安全,在添加一个元素失败后,会清理空间删除最老的元素。
每个map的key都是一个uint32的 hash值,每个值对应一个存储着元数据的ring buffer。如果hash值碰撞了,BigCache会忽略旧key,然后把新的值存储到map中。
// Push copies entry at the end of queue and moves tail pointer. Allocates more space if needed.
// Returns index for pushed data or error if maximum size queue limit is reached.
func (q *BytesQueue) Push(data []byte) (int, error) {
dataLen := uint64(len(data))
// 获取一个固定得size
headerEntrySize := getUvarintSize(uint32(dataLen))
// 判断是否可以append到tail后面
if !q.canInsertAfterTail(dataLen + headerEntrySize) {
// 判断是否可以放到head前
if q.canInsertBeforeHead(dataLen + headerEntrySize) {
q.tail = leftMarginIndex
} else if q.capacity+headerEntrySize+dataLen >= q.maxCapacity && q.maxCapacity > 0 {
// 如果要插入得值超过shard最大内存限制,直接报错返回
return -1, &queueError{"Full queue. Maximum size limit reached."}
} else {
// 否则对BytesQueue进行扩容
q.allocateAdditionalMemory(dataLen + headerEntrySize)
}
}
index := q.tail
// 将数据copy到BytesQueue
q.push(data, dataLen)
return int(index), nil
}
BytesQueue 是一个字节数组,可以做到按需分配。当加入一个[]byte时,它会通过Push方法把数据 copy 到尾部。
获取缓存项过程
func (s *cacheShard) get(key string, hashedKey uint64) ([]byte, error) {
s.lock.RLock()
// 获取key对应的value
wrappedEntry, err := s.getWrappedEntry(hashedKey)
if err != nil {
s.lock.RUnlock()
return nil, err
}
// 通过获取的value反取key,不一致则产生了hash碰撞
if entryKey := readKeyFromEntry(wrappedEntry); key != entryKey {
s.lock.RUnlock()
s.collision()
if s.isVerbose {
s.logger.Printf("Collision detected. Both %q and %q have the same hash %x", key, entryKey, hashedKey)
}
return nil, ErrEntryNotFound
}
entry := readEntry(wrappedEntry)
s.lock.RUnlock()
// 记录获取key的成功次数和总次数
s.hit(hashedKey)
return entry, nil
}
获取数据前,会对请求key进行hash产生新的hashkey。获取数据结果后,会拿到value对应得value_key,与请求得key进行对比,若是相同则表明不同得key却产生了相同得hashkey,也就是产生了hash碰撞; 若没有发生hash碰撞则会进行请求记录,正常返回。
删除缓存项过程
func (s *cacheShard) del(hashedKey uint64) error {
// 添加读锁预检查
s.lock.RLock()
{
itemIndex := s.hashmap[hashedKey]
if itemIndex == 0 {
// 无value的情况删除失败
s.lock.RUnlock()
s.delmiss()
return ErrEntryNotFound
}
if err := s.entries.CheckGet(int(itemIndex)); err != nil {
// 查找value失败的情况
s.lock.RUnlock()
s.delmiss()
return err
}
}
s.lock.RUnlock()
// 添加写锁
s.lock.Lock()
{
// 此时还需要再查一次
itemIndex := s.hashmap[hashedKey]
if itemIndex == 0 {
s.lock.Unlock()
s.delmiss()
return ErrEntryNotFound
}
wrappedEntry, err := s.entries.Get(int(itemIndex))
if err != nil {
s.lock.Unlock()
s.delmiss()
return err
}
// 查询成功后删除
delete(s.hashmap, hashedKey)
s.onRemove(wrappedEntry, Deleted)
if s.statsEnabled {
delete(s.hashmapStats, hashedKey)
}
// 把data中key的长度置为0
resetKeyFromEntry(wrappedEntry)
}
s.lock.Unlock()
s.delhit()
return nil
}
需要注意的是删除缓存元素的时候 bigcache 只是把它的索引从map[uint64]uint32中删除了,并把它在queue.BytesQueue队列中的长度置为 0。那么删除操作会不会在queue.BytesQueue中造成很多的“虫洞”?从它的实现上来看,会, 而且这些"虫洞"不会被整理,也不会被移除。因为它的底层是使用一个字节数组实现的,"虫洞"的移除是一个耗时的操作,会导致锁的持有时间过长。
bigcache 只能等待清理最老的元素的时候把这些"虫洞"删除掉。
缓存数据统计
// Stats stores cache statistics
type Stats struct {
// Hits is a number of successfully found keys
Hits int64 `json:"hits"`
// Misses is a number of not found keys
Misses int64 `json:"misses"`
// DelHits is a number of successfully deleted keys
DelHits int64 `json:"delete_hits"`
// DelMisses is a number of not deleted keys
DelMisses int64 `json:"delete_misses"`
// Collisions is a number of happened key-collisions
Collisions int64 `json:"collisions"`
}
// Stats returns cache's statistics
func (c *BigCache) Stats() Stats {
var s Stats
for _, shard := range c.shards {
tmp := shard.getStats()
s.Hits += tmp.Hits
s.Misses += tmp.Misses
s.DelHits += tmp.DelHits
s.DelMisses += tmp.DelMisses
s.Collisions += tmp.Collisions
}
return s
}
Stats()方法可以获取到bigcache使用过程中记录的缓存命中和缓存失败等的汇总信息。
缓存淘汰时机
1.过期淘汰
会专门有一个定时(CleanWindow的时间)的清理 goroutine, 负责移除过期数据。
// bigcache在init之后便开始执行定时清理
if config.CleanWindow > 0 {
go func() {
ticker := time.NewTicker(config.CleanWindow)
defer ticker.Stop()
for {
select {
case t := <-ticker.C:
cache.cleanUp(uint64(t.Unix()))
case <-cache.close:
return
}
}
}()
}
2.增加一个元素前,会检查最老的元素要不要删除
if oldestEntry, err := s.entries.Peek(); err == nil {
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry)
}
// 检查最老的元素是否需要删除
func (s *cacheShard) onEvict(oldestEntry []byte, currentTimestamp uint64, evict func(reason RemoveReason) error) bool {
// 读取存储的时间戳
oldestTimestamp := readTimestampFromEntry(oldestEntry)
// 判断是否需要删除
if currentTimestamp-oldestTimestamp > s.lifeWindow {
evict(Expired)
return true
}
return false
}
3.内存不足淘汰
在添加一个元素因为内存不足失败时会淘汰最早的元素
// 如果空间不足,移除最老的元素
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
4.重复key覆盖
添加元素前会检查是已经有该元素,有的话把旧元素置为0,再append新的元素
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry)
}
}
同其他缓存对比
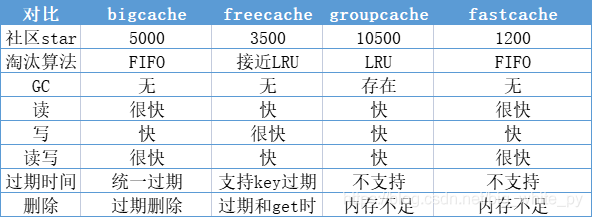
FreeCache
FreeCache 将缓存分成了256段,每段包括256个槽和一个ring buffer存储数据。当一个新的元素被添加进来的时候,使用hash值下8位作为标识id,通过使用LSB 9-16的值作为槽ID。将数据分配到多个槽里面,有助于优化查询的时间(分治策略)。
数据被存储在ring buffer中,位置被保存在一个排序的数组里面。如果ring buffer 内存不足,则会利用LRU的策略在ring buffer逐个扫描,如果缓存的最后访问时间小于平均访问的时间,就会被删掉。要找到一个缓存内容,在槽中是通过二分查找法对一个已经排好的数据进行查询。
GroupCache
groupcache是使用golang开发的一个缓存系统,可以作为memcache的替代品存在。不过两者也是有不同的,groupcache既是客户端也是服务器,也就是说它是作为一个库存在的,跟业务代码共生。
GroupCache使用链表和Map实现了一个精准的LRU删除策略的缓存。采用了一致性hash算法平衡节点之间的数据同步。
fastcache
fasthttp 的作者采用类似 bigcache 的思想实现了fastcache,他使用 chunks替换 queue.BytesQueue,chunk 是一个 ring buffer, 每个 chunk 64KB。删除还是一样,只是从 map 中删除,不会从chunks中删除。
fastcache 没有过期的概念,所以缓存对象不会被过期剔除。
也正因如此fastcache在读写速度上要比bigcache更加出色。
总结
总体来看,在内存淘汰上可能不如freecache灵活,在数据同步上不如groupcache方便,在读写上的性能不如fastcache,但是bigcache在综合表现上还是不错的。Go中并没有一个能满足所有场景的智能缓存框架,我们选择缓存还是要根据具体的场景进行适当的取舍。














 6935
6935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









