







以下是分析ads的单行数据量超过1000万时,map任务出现600s time out的问题:
1、map函数调用cpu消耗profile
以下是map函数调用cpu消耗profile图:
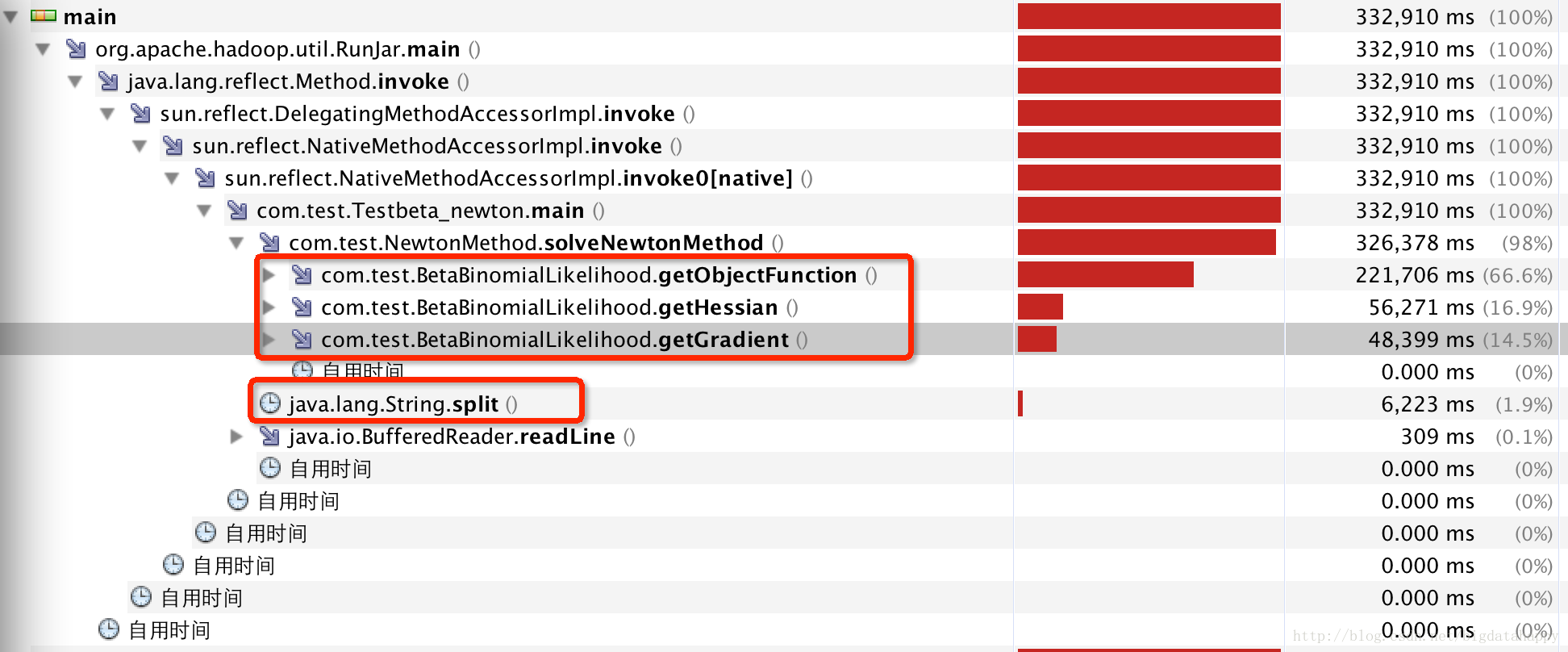
以上是用户代码函数调用cpu使用总的情况,下图是上图中红圈框出来的更底层函数调用cpu使用情况:

从图上看出,cpu98%的时间都消耗在getObjectFunction()、getHessian()和getGradient()方法上,进一步分析这三个方法下面的调用情况,这三个方法分别调用第三方math3包下面Gamma类的三个方法,这说明该job比较耗cpu的地方其实都是在调用第三方包的时候。
2、2.4集群单行数据处理时间统计
单行数据量100万、300万、700万和1000万分别平均处理时间,以及处理时间柱状图:
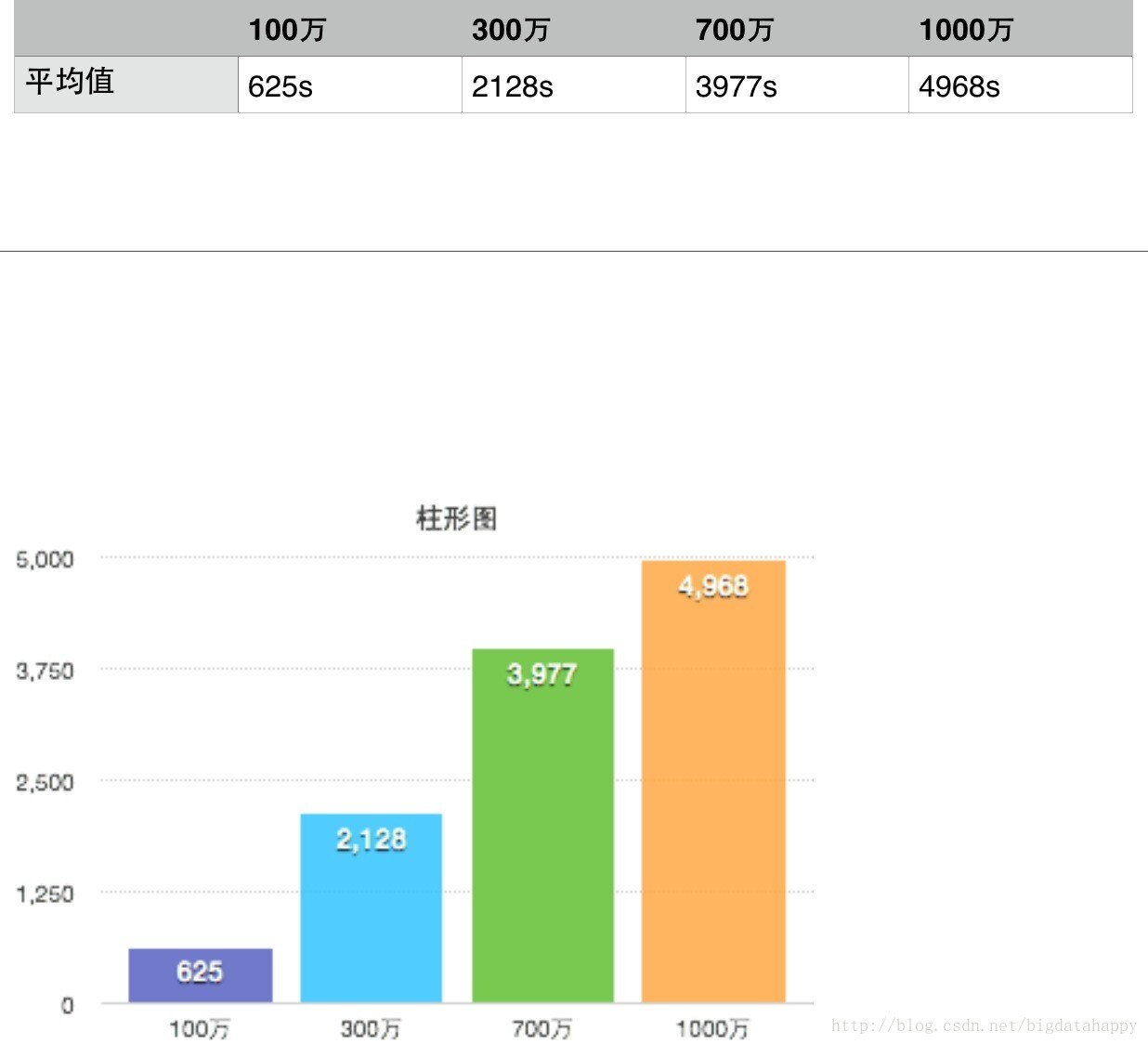
可以看出,根据数据量的增长,处理时间基本是按线性增长的。
下面重点来看一下单行1000万数据量处理时间详细信息,以下是在2.4集群的gate way分别提交了三次job的情况:
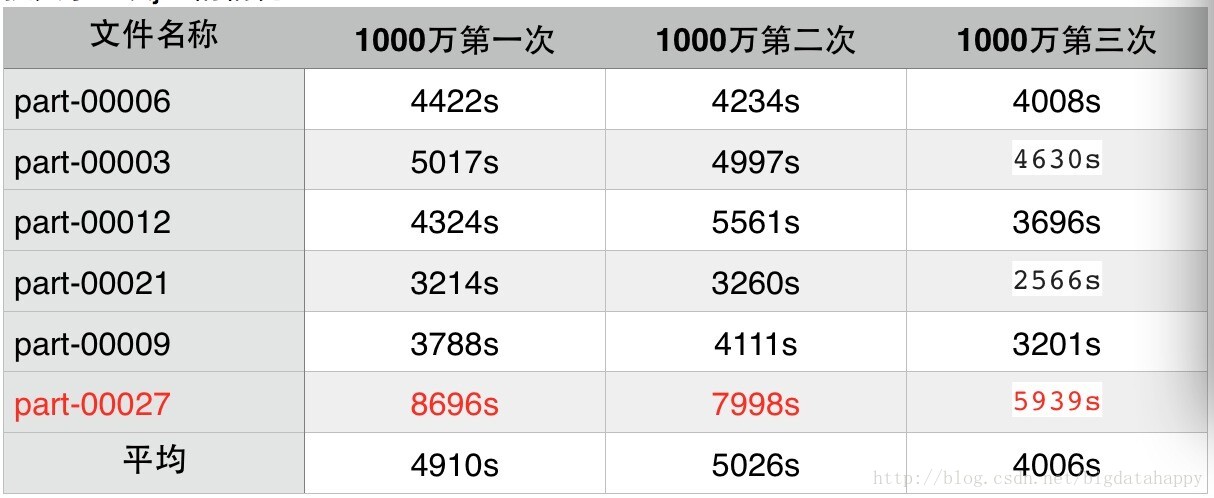
但是在处理part-00027文件时,平均处理时间为7544s,约2小时5分钟左右,从上表看出,单行数据量1000万时,平均处理时间5000s,约1小时20分钟左右,第一个job处理时间最大花了8696s,约2小时25分钟左右。
以下看一下处理part-00027文件的map任务内存和cpu使用情况:
(1)、内存使用情况:
根据RM页面找到对应的NM,在找到对应的container,根据jstat -gcutil命令查看内存使用情况:
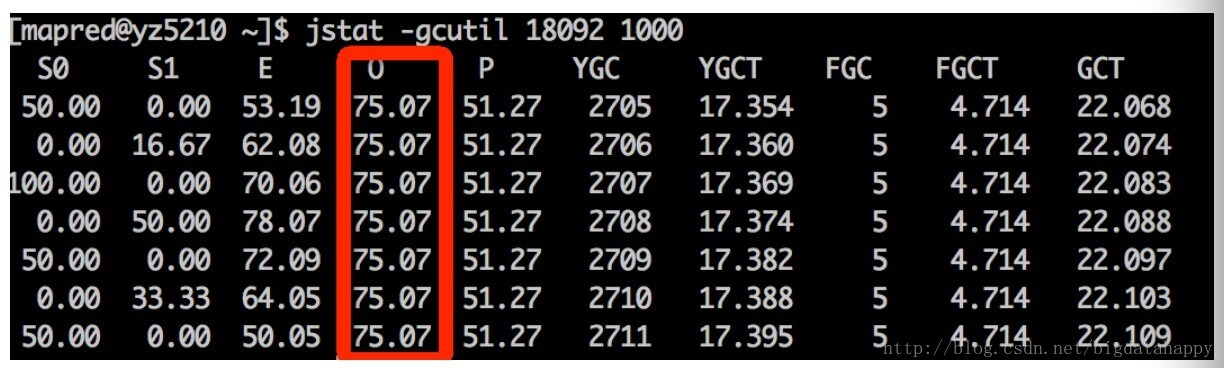
可以看出老年代内存使用为75%,不是因为内存不足导致频繁Full GC而出现的问题。
(2)、cpu使用情况:
执行top命令查看cpu使用情况:
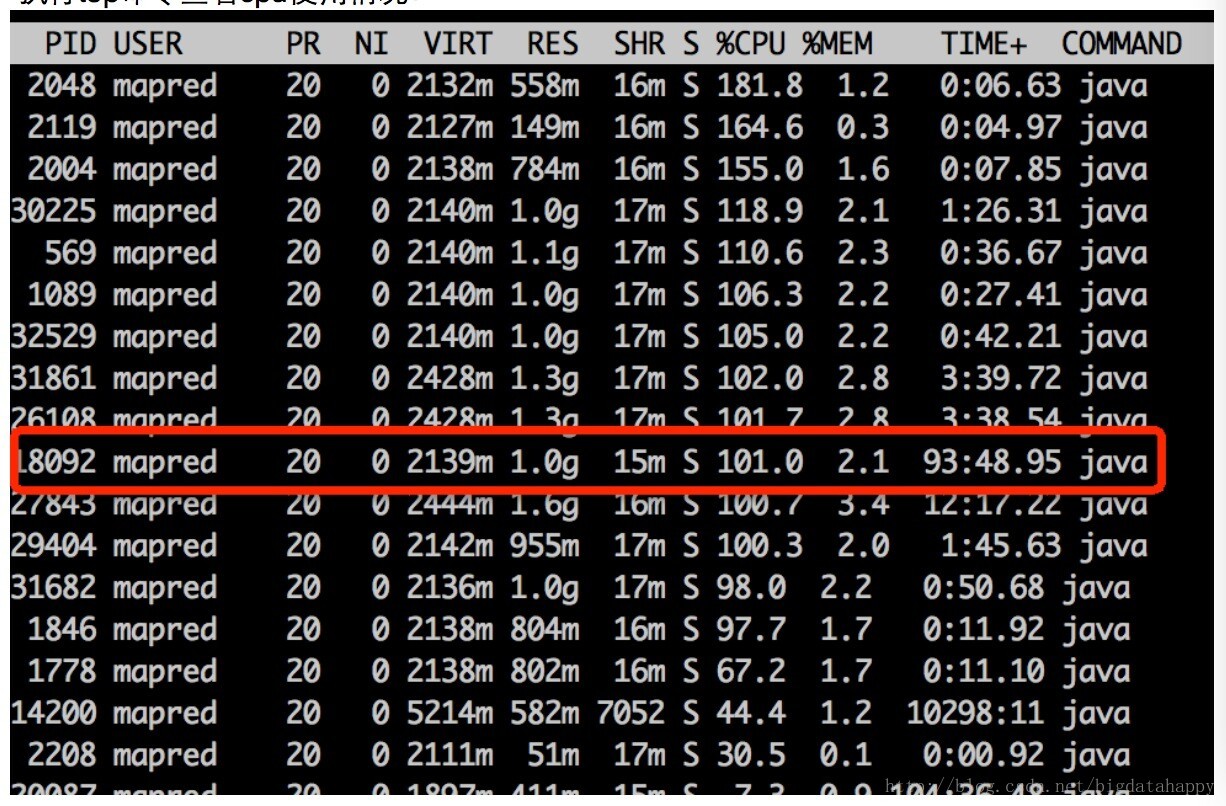
由于是单线程处理,cpu使用为101%,说明该map任务是cpu密集型任务,该任务的瓶颈在计算上。
总结:
既然该job不能从代码层面进行优化,就只能修改参数了,最好的解决办法是延长map任务的超时时间为3小时,既10800000ms,代码如下:
conf.setInt("mapred.task.timeout", 10800000);














 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









