









缓存穿透
缓存穿透是指请求了缓存和数据库中都没有的数据,频繁请求这类数据,那么数据库就要频繁响应这种不必要的查询,会导致数据库压力过大。
那么如何将这些请求阻挡在外呢?
主要有两个思路:
1.从缓存和数据库中都取不到得数据,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如两分钟
2.使用过滤器
布隆过滤器
布隆过滤器(Bloom Filter)大概的思路就是,当你请求的信息来的时候,先检查一下你查询的数据我这有没有,有的话将请求压给数据库,没有的话直接返回,是如何做到的呢?
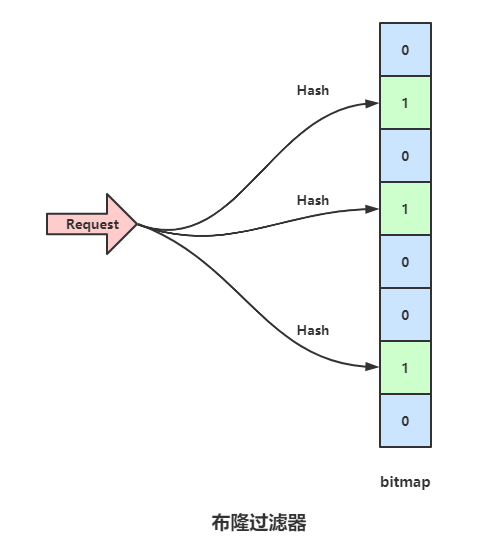
如图,一个bitmap用于记录,bitmap原始数值全都是0,当一个数据存进来的时候,用三个Hash函数分别计算三次Hash值,并且将bitmap对应的位置设置为1,上图中,bitmap 的1,3,6位置被标记为1,这时候如果一个数据请求过来,依然用之前的三个Hash函数计算Hash值,如果是同一个数据的话,势必依旧是映射到1,3,6位,那么就可以判断这个数据之前存储过,如果新的数据映射的三个位置,有一个匹配不上,假如映射到1,3,7位,由于7位是0,也就是这个数据之前并没有加入进数据库,所以直接返回。
布隆过滤器的问题
上面这种方式的布隆过滤器存在一些问题:
- 布隆过滤器可能误判:
假如有一个情景,放入数据包1时,将bitmap的1,3,6位设置为了1,放入数据包2时将bitmap的3,6,7位设置为了1,此时一个并没有存过的数据包请求3,做三次哈希之后,对应的bitmap位点分别是1,6,7,这个数据之前并没有存进去过,但是由于数据包1和2存入时将对应的点设置为了1,所以请求3也会压倒数据库上,这种情况,会随着存入的数据增加而增加。
- 布隆过滤器没法删除数据:
当你删除某一个数据包对应位图上的标志后,可能影响其他的数据包,例如上面例子中,如果删除数据包1,也就意味着会将bitmap1,3,6位设置为0,此时数据包2来请求时,会显示不存在,因为3,6两位已经被设置为0。
布谷鸟哈希
布谷鸟算法的启发当然来自于布谷鸟,因为布谷鸟这种鸟很有意思,生出来的孩子自己不养,直接被扔到其他鸟的鸟巢中去了,但有时候,这些布谷鸟蛋会被被寄宿的那些鸟妈妈发现,然后就被抛弃,有时候,这些宿主会直接放弃整个鸟巢寻找新住处。然而道高一尺魔高一丈,有些品种的布谷鸟生下来的布谷鸟蛋的颜色能和去寄宿的鸟的鸟蛋颜色很相似,并且布谷鸟的破壳时间往往比那些宿主的鸟蛋早,这样,一旦小布谷鸟破壳,它就会将一些鸟蛋扔出鸟巢去以求获得更多的食物,并且,小布谷鸟能模拟宿主鸟孩子的叫声来骗取更多的食物!简单来说,就是如何更高效地去骗吃骗喝。
最简单的布谷鸟哈希结构是一维数组结构,会有两个 hash 算法将新来的元素映射到数组的两个位置。如果两个位置中有一个位置为空,那么就可以将元素直接放进去。但是如果这两个位置都满了,它就不得不「鸠占鹊巢」,随机踢走一个,然后自己霸占了这个位置。
- 新来的元素a经过hash会落在(A2,B1)的位置,由于A2还没有元素,a直接落入A2

- 新插入元素b的hash会落在(A2,B3),由于A2已经被a占了,所以b会落在b3
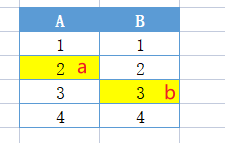
- 此时信来元素c的hash为(A2,B3), 由于两个位置都已经被占,它会随机将一个元素挤走,这里挤走了a
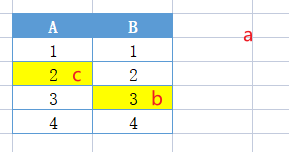
- a会重新进行hash,找到还未被占的B1位置
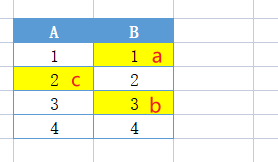
从上面可以看出,布谷鸟哈希算法会帮这些受害者(被挤走的蛋)寻找其它的窝。因为每一个元素都可以放在两个位置,只要任意一个有空位置,就可以塞进去。所以这个伤心的被挤走的蛋会看看自己的另一个位置有没有空,如果空了,自己挪过去也就皆大欢喜了。但是如果这个位置也被别人占了呢?好,那么它会再来一次「鸠占鹊巢」,将受害者的角色转嫁给别人。然后这个新的受害者还会重复这个过程直到所有的蛋都找到了自己的巢为止。
布谷鸟哈希的问题
但是会遇到一个问题,那就是如果数组太拥挤了,连续踢来踢去几百次还没有停下来,这时候会严重影响插入效率。这时候布谷鸟哈希会设置一个阈值,当连续占巢行为超出了某个阈值,就认为这个数组已经几乎满了。这时候就需要对它进行扩容,重新放置所有元素。
还会有另一个问题,那就是可能会存在挤兑循环。比如两个不同的元素,hash 之后的两个位置正好相同,这时候它们一人一个位置没有问题。但是这时候来了第三个元素,它 hash 之后的位置也和它们一样,很明显,这时候会出现挤兑的循环。不过让三个不同的元素经过两次 hash 后位置还一样,这样的概率并不是很高,除非你的 hash 算法太挫了。
布谷鸟哈希算法对待这种挤兑循环的态度就是认为数组太拥挤了,需要扩容。
布谷鸟过滤器
布谷鸟过滤器和布谷鸟哈希结构一样,它也是一维数组,但是不同于布谷鸟哈希的是,布谷鸟哈希会存储整个元素,而布谷鸟过滤器中只会存储元素的指纹信息(几个bit,类似于布隆过滤器)。这里过滤器牺牲了数据的精确性换取了空间效率。正是因为存储的是元素的指纹信息,所以会存在误判率,这点和布隆过滤器如出一辙。
首先布谷鸟过滤器还是只会选用两个 hash 函数,但是每个位置可以放置多个座位。这两个 hash 函数选择的比较特殊,因为过滤器中只能存储指纹信息。当这个位置上的指纹被挤兑之后,它需要计算出另一个对偶位置。而计算这个对偶位置是需要元素本身的,我们来回忆一下前面的哈希位置计算公式。
fp = fingerprint(x)
p1 = hash1(x) % l
p2 = hash2(x) % l
我们知道了 p1 和 x 的指纹,是没办法直接计算出 p2 的。
特殊的 hash 函数
布谷鸟过滤器巧妙的地方就在于设计了一个独特的 hash 函数,使得可以根据 p1 和 元素指纹 直接计算出 p2,而不需要完整的 x 元素。
fp = fingerprint(x)
p1 = hash(x)
p2 = p1 ^ hash(fp) // 异或
从上面的公式中可以看出,当我们知道 fp 和 p1,就可以直接算出 p2。同样如果我们知道 p2 和 fp,也可以直接算出 p1 —— 对偶性。
p1 = p2 ^ hash(fp)
所以我们根本不需要知道当前的位置是 p1 还是 p2,只需要将当前的位置和 hash(fp) 进行异或计算就可以得到对偶位置。而且只需要确保 hash(fp) != 0 就可以确保 p1 != p2,如此就不会出现自己踢自己导致死循环的问题。
也许你会问为什么这里的 hash 函数不需要对数组的长度取模呢?实际上是需要的,但是布谷鸟过滤器强制数组的长度必须是 2 的指数,所以对数组的长度取模等价于取 hash 值的最后 n 位。在进行异或运算时,忽略掉低 n 位 之外的其它位就行。将计算出来的位置 p 保留低 n 位就是最终的对偶位置。
源码分析
Cuckoo 过滤器是近似集合成员查询的布隆过滤器替代品。虽然布隆过滤器是众所周知的节省空间的数据结构,用于提供诸如“如果项目 x 在一个集合中?”之类的查询,但它们不支持删除。它们启用删除的差异(如计算布隆过滤器)通常需要更多的空间。
Cuckoo 过滤器提供了动态添加和删除项目的灵活性。布谷鸟过滤器基于布谷鸟散列(因此命名为布谷鸟过滤器)。它本质上是一个存储每个密钥指纹的布谷鸟哈希表。Cuckoo 哈希表可以非常紧凑,因此对于需要低误报率 (< 3%) 的应用程序,布谷鸟过滤器可以使用比传统布隆过滤器更少的空间。
// Filter is a probabilistic counter
type Filter struct {
// bucket为长度为4的byte数组
buckets []bucket
// 记录过滤器中的元素个数
count uint
// bucket的个数=2^bucketPow
bucketPow uint
}
// NewFilter returns a new cuckoofilter with a given capacity.
// A capacity of 1000000 is a normal default, which allocates
// about ~1MB on 64-bit machines.
func NewFilter(capacity uint) *Filter {
capacity = getNextPow2(uint64(capacity)) / bucketSize
if capacity == 0 {
capacity = 1
}
buckets := make([]bucket, capacity)
return &Filter{
buckets: buckets,
count: 0,
bucketPow: uint(bits.TrailingZeros(capacity)),
}
}
bucket是桶,每个桶上面有四个位置,这是为了避免出现hash后的位置一致而导致的循环挤兑的情况。这样即使两个元素被 hash 在了同一个位置,也不必立即「鸠占鹊巢」,因为这里有4个座位,你可以随意坐一个。除非这多个座位都被占了,才需要进行挤兑。很明显这也会显著降低挤兑次数,同一个位置上的多个座位在内存空间上是连续的,可以有效利用 CPU 高速缓存。
NewFilter用于初始化一个给定容量的过滤器Filter,这个容量数为2的n次方,如果不为2的n次方,内部会通过getNextPow2将其转化为2的n次方。
// Lookup returns true if data is in the counter
func (cf *Filter) Lookup(data []byte) bool {
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
if cf.buckets[i1].getFingerprintIndex(fp) > -1 {
return true
}
i2 := getAltIndex(fp, i1, cf.bucketPow)
return cf.buckets[i2].getFingerprintIndex(fp) > -1
}
布谷鸟过滤器中有两个hash函数进行位置的索引,Lookup会进行一次hash查询数据,若没有该值会进行第二次hash,进行查询,还是没有会返回false。这种方案的空间利用率很高,查询效率也很高。
// Insert inserts data into the counter and returns true upon success
func (cf *Filter) Insert(data []byte) bool {
// 返回hash后应当插入的位置i1和插入的byte值fp
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
// 如果插入成功则直接返回true
if cf.insert(fp, i1) {
return true
}
// 第一个位置插入失败会进行二次hash插入第二个位置
i2 := getAltIndex(fp, i1, cf.bucketPow)
// 如果插入成功则直接返回true
if cf.insert(fp, i2) {
return true
}
return cf.reinsert(fp, randi(i1, i2))
}
// InsertUnique inserts data into the counter if not exists and returns true upon success
func (cf *Filter) InsertUnique(data []byte) bool {
if cf.Lookup(data) {
return false
}
return cf.Insert(data)
}
使用Insert插入时会先进行一次hash,得出应当插入位置和应当插入的值,如果这个这个位置(bucket内的4个位置均被占用)插入失败。会进行第二次hash,查看第二个位置能否插入。若第二个位置插入失败,则会随机在两个位置挑选一个将其中的一个值标记为旧值,用新值覆盖旧值,旧值会在重复上面的步骤进行插入。
InsertUnique会对插入的值进行校验,只有当未插入过该值时才会插入成功,若过滤器中已经存在该值,会插入失败返回false。
插入成功则count+1
// Delete data from counter if exists and return if deleted or not
func (cf *Filter) Delete(data []byte) bool {
i1, fp := getIndexAndFingerprint(data, cf.bucketPow)
if cf.delete(fp, i1) {
return true
}
i2 := getAltIndex(fp, i1, cf.bucketPow)
return cf.delete(fp, i2)
}
func (cf *Filter) delete(fp fingerprint, i uint) bool {
if cf.buckets[i].delete(fp) {
if cf.count > 0 {
cf.count--
}
return true
}
return false
}
Delete会先通过两次hash找到索引位置,若有该数据,将该位置数据删除,并且执行count-1
// Encode returns a byte slice representing a Cuckoofilter
func (cf *Filter) Encode() []byte {
bytes := make([]byte, len(cf.buckets)*bucketSize)
for i, b := range cf.buckets {
for j, f := range b {
index := (i * len(b)) + j
bytes[index] = byte(f)
}
}
return bytes
}
// Decode returns a Cuckoofilter from a byte slice
func Decode(bytes []byte) (*Filter, error) {
var count uint
if len(bytes)%bucketSize != 0 {
return nil, fmt.Errorf("expected bytes to be multiple of %d, got %d", bucketSize, len(bytes))
}
buckets := make([]bucket, len(bytes)/4)
for i, b := range buckets {
for j := range b {
index := (i * len(b)) + j
if bytes[index] != 0 {
buckets[i][j] = fingerprint(bytes[index])
count++
}
}
}
return &Filter{
buckets: buckets,
count: count,
bucketPow: uint(bits.TrailingZeros(uint(len(buckets)))),
}, nil
}
Encode方法会将过滤器转化为一个[]byte返回, Decode会将一个[]byte转化为一个过滤器结构。
func (cf *Filter) Reset() {
for i := range cf.buckets {
cf.buckets[i].reset()
}
cf.count = 0
}
Reset方法会将过滤器所有数据清空。
布谷鸟和布隆对比
相比布谷鸟过滤器,布隆过滤器有以下不足:
查询性能弱是因为布隆过滤器需要使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低。
空间效率低是因为在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多。不过布隆过滤器并没有要求位图的长度必须是 2 的指数,而布谷鸟过滤器必须有这个要求。从这一点出发,似乎布隆过滤器的空间伸缩性更强一些。
不支持反向删除操作这个问题着实是击中了布隆过滤器的软肋。在一个动态的系统里面元素总是不断的来也是不断的走。布隆过滤器就好比是印迹,来过来就会有痕迹,就算走了也无法清理干净。比如你的系统里本来只留下 1kw 个元素,但是整体上来过了上亿的流水元素,布隆过滤器很无奈,它会将这些流失的元素的印迹也会永远存放在那里。随着时间的流失,这个过滤器会越来越拥挤,直到有一天你发现它的误判率太高了,不得不进行重建。
布谷鸟过滤器在论文里声称自己解决了这个问题,它可以有效支持反向删除操作。而且将它作为一个重要的卖点,诱惑大家放弃布隆过滤器改用布谷鸟过滤器。














 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









