







RDD相关源码阅读笔记
转载请标明出处:http://blog.csdn.net/bigbigdata/article/details/48412199
最好的源码阅读方法就是调试,没有之一
之前其实有阅读过RDD相关的源码,最近学习过程中发现在之前原本阅读过的模块中有一些『关节』并没有打通,所以想通过调试的方式来更细致得学习源码。
本文为编写测试用例并调试RDD相关模块的笔记,并没有列出具体的调试过程,仅列出结论以做备忘,特别是那些比较容易忽略或者说是其他blog或者书本中比较少提到的。
RDD重要成员及方法
依赖
RDD共提供了3个与依赖相关的成员,如下:
//< 保存与其直接父RDDs的依赖
private var dependencies_ : Seq[Dependency[_]] = null
protected def getDependencies: Seq[Dependency[_]] = deps
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies
}
dependencies_
}
}
当调试代码时,若碰到明明由其他RDD执行transform操作而生成的RDD的dependencies_成员为空,比如下面这种情况:
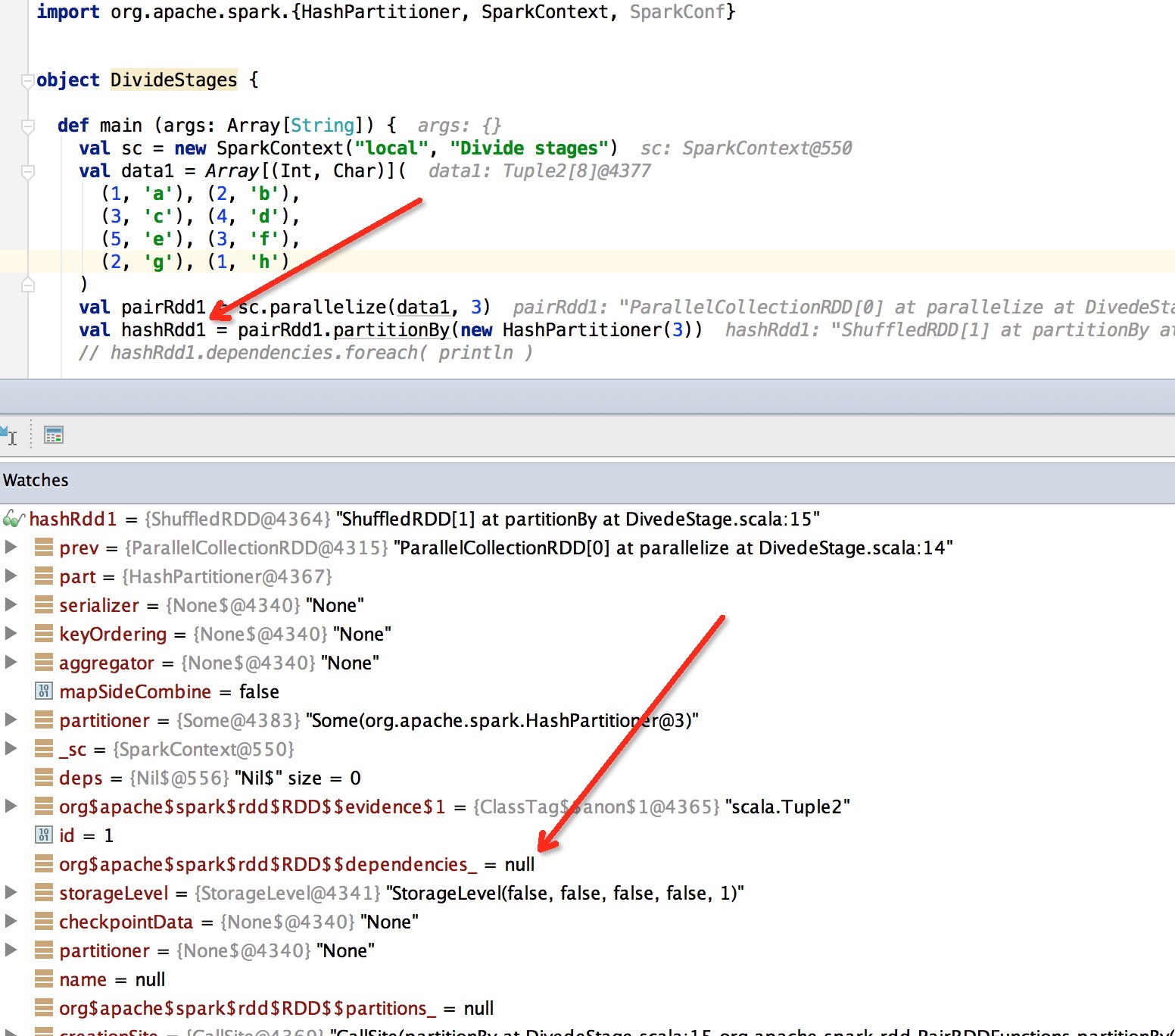
莫要惊慌,并不是hashRdd1没有依赖的父RDD,而是没有将该依赖赋值给dependencies_而已,在产生hashRdd1后,只需调用hashRdd1.dependencies就可以在调试的监控窗口看到hashRdd1.dependencies_该有的值了。
这并没有什么不妥,在之后DAGScheduler划分Stage过程中,会调用所有RDD的dependencies方法。
分区
RDD中与分区相关的成员有:
protected def getPartitions: Array[Partition]
//< partitions_为数组类型
@transient private var partitions_ : Array[Partition] = null
final def partitions: Array[Partition] = {
checkpointRDD.map(_.partitions).getOrElse {
if (partitions_ == null) {
partitions_ = getPartitions
}
partitions_
}
}
//< 可选的
@transient val partitioner: Option[Partitioner] = None分区相关的需要知道以下几点:
1. 与『依赖』一样,若明明由其他RDD执行transform操作而生成的RDD的partitions_成员为空并不是该RDD没有分区,只是还没将分区赋值给partitions_,之后的操作会通过调用成员函数partitions进行赋值并返回
2. partitioner为可选值,对于非key-value的RDD该值为None。key-value类型的RDD也需要在创建时指定partitioner。目前公有HashPartitioner,RangePartitioner两种Partitioner
缓存等级
RDD支持缓存,可支持缓存到磁盘、内存、OffHeap及是否序列化缓存。RDD包含缓存等级成员:
private var storageLevel: StorageLevel = StorageLevel.NONE,默认为StorageLevel.NONE,StorageLevel定义及StorageLevel.NONE定义如下:
//< StorageLevel定义
class StorageLevel private(
private var _useDisk: Boolean,
private var _useMemory: Boolean,
private var _useOffHeap: Boolean,
private var _deserialized: Boolean,
private var _replication: Int = 1){...}
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
...
}从上面代码可以看出默认值StorageLevel.NONE表示不以任何方式缓存RDD
CreationSite
对于这个成员,我不知道怎么用中文描述好,该成员在RDD主构造函数中定义如下
@transient private[spark] val creationSite = sc.getCallSite(),表示程序员写的具体哪个类中的哪行代码生成这个RDD。
有两种格式,一种是shortForm,即短格式,如parallelize at DivedeStage.scala:14;还有一种是longForm,即长格式,如
org.apache.spark.SparkContext.parallelize(SparkContext.scala:563)
DivideStages$.main(DivedeStage.scala:14)
DivideStages.main(DivedeStage.scala)RDD还提供了getCreationSite方法以获取该creationSite,该方法会在RDD.toString方法中被调用以告知该RDD是程序员写的哪行代码生成的
checkpoint相关
在执行rdd的checkpoint之前,首先要调用SparkContext.setCheckpointDir(directory: String)来设置checkpoint的目录,其实这里设置的checkpoint目录还不是最终checkpoint目录,SparkContext.setCheckpointDir实现会在参数指定的目录下新建一个以UUID.randomUUID().toString命名的目录,如果application跑在集群环境下,该目录必须是个HDFS目录。
在RDD调用checkpoint方法时,如下:
def checkpoint() {
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new RDDCheckpointData(this))
checkpointData.get.markForCheckpoint()
}
}会创建一个RDDCheckpointData实例,该类保存与checkpint相关的所有信息,包括:关联的RDD,check point状态(公有Initialized, MarkedForCheckpoint, CheckpointingInProgress, Checkpointed集中状态),check point文件及check point得到的RDD。
在调用checkpointData = Some(new RDDCheckpointData(this))时,check point状态被置为Initialized。之后调用checkpointData.get.markForCheckpoint()将check point状态置为MarkedForCheckpoint。这里只是标记该RDD需要check point,并不会真的执行check point。
check point是个比较复杂的流程,我将会专门写一篇文章介绍,这里就不展开了。
others
RDD的成员和方法有好几十个,无法一一列举。最后再列几个方法:
//< 由子类实现来计算一个给定的分区
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
//< 获得某个partition的优先位置,这对调度task非常重要
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
//< 缓存RDD,可以缓存内存、磁盘、OffHeap等;cache方法其实也是对该方法进行了封装
def persist(newLevel: StorageLevel): this.type = {
...
}小知识点
- RDD具有name属性,可通过
RDD.setName设置,name默认为null - RDD id如何确定?
答:任何类型的RDD都继承于abstract class RDD,那么,在创建任何类型RDD实例时,都会调用该abstract class RDD的主构造函数,在该abstract class RDD主构造函数中通过调用val id: Int = sc.newRddId()获取RDD id,sc对应的application中每生成一个RDD,sc.newRddId()就会被调用一次并返回比上次大1的值,从0开始。从这里也可以看出,application中所有rdd的id都是由SparkContext分配的,越先生成的rdd的id越小















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









