







目录:
一 准备工作
二 安装scala 2.10.5
三 安装spark 1.3.1
四 验证安装结果
一 准备工作
(1)配套软件版本要求:Spark runs on Java 6+ and Python 2.6+. For the Scala API, Spark 1.3.1 uses Scala 2.10. You will need to use a compatible Scala version (2.10.x).http://blog.csdn.net/jediael_lu/article/details/45310321 借鉴于本位博主
(2)linux操作系统、oracle jdk1.7、python(根据开发要求决定安与不安装)。
(3)IP:127.0.0.1(回环地址) hostname:Lynch
二 安装scala 2.10.5
(1)下载scala
~$wget http://downloads.typesafe.com/scala/2.10.5/scala-2.10.5.tgz
(2)解压文件
~$tar -zxvf scala-2.10.5.tgz
(3)配置环境变量
#vi .bashrc //(修改etc下的profile也可)
#SCALA VARIABLES START
export SCALA_HOME=/home/Lynch/scala-2.10.5
export PATH=
PATH:
SCALA_HOME/bin
#SCALA VARIABLES END

~
source./bashrc
scala -version
Scala code runner version 2.10.5 – Copyright 2002-2013, LAMP/EPFL
(4)验证scala
~$ scala
Welcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_51).
Type in expressions to have them evaluated.
Type :help for more information.
scala> 9*9
res0: Int = 81

三 安装spark 1.3.1
(1)下载spark
~$wget http://mirror.bit.edu.cn/apache/spark/spark-1.3.1/spark-1.3.1-bin-hadoop2.6.tgz(可以直接搜索网址,下载到电脑上,自己再在指定路径下提取,个人感觉更简单一些 - -)
(2)解压spark
~$tar -zxvf http://mirror.bit.edu.cn/apache/spark/spark-1.3.1/spark-1.3.1-bin-hadoop2.6.tgz(可以直接搜索网址,下载到电脑上,自己再在指定路径下提取,个人感觉更简单一些 - -)
(3)配置环境变量
#vi .bashrc //(修改etc下的profile也可)
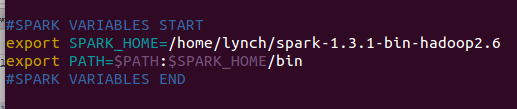
#SPARK VARIABLES START
export SPARK_HOME=/Lynch/spark-1.3.1-bin-hadoop2.6
export PATH=
PATH:
SPARK_HOME/bin
#SPARK VARIABLES END
~$ source ./bashrc
(4)配置spark
~$ pwd //(返回目前所在路径)
/Lynch/spark-1.3.1-bin-hadoop2.6/conf
~
mvspark−env.sh.templatespark−env.sh
vi spark-env.sh
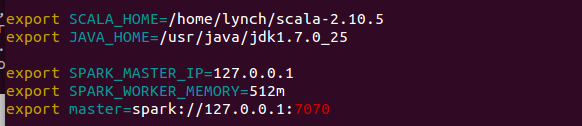
export SCALA_HOME=/home/Lynch/scala-2.10.5
export JAVA_HOME=/usr/java/jdk1.7.0_25
export SPARK_MASTER_IP=127.0.0.1
export SPARK_WORKER_MEMORY=512m
export master=spark://127.0.0.1:7070
~$vi slaves
lynch-Lenovo
//(与你的hostname对应起来!!!否则后期启动spark时会报错:ssh服务无法识别你的主机名或者主机服务)

(5)启动spark
~
pwd//(返回目前所在路径)/Lynch/spark−1.3.1−bin−hadoop2.6/sbin
./start-all.sh
(注意,hadoop也有start-all.sh脚本,为避免混淆,要进入spark目录下执行脚本)

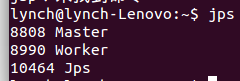
~$ jps //(检查启动状态)
(6)关闭spark
~
pwd//(返回目前所在路径)/Lynch/spark−1.3.1−bin−hadoop2.6/sbin
./stop-all.sh
(注意,hadoop也有start-all.sh脚本,为避免混淆,要进入spark目录下执行脚本)

四 验证安装结果
(1)启动起spark之后,运行自带示例检查效果
~$ /bin/run-example org.apache.spark.examples.SparkPi
(注意:这是在Lynch/spark-1.3.1-bin-hadoop2.6/bin/下跑一个自带的example,其中run-example是shell的运行指令,不要弄混!!!)
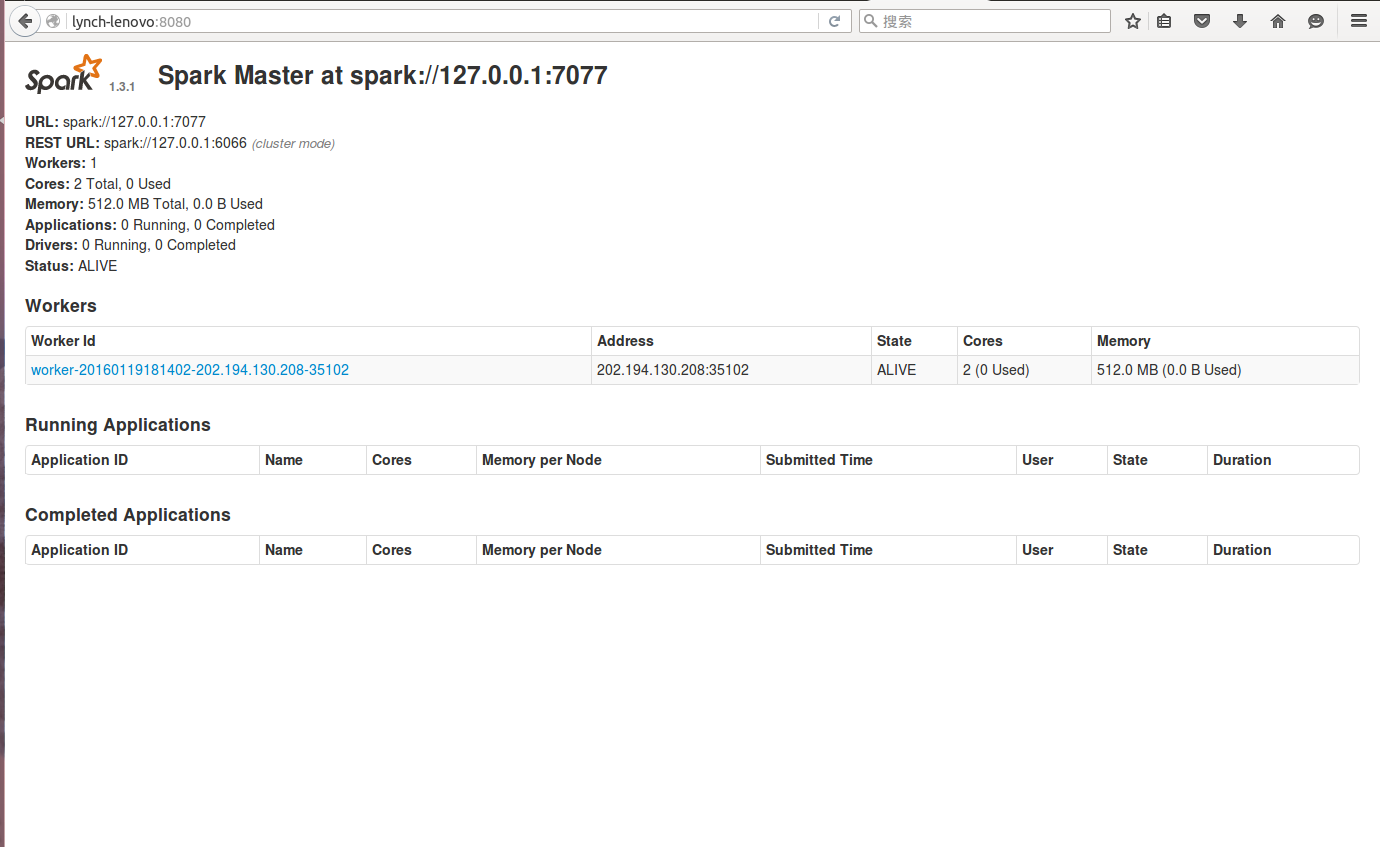
(2)查看集群环境状态
浏览器中输入地址: http://Lynch:8080/(注意:对应主机名)
(3)进入spark-shell
~$spark-shell
(4)查看jobs
浏览器中输入地址:http://master:4040/jobs/(注意:对应主机名)
到此为止,spark伪分布式安装流程基本结束,总体来说和hadoop伪分布式安装流程差不多,甚至更为简单,接下来将给大家继续带来的是:
(1) spark入门级案例
(2) spark分布式环境搭建
(3) spark与机器学习相结合
敬请期待… …















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









