







Faster RCNN 中 RPN 的理解
Faster RCNN github : https://github.com/rbgirshick/py-faster-rcnn
Faster RCNN paper : https://arxiv.org/abs/1506.01497
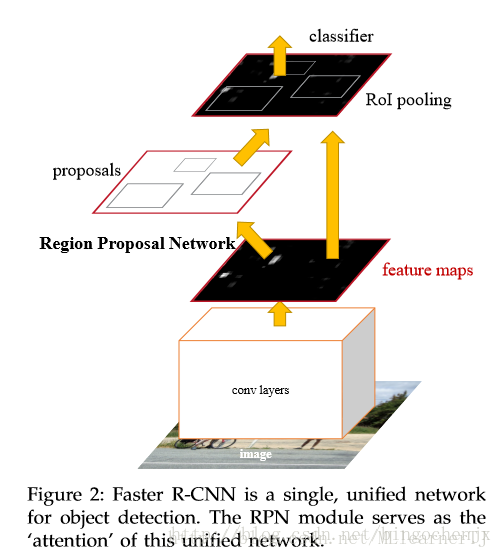
- Faster-Rcnn 基本网络结构
2. RPN 部分的结构
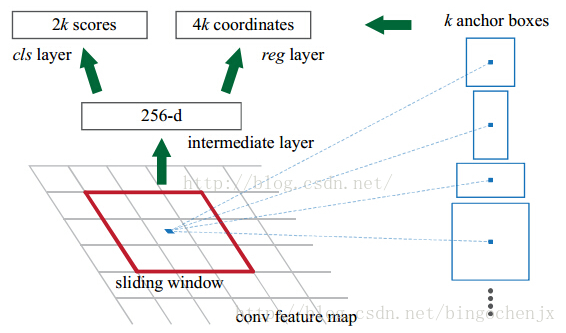
3. anchor,sliding windows,proposals
作者:马塔
转载自:https://www.zhihu.com/question/42205480/answer/155759667
来源:知乎
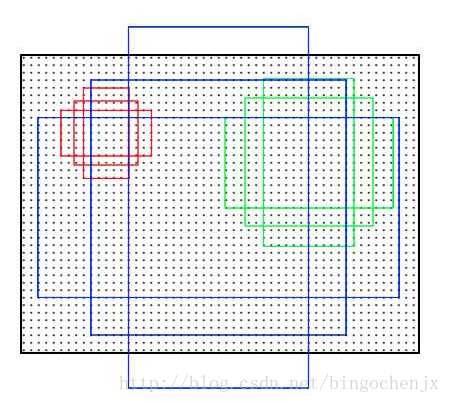
首先我们需要知道 anchor 的本质是什么,本质是 SPP(spatial pyramid pooling) 思想的逆向。而SPP本身是做什么的呢,就是将不同尺寸的输入 resize 成为相同尺寸的输出。所以SPP的逆向就是,将相同尺寸的输出,倒推得到不同尺寸的输入。接下来是 anchor 的窗口尺寸,这个不难理解,三个面积尺寸(1282,2562,512^2),然后在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1).这样一来,我们得到了一共9种面积尺寸各异的 anchor 。示意图如下
至于这个 anchor 到底是怎么用的,这个是理解整个问题的关键。
下面是整个 Faster RCNN 结构的示意图:
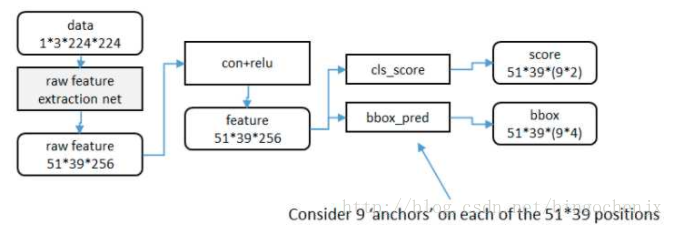
利用anchor是从第二列这个位置开始进行处理,这个时候,原始图片已经经过一系列卷积层和池化层以及relu,得到了这里的 feature:51x39x256(256是层数)
在这个特征参数的基础上,通过一个3x3的滑动窗口,在这个51x39的区域上进行滑动,stride=1,padding=1,这样一来,滑动得到的就是51x39个3x3的窗口。对于每个3x3的窗口,作者就计算这个滑动窗口的中心点所对应的原始图片的中心点。
然后作者假定,这个3x3窗口,是从原始图片上通过SPP池化得到的,而这个池化的区域的面积以及比例,就是一个个的anchor。换句话说,对于每个3x3窗口,作者假定它来自9种不同原始区域的池化,但是这些池化在原始图片中的中心点,都完全一样。这个中心点,就是刚才提到的,3x3窗口中心点所对应的原始图片中的中心点。
如此一来,在每个窗口位置,我们都可以根据9个不同长宽比例、不同面积的anchor,逆向推导出它所对应的原始图片中的一个区域,这个区域的尺寸以及坐标,都是已知的。而这个区域,就是我们想要的 proposal。所以我们通过滑动窗口和anchor,成功得到了 51x39x9 个原始图片的 proposal。
接下来,每个 proposal 我们只输出6个参数:每个 proposal 和 ground truth 进行比较,把与ground truth 中重叠最大的 bounding box 的iou当成是这个proposal的iou, iou>0.7, 认为这个proposal是positive;iou<0.3, 认为这proposal是negative,我们希望positive的proposal包含前景的概率高一些,negative包含背景的概率高一些;iou位于这之间的不做处理。
然后对每个proposal进行分类和bounding box regression:得到的前景概率和背景概率(2个参数)(对应图上的 cls_score);由于每个 proposal 和 ground truth 位置及尺寸上的差异,从 proposal 通过平移放缩得到 ground truth 需要的4个平移放缩参数(对应图上的 bbox_pred)。
所以根据我们刚才的计算,我们一共得到了多少个anchor box呢? 51 x 39 x 9 = 17900
约等于 20 k















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









