







首先谈谈大数据架构
五横:
数据采集层:既包括传统的ETL离线采集、也有实时采集、互联网爬虫解析等等。
数据处理层:根据数据处理场景要求不同,可以划分为HADOOP、MPP、流处理等等。
数据分析层:主要包含了分析引擎,比如数据挖掘、机器学习、 深度学习
数据访问层:主要是实现读写分离,将偏向应用的查询等能力与计算能力剥离,包括实时查询、多维查询、常规查询等应用场景。
数据应用层:根据企业的特点不同划分不同类别的应用,比如针对运营商,对内有精准营销、客服投诉、基站分析等,对外有基于位置的客流、基于标签的广告应用等等。
一纵:
数据管理层:主要是实现数据的管理和运维,它横跨多层,实现统一管理。

然后谈谈 hadoop 和 spark

关键区别
hadoop是批处理工具,更擅长处理离线数据,而spark在内存中处理数据,可以是实时处理。
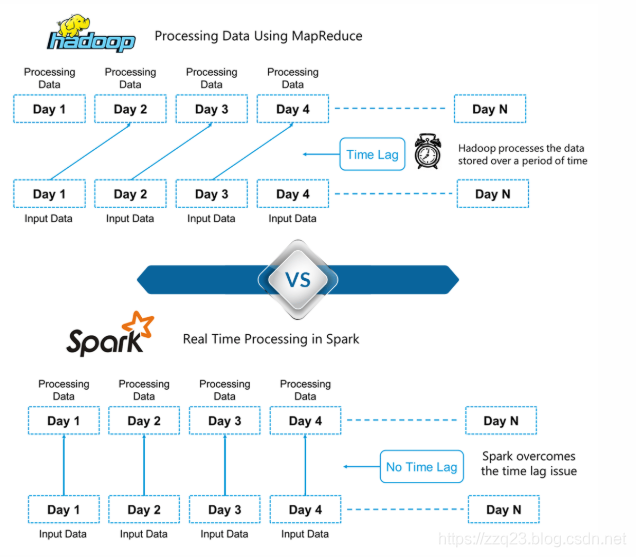
Hadoop基于大数据的批处理。 这意味着数据会在一段时间内先存储下来,然后使用Hadoop进行处理。
在Spark中,处理可以实时进行。
Spark中的这种实时处理能力帮助我们解决实时分析问题。
除此之外,Spark能够比Hadoop MapReduce( Hadoop处理框架)快100倍地进行批处理。
因此,目前Apache Spark是业界大数据处理的首选工具。
接着聊聊spark 和 k8s:
k8s全称kubernetes,k8s是为容器服务而生的一个可移植容器的编排管理工具,越来越多的公司正在拥抱k8s,并且当前k8s已经主导了云业务流程,推动了微服务架构等热门技术的普及和落地,正在如火如荼的发展。那么称霸容器领域的k8s究竟是有什么魔力呢?
从架构设计层面,我们关注的可用性,伸缩性都可以结合k8s得到很好的解决,如果你想使用微服务架构,搭配k8s,真的是完美,再从部署运维层面,服务部署,服务监控,应用扩容和故障处理,k8s都提供了很好的解决方案。
具体来说,主要包括以下几点:
- 服务发现与调度
- 负载均衡
- 服务自愈
- 服务弹性扩容
- 横向扩容
- 存储卷挂载
总而言之,k8s可以使我们应用的部署和运维更加方便。
Spark本身的设计更偏向使用静态的资源管理,虽然Spark也支持了类似Yarn等动态的资源管理器,但是这些资源管理并不是面向动态的云基础设施而设计的,在速度、成本、效率等领域缺乏解决方案。随着Kubernetes的快速发展,数据科学家们开始考虑是否可以用Kubernetes的弹性与面向云原生等特点与Spark进行结合。在Spark 2.3中,Resource Manager中添加了Kubernetes原生的支持。
意味着 我们可以使用k8s对Spark进行管理了,而且能运用云的特性,很好的进行集群伸缩,降低我们的成本以及当运算资源不足时快速增加节点。
参考链接:大数据平台架构--学习笔记 - JackSun924 - 博客园
参考链接:hadoop组件---spark----全面了解spark以及与hadoop的区别_直到世界的尽头-CSDN博客_spark是hadoop的组件
参考链接:什么是K8S - 知乎














 5735
5735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









