







 视频编解码基本框架
视频编解码基本框架
本文简要概述视频编解码中的基本流程。具体表现为下图的过程:
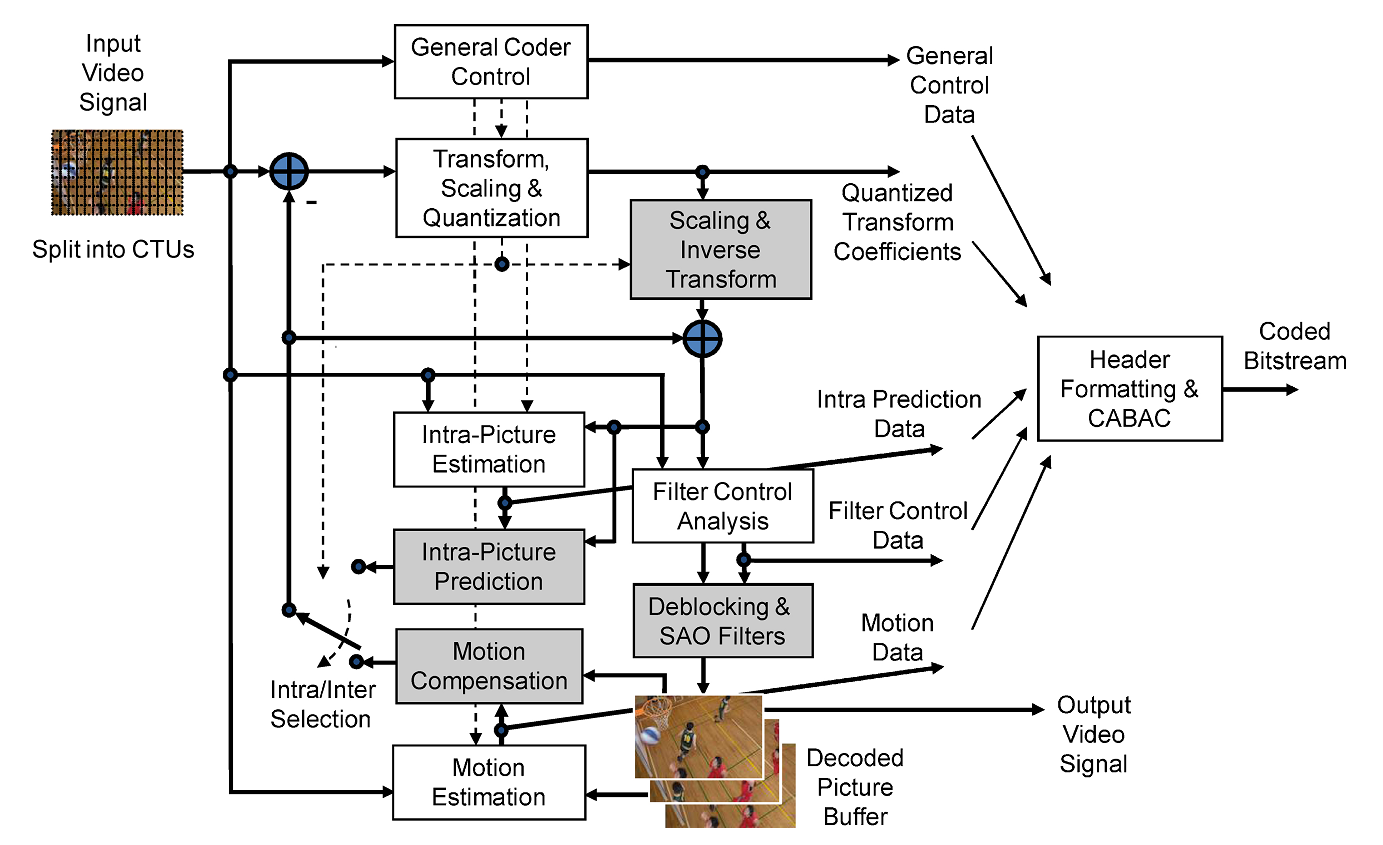
编码流程:
(1)预测:视频由按照时间序列的图像构成。每一幅图像相邻像素之间存在较强的空间相关性,而相邻图像(不同时间)之间存在时间上的相关性。充分利用这些信息,可以有效的帮助我们去除这些冗余信息。根据空间和时间相关性,存在帧内预测和帧间预测两种不同的方式。两者都需要根据已编码的像素去预测未编码像素。通常选取第一帧作为参考帧,而不进行处理。通过帧内/帧间预测的方式,我们可以将预测值和真实值的残差进行编码操作。下面逐一介绍帧内预测和帧间预测的方法:
(a) 帧内预测:该预测值来自于周围已编码结果的线性组合。由于图像中存在特定的纹理,因此该预测值的计算存在几种不同的模式,例如:垂直模式,水平模式,DC模式,Plane 模式等。在实际中我们需要扫描所有的模式从而通过拉格朗日率失真优化进行选择。具体为计算
其中变量 D 表示失真的大小,而变量 R 表示其他的影响因素。我们需要综合考虑代价函数,而不仅仅只是残差的大小。
(b)帧间预测:主要采用基于块的运动补偿技术。该技术通过相邻图像高度的时间相关性,可以为当前图像中的每一个像素寻找之前已经编码图像的一个最佳匹配块(运动估计),用参考像素块和当前像素块,可以定义一个运动矢量。类似于帧内预测&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4456
4456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









