






最近生产上出现一个问题,某个应用单个SQL中绑定变量个数超过了65535个,导致数据库出现了异常终止的现象。
通过trace,看到很多这样的信息(为了脱敏,此处引用MOS的例子),
导致问题的SQL诸如这种,
BEGIN
UPDATE TEST SET
C1 = :1,
C2 = :2,
C3 = :3,
C4 = :4,
C5 = :5,
C6 = :6,
C7 = :7
WHERE ID = :8 AND ACC = :9
;
UPDATE TEST SET
C1 = :10,
C2 = :11,
C3 = :12,
C4 = :13,
C5 = :14,
C6 = :15,
C7 = :16
WHERE ID = :17 AND ACC = :18
;
UPDATE TEST SET
C1 = :19,
C2 = :20,
C3 = :21,
C4 = :22,
C5 = :23,
C6 = :24,
C7 = :25
WHERE ID = :26 AND ACC = :27
;
...
UPDATE TEST SET
C1 = :619001,
C2 = :619002,
C3 = :619003,
C4 = :619004,
C5 = :619005,
C6 = :619006,
C7 = :619007,
WHERE ID = :619008 AND ACC = :619009
; END;这是一段PL/SQL,其中批量拼接了很多的update,1条SQL是9个变量,总共六十多万个,粗略算下来,应该是6万多条SQL,显然他的逻辑是一次性更新6万多条记录。
此时问题有两个,
(1) 执行一次SQL为什么带着这么多绑定变量?
(2) 为什么执行这么多绑定变量的SQL会导致数据库出现问题?
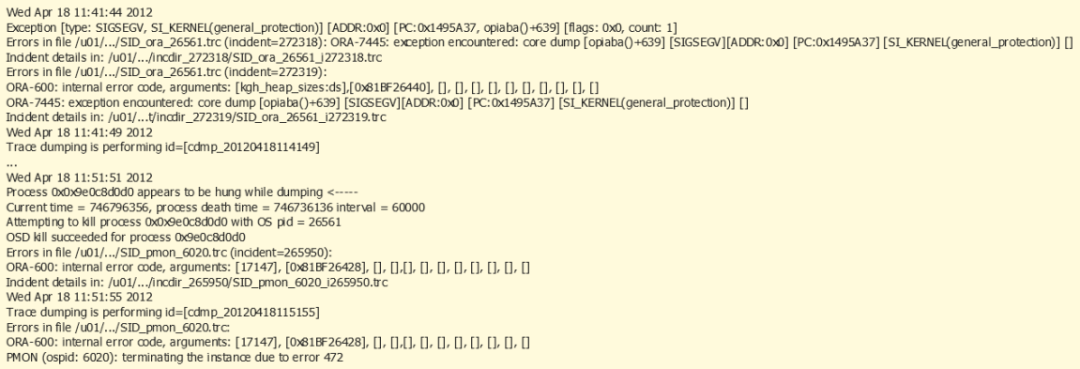
MOS的这篇文章《Instance crashed after ORA-7445 [opiaba] and ORA-600 [17147] (Doc ID 1466343.1)》给出了第二个问题的答案,
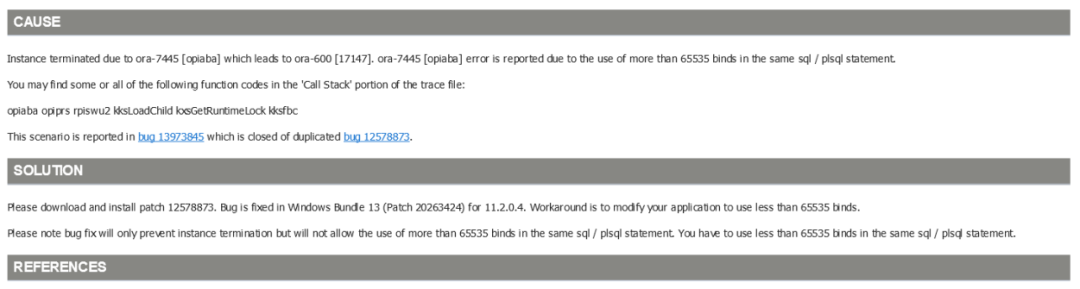
如果在同一条SQL或PL/SQL语句中使用超过65535个绑定变量,则数据库实例会因为ORA-7445的错误导致出现ORA-600,进而异常中断。
官方给出的方案,是打个12578873的patch,但是他只会解决因为绑定变量超多导致的实例终止的问题,超过65535绑定变量的语句还是不能执行,因此无论是workaround,还是终极解决,都是建议不要使用绑定变量超过65535个,这就回到了第一个问题,超过65535个绑定变量的场景,合理么?
其实针对这案例,60多万个绑定变量,不是应用“有意而为之”的,他想做的是一次性批量更新6万多记录,但是他在MyBatis的mapper中用的是for-each,这就会循环遍历list,"BEGIN"开头,";END"结尾,";"作为separator,拼接出的PL/SQL,一次性执行,
<update id="active" parameterType="java.util.List">
<foreach collection="list" open="BEGIN" close=";END;" item="item" separator=";" index="index">
UPDATE TEST SET
C1 = #{item.c1},
C2 = #{item.c2},
C3 = #{item.c3},
C4 = #{item.c4},
C5 = #{item.c5},
C6 = #{item.c6},
C7 = #{item.c7}
WHERE ID = #{item.id} AND ACC = #{item.acc}
</foreach>
</update>P. S. 关于MyBatis的for-each,可以参考官方文档的介绍,
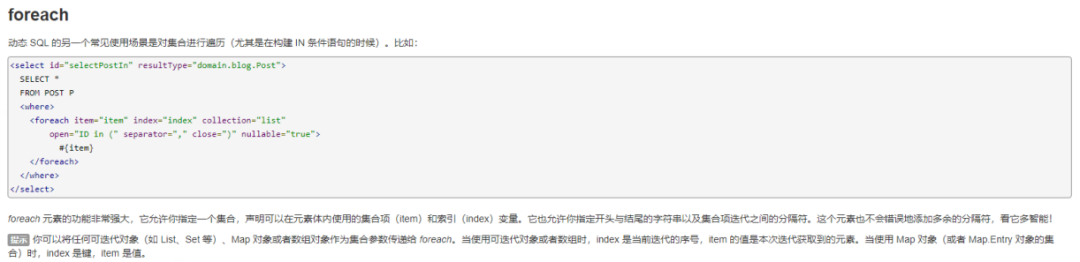
https://mybatis.org/mybatis-3/zh/dynamic-sql.html
如果要批量更新这些数据,该怎么做?
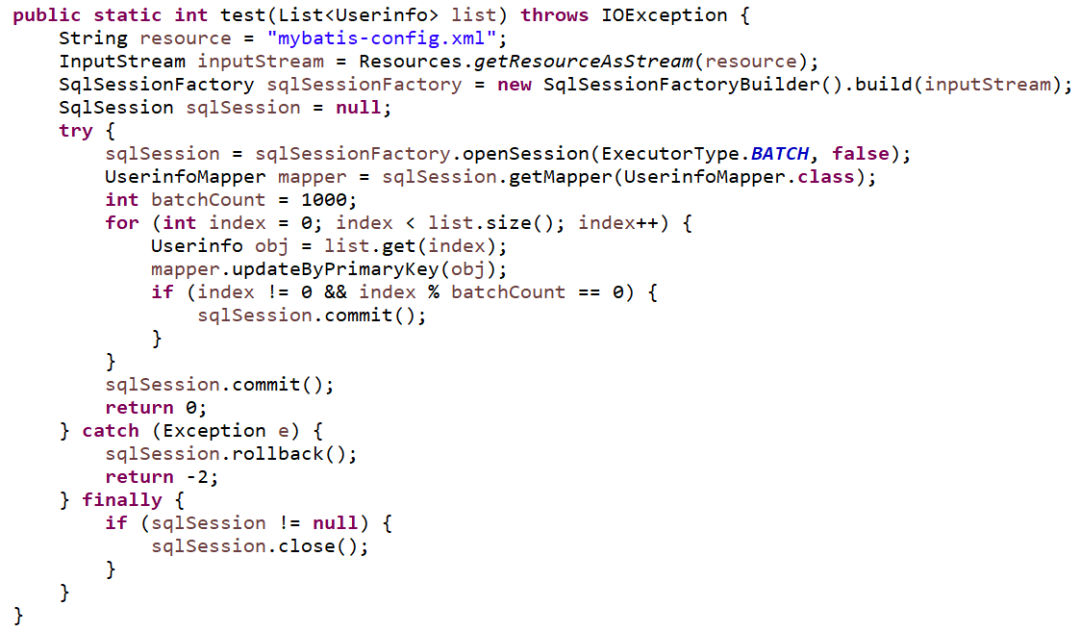
官网介绍了,应该用的是openSession时指定参数ExecutorType.BATCH,他将批量执行所有的更新语句,
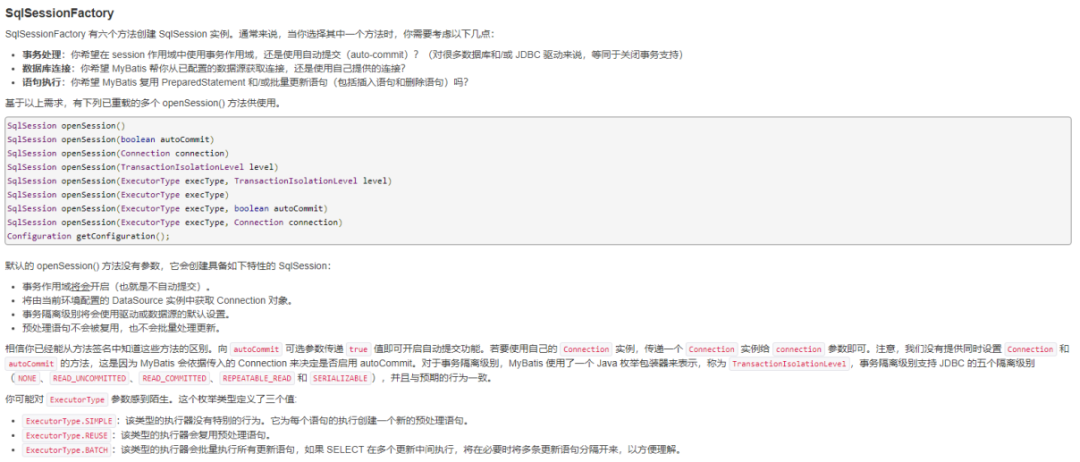
https://mybatis.org/mybatis-3/zh/java-api.html#sqlSessions
mapper就是单条update语句,
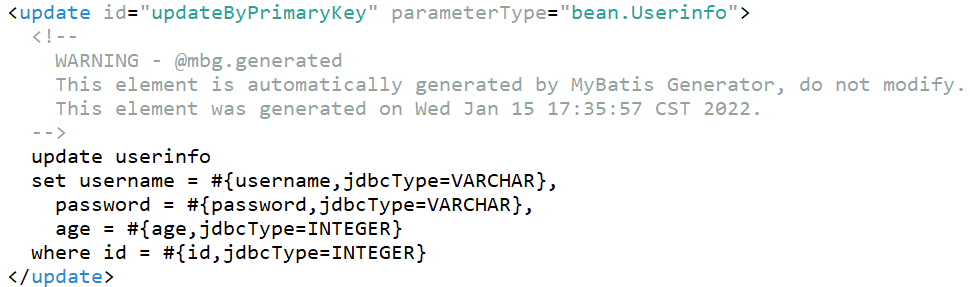
openSession指定了ExecutorType.BATCH,并且设置了1000条更新执行一次提交的逻辑,
P. S. MyBatis工程的构建,可以参考《MyBatis Generator的使用和坑》。
从数据库端看,执行如下SQL,不再出现上万个绑定变量的情况,
UPDATE TEST SET
C1 = :1,
C2 = :2,
C3 = :3,
C4 = :4,
C5 = :5,
C6 = :6,
C7 = :7
WHERE ID = :8 AND ACC = :9;以上才是真正的批量更新操作,从上面的操作,还可知道原始的BEGIN ... END的PL/SQL需要执行所有的update语句才提交一次,不是批量提交,算是一个隐患,这种拼接SQL,只适合小数据量的操作。
有同学讨论说怎么避免这种问题?这就可能有很多路径了,一个是开发规范中可以将这种坑实时更新进来,让设计开发人员有所了解,数据审核平台,则可以从技术层面验证这种“海量”绑定变量的场景,归根结底,这个问题考验的还是设计开发人员对MyBatis以及绑定变量的理解,如果只是会用,在很多场景下,能得到正确结果,但是碰到这种极端的场景,就会进坑。
因此在设计开发过程中,有些环节,还是要知道原理,虽然说殊途同归,但是可能某些路径会消耗更高的成本,或者产生更多的问题,这就要持续积累,持续避坑了。
近期更新的文章:
文章分类和索引:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









