







 本文详细介绍了MapReduce中的Shuffle机制,包括分区与排序的原理和实现。通过具体案例分析了自定义Partitioner的重要性,讨论了全排序、部分排序和二次排序的分类。此外,还讲解了Combiner的使用及其优化效果,以及GroupingComparator在分组排序中的应用。
本文详细介绍了MapReduce中的Shuffle机制,包括分区与排序的原理和实现。通过具体案例分析了自定义Partitioner的重要性,讨论了全排序、部分排序和二次排序的分类。此外,还讲解了Combiner的使用及其优化效果,以及GroupingComparator在分组排序中的应用。
目录
一、Shuffle机制
Mapreduce确保每个reducer的输入都是按键排序的。系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle。
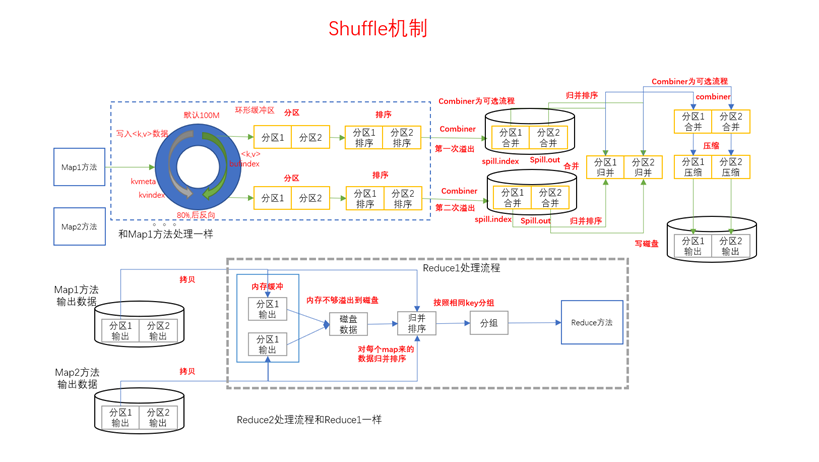
二、partition分区
Partition分区流程处于Mapper数据属于初到环形缓冲区时进行,此时会将通过Partition分区获取到的每一行key-value对应的分区值计入环形缓冲流的左。
(一)问题引出
要求将统计结果按照条件输出到不同文件中(分区)。比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
分区可以实现将Map阶段处理的数据在向环形缓冲区写入的时候是以"分类"的方式写的。"一般情况下",MR程序分区数有多少,ReduceTask的数量就应该有多少,可以实现一个分区的数据一个ReduceTask去处理。ReduceTask处理完成之后都会去生成一个结果文件
以WordCount为例,设置ReduceTask的数量
job.setNumReduceTasks(2);
(二)MapReduce底层默认分区机制
默认使用的是HashPartitioner分区机制
@Public
@Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public HashPartitioner() {
}
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & 2147483647) % numReduceTasks; // 2147483647是int类型的最大值,numReduceTask即是上面设置的ReduceTask的值
}
}
这种分区机制是不可控的,因为它是根据Map阶段获取的key的hashCode值和numReduceTask取余得来的,但是key的hashCode值不确定,所以把key-value数据分到哪一个区我们是不确定的。比如会出现不同的key的HashCode值一致,导致结果输出的不可控制。因此我们在去定义分区的时候我们最常用的方法就是:自定义分区机制
(三)自定义Partition(案例)
自定义Partition步骤:
- 继承Partitioner类:在继承Partitioner类时,应该传递一个<key, value>的泛型,它代表的是需要进行分区的数据,所以需要传递的是map阶段输出的key-value类型,因为分区是在Map阶段执行结束之后往ReduceTask阶段在输出数据时执行的
- 重写里面的getPartition方法,返回值是一个int类型,返回值就是我们的分区。执行逻辑返回一个从0开始的一个连续型数字。比如getPartition返回的取值有0 1 2 3 4时就代表有5个分区,0是1号分区,对应的文件是part-r-00000文件,以此类推。
- 要求:
- 返回的分区数字最好是连续的,比如返回了 0 2 3 4 ,数字不连续,不可行
- 一般情况下,有几个分区,就在Driver中指定numReduceTasks就有几个,不能多写也不能少写
-
public int getPartition(Text key, Text value, int numReduceTask)方法有三个参数,返回一个int类型的值,它们代表的含义分别是:
@param key:Map阶段输出的key值
@param value:Map阶段输出的value值
@param numReduceTask:定义的ReduceTask的任务数,默认是1
@return 数字,代表的是我要将这条key-value数据输送到哪个分区
- 要求:
- 在Driver类中指定分区所在的类与分区数量
// 定义不使用默认的HashPartitioner分区,而是使用自定义的分区
job.setPartitionerClass(PhoneDataPartition.class);
// 指定你的ReduceTask必须是5
job.setNumReduceTasks(5);这里要求ReduceTask的数量必须和自定义的Partition类中设置的分区数量保持一致,原因就是在MR程序中一般默认情况下是一个分区要有一个ReduceTask专门去处理。但是在有些情况下,ReduceTask可能少写或者多写,这样会出一些奇怪的问题。
- 假设Mapper阶段输出的分区是5个,但是设置了1个ReduceTask任务去执行,程序可以运行成功,此时在HDFS中生成1个结果文件。虽然有多个分区,但是一个ReduceTask可以处理这多个分区。
- 但是假设Mapper阶段输出的分区是5个,ReduceTask的数量少于5个,这时程序不能运行,且程序报IO异常的错误。(不患寡而患不均)
java.lang.Exception: java.io.IOException: Illegal partition for 138 (2)
(这里可以利用打工人来举例,假设有五个人一起去打工,但是此时岗位只有一个,那么这五个人可以一起做着一份工作。但是如果设置了两个岗位,分配时将会出现矛盾状况,比如两个工人都想做一份工作,或者两个工人都不想做这一个工作,就会产生冲突)
3. 假设分区有5个,ReduceTask的数量也有5个,那么百分之百可以正常运行,这也是最佳状态/最理想状态。(因为每个人都分配到了自己想做的工作)
4. 假设分区有5个,ReduceTask的数量多于5个,程序也是百分之百可以正常运行,但是会多出一个空白结果文件
【注意】以后在工作中写的ReduceTask的数量最好和分区的数量保持一致,这样的话才能保证处理出的MR程序处于最佳状态
案例一:电话归属地
需求:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
分区:
136----分区1
137----分区2
138----分区3
139----分区4
其他---分区5
默认分区机制:5个分区,需要设置5个ReduceTask,同时默认分区机制是按照key的HashCode值分配的
代码:
- PhoneDataMapper.java
public class PhoneDataMapper extends Ma
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 423
423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









