







 本文详细介绍了Hadoop单机安装的全过程,包括环境准备(安装Java,创建Hadoop账号,配置SSH无密码登录),下载安装Hadoop 2.6.0并配置环境变量,配置Hadoop,启动HDFS和YARN,以及如何使用HDFS和运行MapReduce作业。通过这些步骤,读者可以成功搭建起一个Hadoop单机环境。
本文详细介绍了Hadoop单机安装的全过程,包括环境准备(安装Java,创建Hadoop账号,配置SSH无密码登录),下载安装Hadoop 2.6.0并配置环境变量,配置Hadoop,启动HDFS和YARN,以及如何使用HDFS和运行MapReduce作业。通过这些步骤,读者可以成功搭建起一个Hadoop单机环境。
环境准备
安装Java
过程简单,这里省略具体安装步骤。安装后确认相应版本的Java已安装,这里选择1.7。
java -version
创建Hadoop账号
为Hadoop创建一个专门的账号是很好的实践:
sudo adduser hadoop
sudo passwd hadoop
授予 Hadoop root权限
为了测试,图方便,这里给Hadoop root权限,生产环境不建议这样做。
使用root权限编辑/etc/sudoers:
sudo vim /etc/sudoers末尾添加一行:
hadoop ALL=(ALL) ALL
切换到Hadoop账号:
su hadoop配置SSH无密码登录
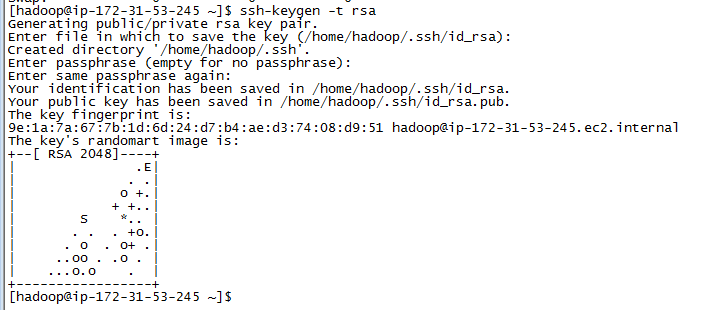
首先生成公私密钥对、
ssh-keygen -t rsa指定key pair的存放位置,回车默认存放于/home/hadoop/.ssh/id_rsa
输入passphrase,这里直接回车,为空,确保无密码可登陆。
拷贝生成的公钥到授权key文件(authorized_keys)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys改变key权限为拥有者可读可写(0600) :
chmod 0600 ~/.ssh/authorized_keyschomod命令参考:
chmod 600 file – owner can read and write
chmod 700 file – owner can read,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4294
4294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









