







【项目背景】
作为一名人资人员,整天因为面试、筛选、笔试、考核、上报、优化等高度重复的工作而头疼!俗话说:俗话说得好,重复的事情自动话。
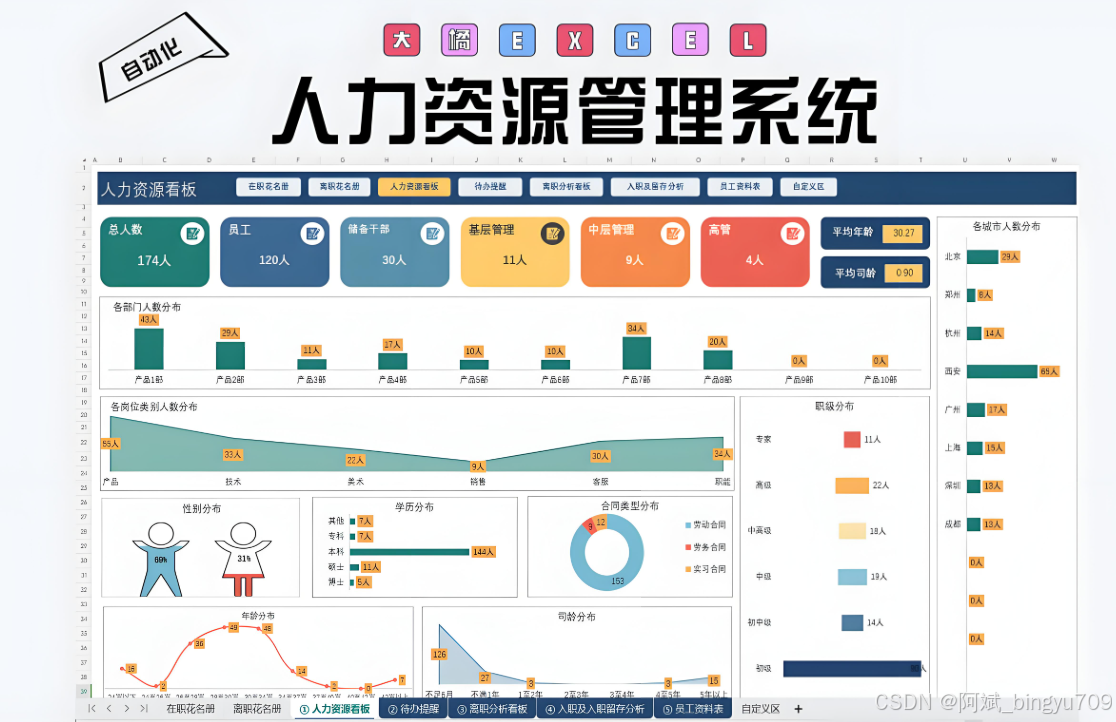
说来就来,今天就通过自动程序化实现以上步骤。
开发一个根据个人档案自动匹配岗位的人力资源系统,以下是分步骤的实现方案:
1. 系统架构设计
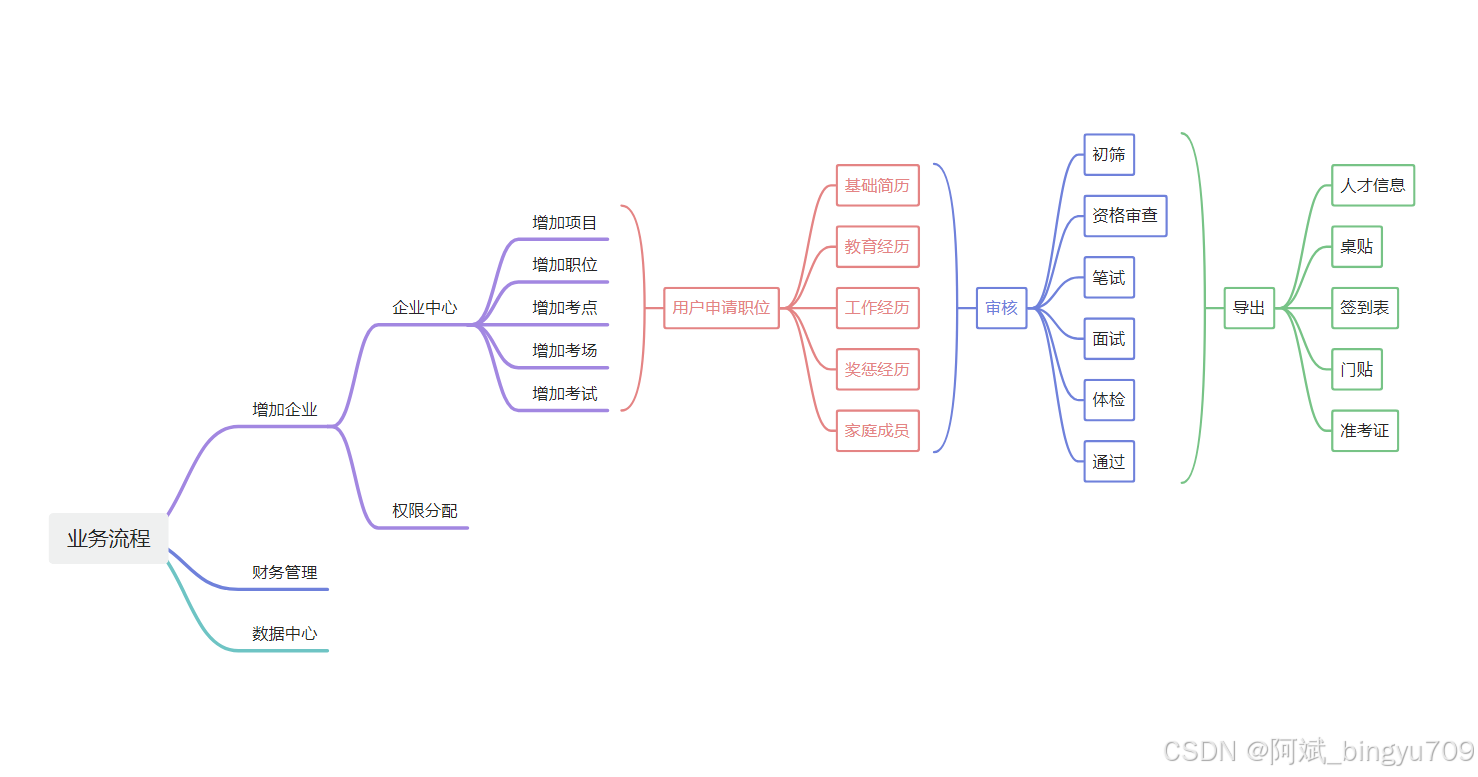
前端:使用 React/Vue.js 构建用户界面,支持档案上传、岗位浏览和匹配结果展示。
后端:采用 Python + Flask/Django 框架,处理业务逻辑和匹配算法。
数据库:选择 PostgreSQL(结构化数据)或 MongoDB(灵活存储非结构化数据),存储员工档案和岗位信息。
算法层:基于规则引擎或机器学习模型(如 scikit-learn)实现匹配逻辑。
2. 数据模型设计
员工档案表(Employees)
- 基本信息:姓名、联系方式、年龄、性别。
- 教育背景:学校、专业、学历(如本科、硕士)。
- 工作经历:公司、职位、工作时长、行业。
- 技能:编程语言、工具(如 Python, Excel)及熟练程度(1-5级)。
- 证书:证书名称(如 PMP, AWS认证)、颁发机构、获取时间。
- 项目经验:项目描述、角色、技术栈、成果(文本字段)。
岗位表(Positions)
- 岗位名称、部门、职责描述。
- 硬性要求:最低学历、专业限制、必需证书。
- 技能要求:必备技能、加分技能及权重。
- 经验要求:最低工作年限、行业偏好。
- 其他:薪资范围、工作地点。
---
3. 匹配算法设计
步骤1:数据处理
- 文本处理:使用 NLP 技术(如 TF-IDF 或 BERT)提取项目经验和岗位描述中的关键词。
- 标准化:将技能、证书等标签化,例如 `Python → 技能:Python`。
步骤2:匹配维度与权重
- 硬性条件过滤(必须满足)
学历是否达标
是否具备必需证书
工作年限是否满足最低要求。
- 软性条件评分(加权计算)
| 软性条件 | 项目 | 权重 |
| 技能匹配度 |
| 40% |
| 经验相关性 |
| 30% |
| 教育背景 |
| 20% |
| 项目经验 |
| 10% |
步骤 3:综合评分与排序
- 对通过硬性条件的岗位,按软性条件加权总分排序。
- 公式示例:
总分 = (技能得分 × 0.4) + (经验得分 × 0.3) + (教育得分 × 0.2) + (项目得分 × 0.1)
---
4. 技术实现细节
规则引擎
用 Python 编写条件判断逻辑,处理硬性过滤。
相似度计算
- 使用 `scikit-learn` 的 `TfidfVectorizer` 处理文本。
- 用 `cosine_similarity` 计算岗位描述与项目经验的相似度。
- **机器学习优化**(可选):
- 收集历史招聘数据(如员工入职后的表现),训练分类模型(如随机森林)预测匹配度。
- 使用协同过滤推荐相似员工成功的岗位。
---
5. 用户界面与功能
员工端
- 上传/编辑个人档案(支持 PDF 解析或表单填写)。
- 查看匹配岗位列表(按评分排序)及匹配详情(如“技能匹配度 90%”)。
HR 端
- 发布/编辑岗位信息。
- 查看候选员工匹配报告,支持手动调整权重或筛选条件。
---
6. 安全与隐私
- 数据加密:敏感信息(如身份证号)加密存储。
- 权限控制:RBAC(角色基于访问控制),确保员工仅访问自身数据。
- 合规性:遵循 GDPR 等法规,提供数据导出/删除功能。
---
7. 测试与迭代
- **单元测试**:验证硬性条件过滤和评分逻辑。
- **A/B 测试**:对比不同权重设置下的匹配效果。
- **反馈循环**:允许用户标记不匹配的推荐,用于优化模型。
---
8. 部署与扩展
- **云部署**:使用 AWS/Aliyun 部署,支持弹性扩展。
- **微服务化**:将匹配算法拆分为独立服务,便于升级。
9.未来扩展
- 集成招聘平台 API(如 LinkedIn)自动获取档案。
- 添加员工职业发展建议(如“学习 Java 可提升 20% 匹配度”)。
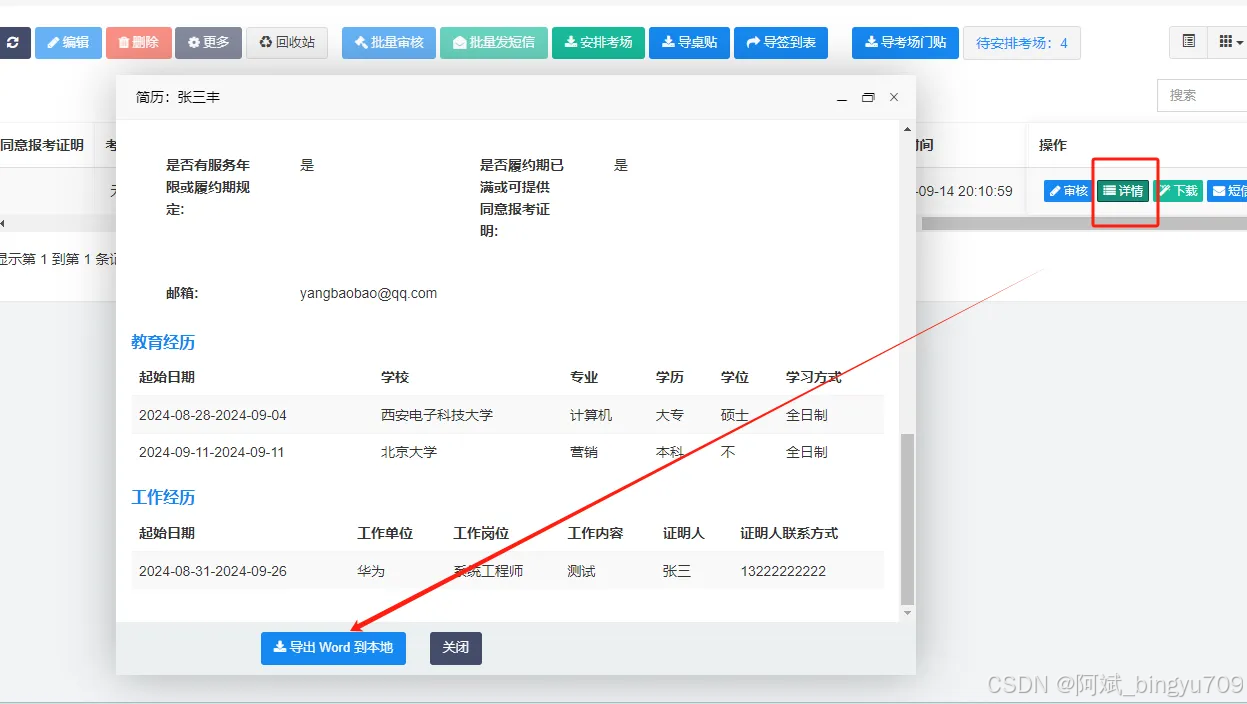
通过以上步骤,可构建一个高效、可扩展的自动化人力资源匹配系统,帮助企业和员工快速定位合适岗位。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











