









前段时间接到一个棘手的难题(识别图片文字,将图片文件名改成该文字)
因为不解决就得手动挨个挨个输入然后把文件命名好
今天又一个文件需求是这样的
图上有姓名文字,要识别出来改成每一张图跟这个一样,有的人说了缩略图的时候一个个改就好了
那么我很服这样的人,5000多页身份证也这么干,我墙都不扶就服你
Windows详细命名规则如下:

1、允许文件或者文件夹名称不得超过255个字符;
2、 文件名除了开头之外任何地方都可以使用空格;
3、文件名中不能有下列符号:“?”、“、”、“╲”、“/”、“*”、““”、“”“、“<”、“>”、“|”;
4、 Windows 98文件名不区分大小写,但在显示时可以保留大小写格式;
5、 文件名中可以包含多个间隔符。
软件下载地址:
百度网盘:https://pan.baidu.com/s/1COwcHMa0xXdyVUJr1DC2BA?pwd=6688
腾讯云盘:https://share.weiyun.com/k8wRaPvq
全文扫描识别的先看看软件长啥样:
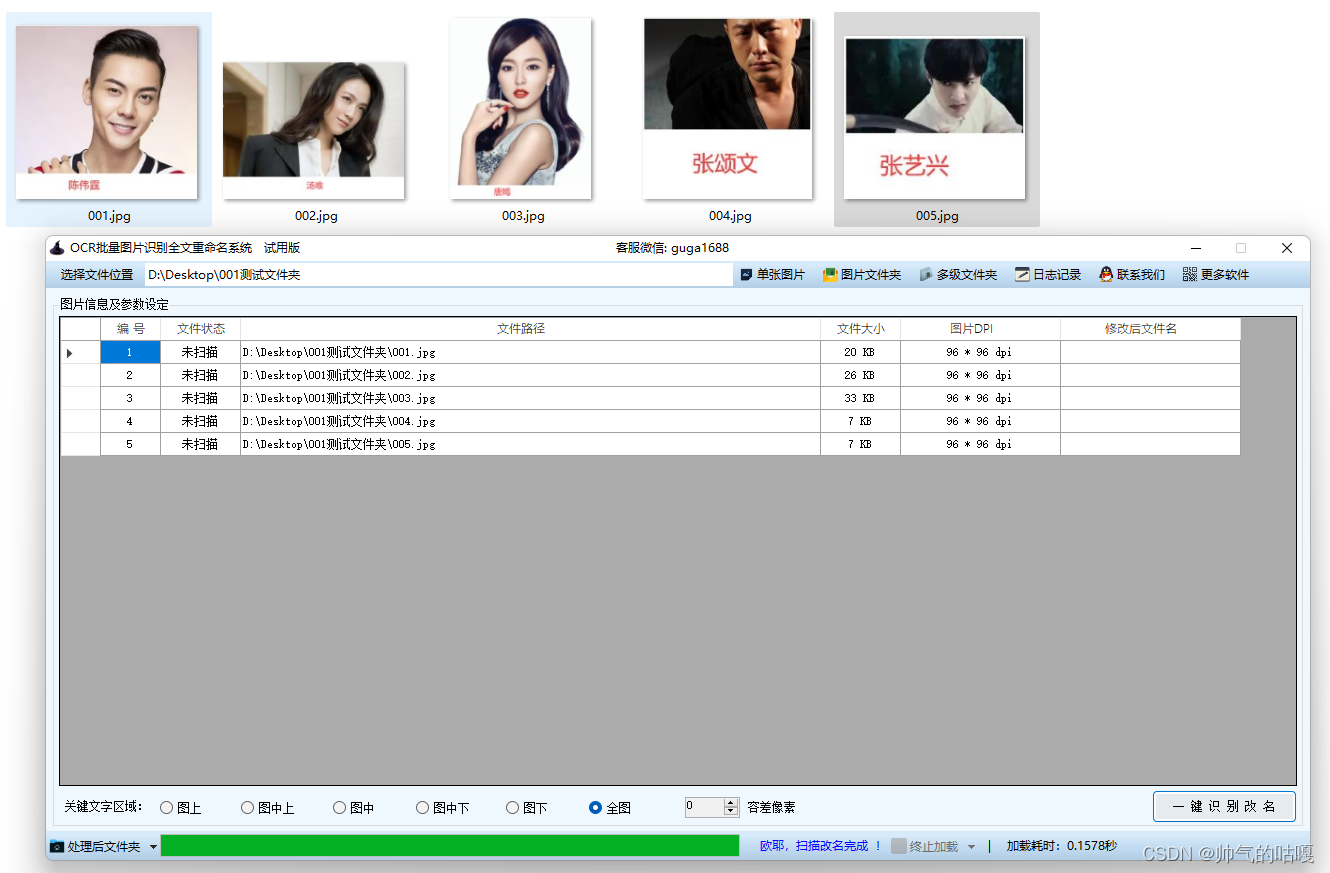
加载完图片后,自动识别自动修改,无需人工参与,文件名直接改掉
处理后的图片名称就是这样的
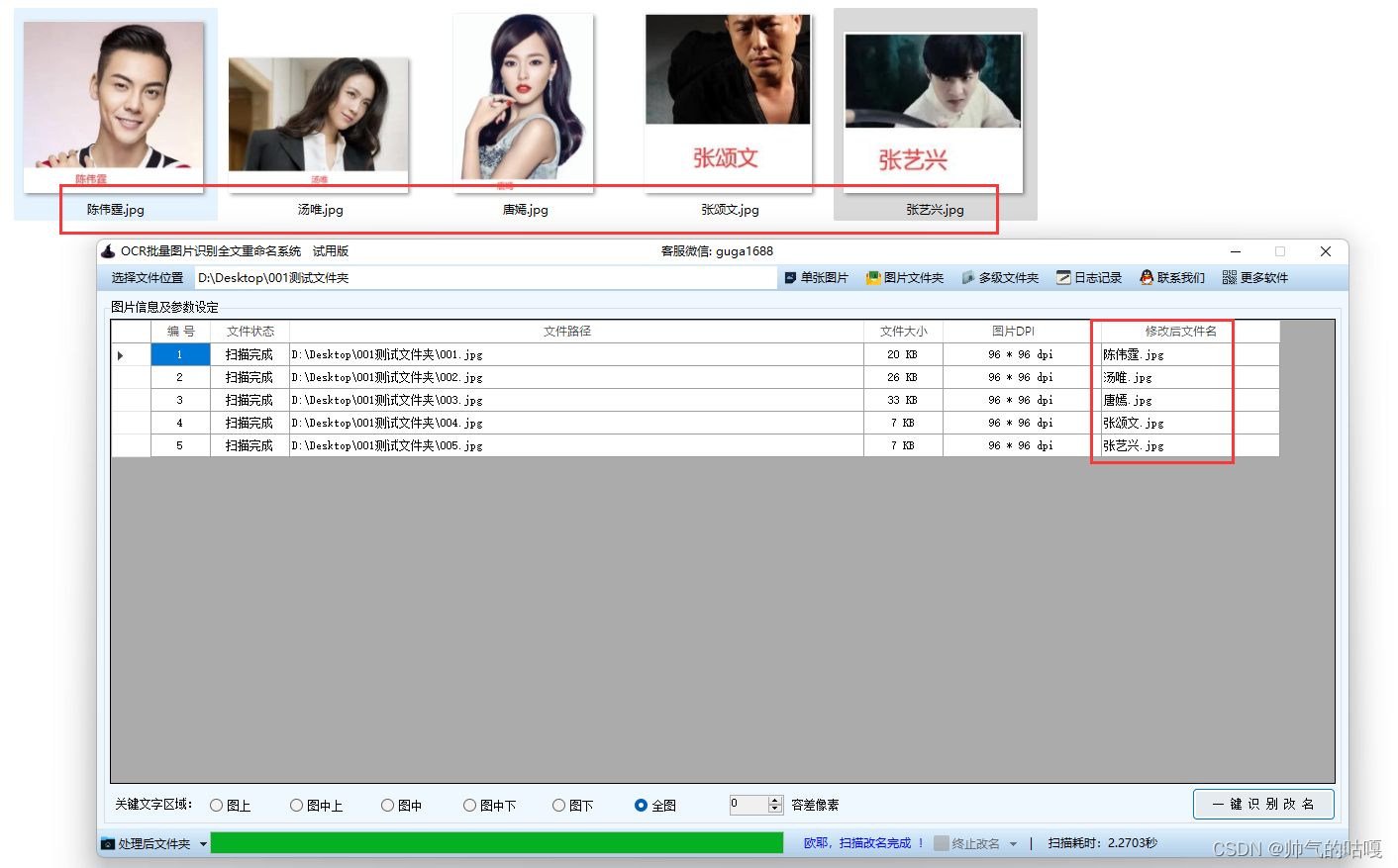
如果是区域识别这个就不太适用,区域识别可以参考:
【批量识别图片内容改名】如何批量识别图片中的文字并自动改名,批量的识别区域内容如何重命名改名
区域这个东西需要定制去写命名的算法有些难度,遇到这样类似的问题可以参考我的方式和方法来完成每个命名都是有自己的特殊性,需要 更改成自己的命名方式,这里就做的没有那么智能 ,有的需要改成身份证号,有的需要改成自己的姓名,有的或者有其他特殊的就需要动源程序
核心代码
FileInfo fi=new FileInfo(原文件名)
fi.MoveTo(新文件名 )
然后调一调就好了,上干货吧,主要的核心思想是CaptureImage +OCR + moveTo分三步来实施
最后新版的操作界面图可以预览下
软件下载地址:
百度网盘:https://pan.baidu.com/s/1COwcHMa0xXdyVUJr1DC2BA?pwd=6688
腾讯云盘:https://share.weiyun.com/k8wRaPvq















 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









