







上节我们看到了transformation是如何转换成streamgraph的,转换成streamgraph后flink client还需做进一步处理将streamgraph转换成jobgraph。下面我们来看一下streamgraph是如何转换成jobgrah的。
streamgraph转换成jobgrah需要做以下几步:
1.将streamNode转成成JobVertex
2.将符合条件的streamNode chain在一起
3.将streamEdge转换成jobEdge
4.输出中间计算结果IntermediateDataSet

1.JobGraph的生成
我们还是从最初的方法切入:env.execute




这个execute方法是一个抽象方法,有四个实现类,会根据集群类型选择不同的实现类

这里我们选择AbstractJobClusterExecutor的execute方法进行讲解:这个方法里主要有两部分一是获取jobGraph,二是创建集群描述器
@Override
public CompletableFuture<JobClient> execute(
@Nonnull final Pipeline pipeline,
@Nonnull final Configuration configuration,
@Nonnull final ClassLoader userCodeClassloader)
throws Exception {
//获取jobgraph,这里的pipline就是streamgraph
final JobGraph jobGraph = PipelineExecutorUtils.getJobGraph(pipeline, configuration);
//创建集群描述器
try (final ClusterDescriptor<ClusterID> clusterDescriptor =
clusterClientFactory.createClusterDescriptor(configuration)) {
final ExecutionConfigAccessor configAccessor =
ExecutionConfigAccessor.fromConfiguration(configuration);
final ClusterSpecification clusterSpecification =
clusterClientFactory.getClusterSpecification(configuration);
final ClusterClientProvider<ClusterID> clusterClientProvider =
clusterDescriptor.deployJobCluster(
clusterSpecification, jobGraph, configAccessor.getDetachedMode());
LOG.info("Job has been submitted with JobID " + jobGraph.getJobID());
return CompletableFuture.completedFuture(
new ClusterClientJobClientAdapter<>(
clusterClientProvider, jobGraph.getJobID(), userCodeClassloader));
}这里jobgraph就已经生成了,下面我们深入到更详细的方法中去看jobgraph具体是怎么生成的
2.getJobGraph方法
public static JobGraph getJobGraph(
@Nonnull final Pipeline pipeline, @Nonnull final Configuration configuration)
throws MalformedURLException {
checkNotNull(pipeline);
checkNotNull(configuration);
//根据配置信息获取执行配置的访问器
final ExecutionConfigAccessor executionConfigAccessor =
ExecutionConfigAccessor.fromConfiguration(configuration);
//调用FlinkPipelineTranslationUtil.getJobGraph的方法获取jobGrpah
final JobGraph jobGraph =
FlinkPipelineTranslationUtil.getJobGraph(
pipeline, configuration, executionConfigAccessor.getParallelism());
configuration
.getOptional(PipelineOptionsInternal.PIPELINE_FIXED_JOB_ID)
.ifPresent(strJobID -> jobGraph.setJobID(JobID.fromHexString(strJobID)));
//将jar包,主类,savepoint等设置进jobGraph
jobGraph.addJars(executionConfigAccessor.getJars());
jobGraph.setClasspaths(executionConfigAccessor.getClasspaths());
jobGraph.setSavepointRestoreSettings(executionConfigAccessor.getSavepointRestoreSettings());
return jobGraph;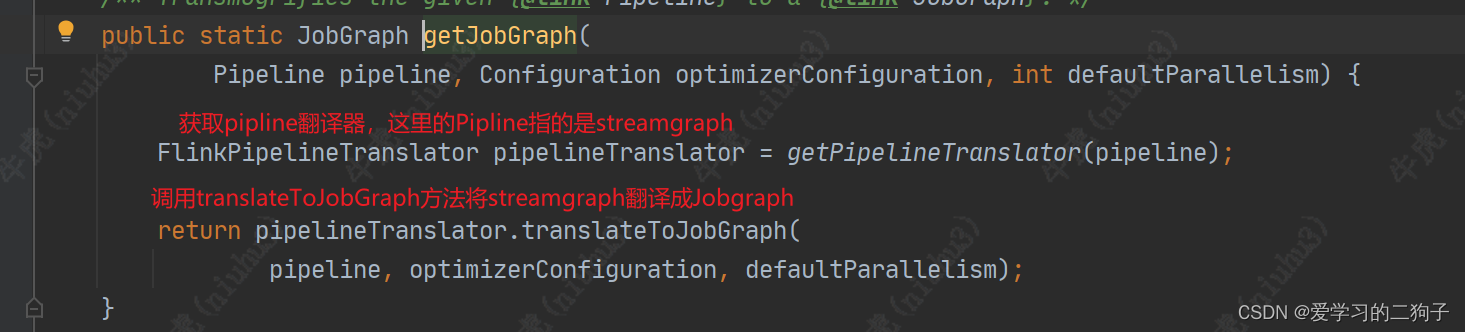
这个方法有两个实现类:
 因为我们是流式job,所以我们选择streamGrpahTranslator
因为我们是流式job,所以我们选择streamGrpahTranslator
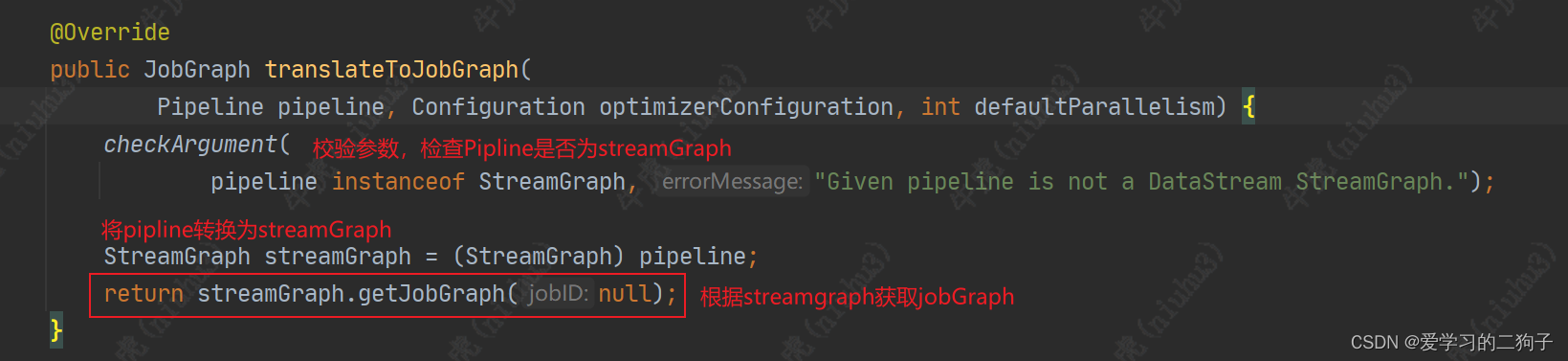
此方法里用生成器模式获取JobGraph,然后又调用了异构方法

下面就到关键方法createJobGraph:
这个方法中主要做了以下工作:
1.预先checkpoint和其他的一些配置
2.生成确定性哈希,以便在提交为发生变化的情况下对其进行标识
3.设置可以chaining在一起的节点
4.设置physicalEdge
private JobGraph createJobGraph() {
//1.做了一些预先校验,校验checkpoint配置
preValidate();
jobGraph.setJobType(streamGraph.getJobType());
jobGraph.enableApproximateLocalRecovery(
streamGraph.getCheckpointConfig().isApproximateLocalRecoveryEnabled());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
//为节点生成确定性哈希,以便在提交为发生变化的情况下对其进行标识
Map<Integer, byte[]> hashes =
defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
//生成旧版本哈希,以向后兼容
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
//将符合条件的节点连在一起
setChaining(hashes, legacyHashes);
//设置PhysicalEdges,将每个JobVertex的入边集合也序列化到该JobVertex的StreamConfig中
setPhysicalEdges();
setSlotSharingAndCoLocation();
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getManagedMemoryOperatorScopeUseCaseWeights(),
id -> streamGraph.getStreamNode(id).getManagedMemorySlotScopeUseCases());
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
final Map<String, DistributedCache.DistributedCacheEntry> distributedCacheEntries =
JobGraphUtils.prepareUserArtifactEntries(
streamGraph.getUserArtifacts().stream()
.collect(Collectors.toMap(e -> e.f0, e -> e.f1)),
jobGraph.getJobID());
for (Map.Entry<String, DistributedCache.DistributedCacheEntry> entry :
distributedCacheEntries.entrySet()) {
jobGraph.addUserArtifact(entry.getKey(), entry.getValue());
}
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
} catch (IOException e) {
throw new IllegalConfigurationException(
"Could not serialize the ExecutionConfig."
+ "This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}3.setChaining
该方法主要做了以下操作:
1.根据算子的确定性哈希获取key为sourceNodeId,value为operatorChainInfo的map数据
2.根据map的key进行排序,将value封装到list中
3.循环遍历该list集合,将可以chain在一起的节点chain在一起
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
// we separate out the sources that run as inputs to another operator (chained inputs)
// from the sources that needs to run as the main (head) operator.
//从streamGraph中获取source算子和其他算子获取将其和nodeId添加进Map中
final Map<Integer, OperatorChainInfo> chainEntryPoints =
buildChainedInputsAndGetHeadInputs(hashes, legacyHashes);
//获取算子信息
final Collection<OperatorChainInfo> initialEntryPoints =
chainEntryPoints.entrySet().stream()
.sorted(Comparator.comparing(Map.Entry::getKey))
.map(Map.Entry::getValue)
.collect(Collectors.toList());
// iterate over a copy of the values, because this map gets concurrently modified
//循环遍历可以chain的算子,创建chain
for (OperatorChainInfo info : initialEntryPoints) {
createChain(
info.getStartNodeId(),
1, // operators start at position 1 because 0 is for chained source inputs
info,
chainEntryPoints);
}
}4.createChain方法
该方法主要功能:
1.获取startNodeId,判断该startNode是否已经创建jobVertices
2.循环遍历获取当前节点的出边并判断是否可以chain
3. 循环遍历可以chain的出边集合,递归调用自身建立chain,并将该出边添加到已转换出边集合
4.循环遍历不可以chain的出边集合,将该出边添加到已转换出边集合
5.判断当前startNoieid是否等于传进来的startNodeId,并创建jobVertex
6.连接starNode节点和该edge并创建jobEdge
现在在这个方法中jobVertex和jobEdge都已创建,这里面的某些方法大家可以自己下去点击源码看看,加深自己对这个代码的理解。
private List<StreamEdge> createChain(
final Integer currentNodeId,
final int chainIndex,
final OperatorChainInfo chainInfo,
final Map<Integer, OperatorChainInfo> chainEntryPoints) {
//获取startNodeId,判断该startNode是否已经创建jobVertices
Integer startNodeId = chainInfo.getStartNodeId();
if (!builtVertices.contains(startNodeId)) {
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
//循环遍历获取当前节点的出边并判断是否可以chain
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
//循环遍历可以chain的出边集合,建立chain,并将该出边添加到已转换出边集合
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll(
createChain(
chainable.getTargetId(),
chainIndex + 1,
chainInfo,
chainEntryPoints));
}
//循环遍历不可以chain的出边集合,将该出边添加到已转换出边集合
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable);
createChain(
nonChainable.getTargetId(),
1, // operators start at position 1 because 0 is for chained source inputs
chainEntryPoints.computeIfAbsent(
nonChainable.getTargetId(),
(k) -> chainInfo.newChain(nonChainable.getTargetId())),
chainEntryPoints);
}
chainedNames.put(
currentNodeId,
createChainedName(
currentNodeId,
chainableOutputs,
Optional.ofNullable(chainEntryPoints.get(currentNodeId))));
chainedMinResources.put(
currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs));
chainedPreferredResources.put(
currentNodeId,
createChainedPreferredResources(currentNodeId, chainableOutputs));
OperatorID currentOperatorId =
chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId)
.addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
//判断当前startNoieid是否等于传进来的startNodeId,并创建jobVertex
StreamConfig config =
currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
setVertexConfig(
currentNodeId,
config,
chainableOutputs,
nonChainableOutputs,
chainInfo.getChainedSources());
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(chainIndex);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
//连接starNode节点和该edge并创建jobEdge
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
config.setOutEdgesInOrder(transitiveOutEdges);
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(
startNodeId, k -> new HashMap<Integer, StreamConfig>());
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config);
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}














 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









