










有一个应用,需要创建索引,创建索引一般有两种方法,一种是
CREATE INDEX ...;一种是
CREATE INDEX ... ONLINE;字面意思上看,一个是在线,一个是非在线,有什么不同?
1.语句执行时间的不同
创建测试表,

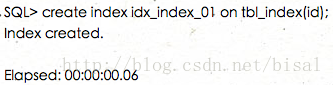
使用非在线创建索引,用时00.06秒,
使用在线方式创建索引,用时00.32秒,
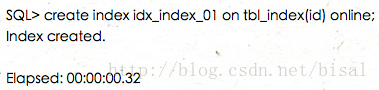
表只有一条数据,ONLINE是非ONLINE用时的5倍以上了。
2.阻塞对象的不同
非在线方式创建索引期间,执行任何DML语句,会hang住,直至索引创建完,
insert into tbl_index select * from tbl_index where rownum=1;
无响应直至索引创建完成出现hang是现象,原理则是锁等待。

从V$LOCKED_OBJECT视图可以了解锁等待信息,使用DBA_OBJECTS视图可以知道,OBJECT_ID是18和168111代表的对象是什么,

在线方式创建索引期间,允许任何DML语句的执行,不会阻塞。但实际从V$LOCKED_OBJECT看,是有一些锁等待信息的,

167111知道是TBL_INDEX表,我们看下168114(此处截图问题请忽略,默认168141就是168114),他代表的对象是SYS_JOURNAL_168113,查看168113代表的对象则是我们创建TBL_INDEX表的索引IDX_TBL_INDEX_01,
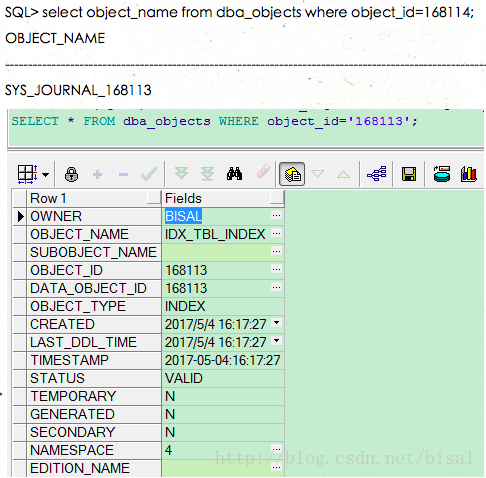
我们看下SYS_JOURNAL_168113,他是一张表,
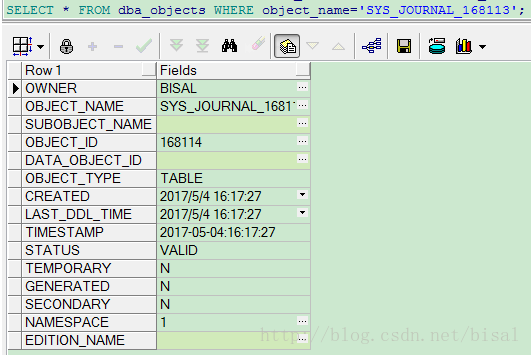
表有四个字段,

记录为空(此处截图问题请忽略,默认168112是168114),
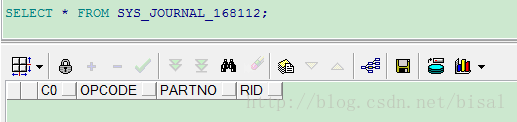
表大小为0,
SELECT SUM(bytes)/1024/1024 FROM dba_segments WHERE segment_name='SYS_JOURNAL_168113';3.执行逻辑的不同
我们对这两种方法执行10046,看下Oracle执行了什么,
(1) 非在线方式的trace主要内容,
首先,我们看见了以SHARE NOWAIT模式LOCK了TBL_INDEX整张表,

向obj$、seg$、icol$、ind$这些数据字典中维护索引相关信息,
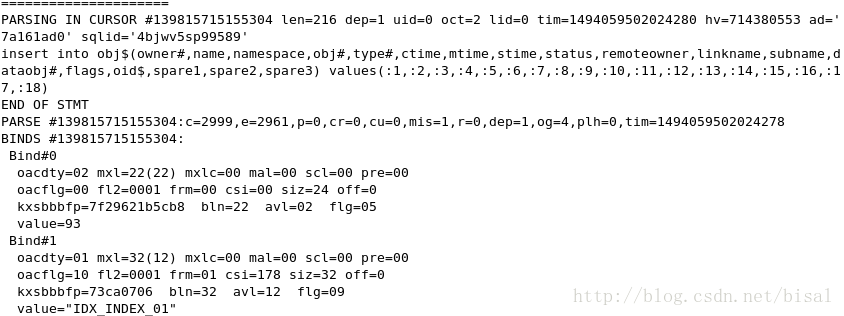
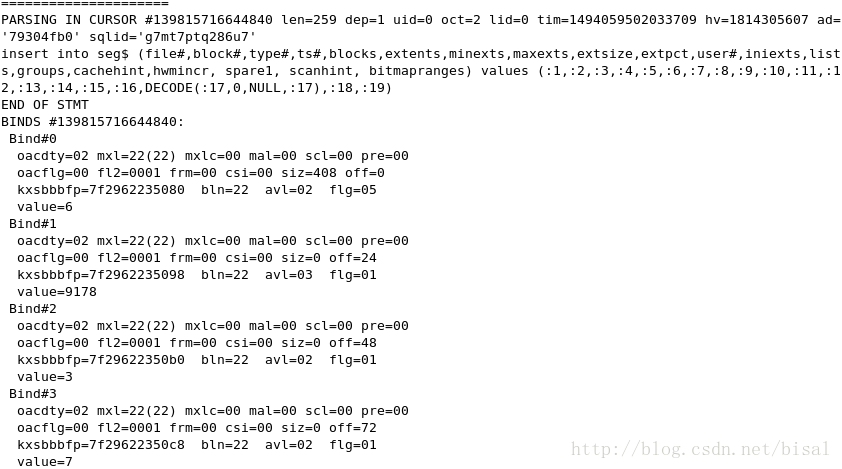



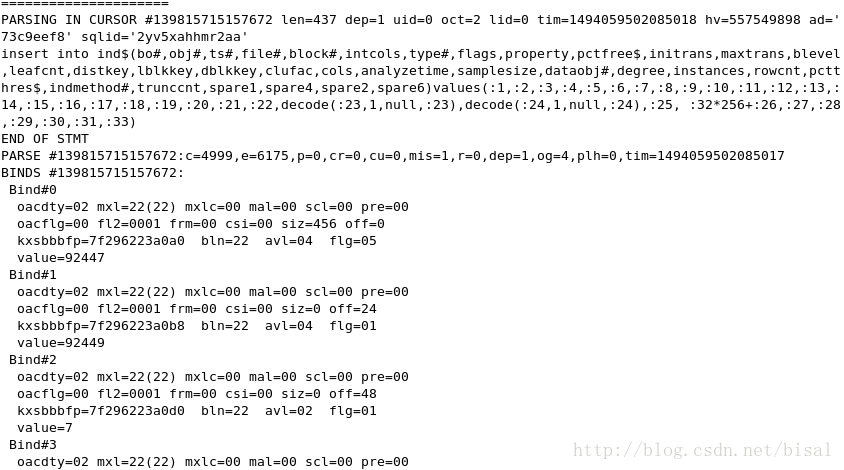
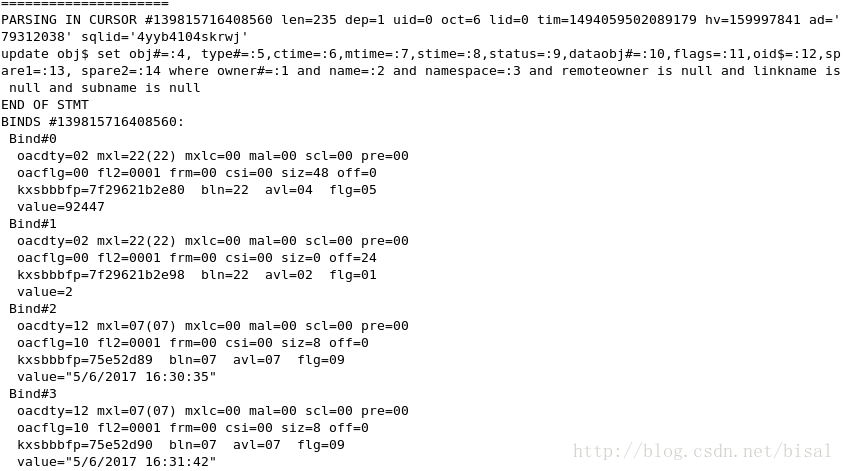
完成非唯一索引的创建,
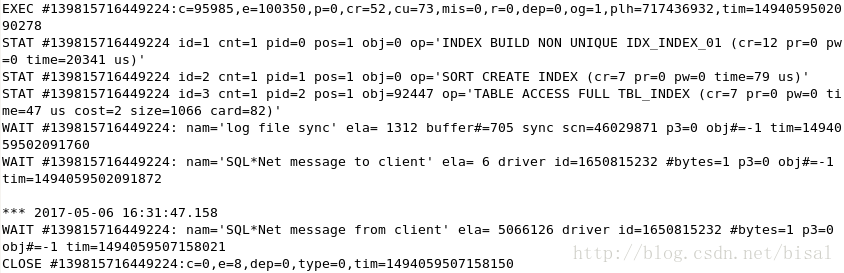
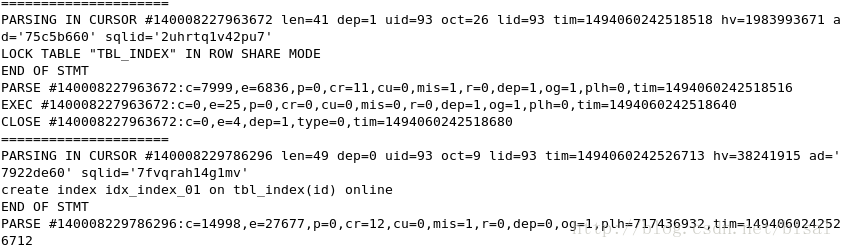
(2) 在线方式的trace主要内容,
首先,以ROW SHARE模式LOCK表TBL_INDEX,这是和非在线方式一点不同,
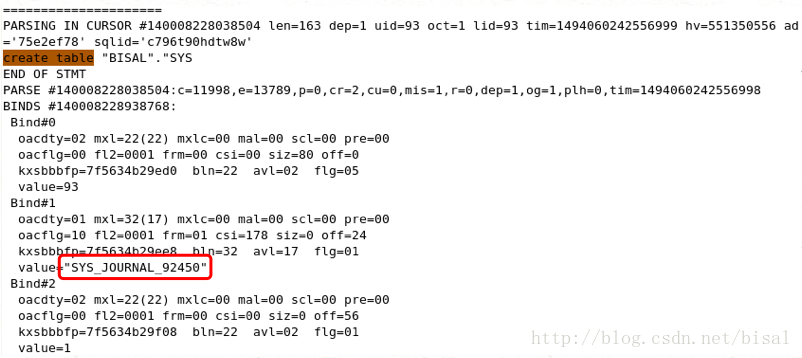
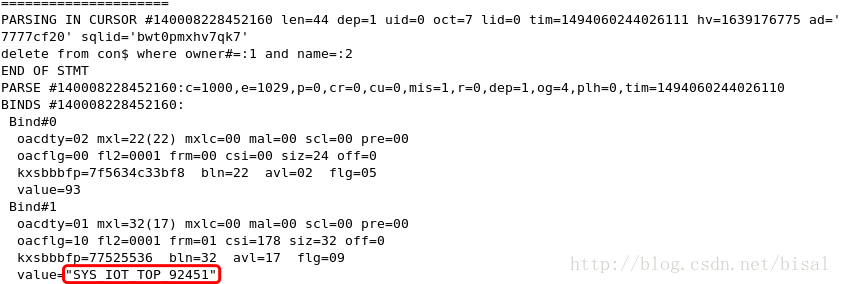
另外的不同,就是会创建一张叫”SYS_JOURNAL_92450”的表,索引创建用的是这张“临时表”,因此不会直接影响原表的DML语句,
这张表用完了,会被drop purge,因此回收站找不着痕迹,

删除一些con$、seg$数据字典的记录,
我们从这两种创建索引生成的trace文件大小也可以得出一些结论,online方式创建索引的trace文件大小是非online方式创建索引的trace文件大小的10倍,说明online方式创建索引要执行更多的工作,尽管不会影响原表的DML语句,因此用时要久一些,

总结:
(1) online和非online方式创建索引,效果相同。
(2) online方式创建索引,由于使用了一张临时表,以ROW SHARE锁表,不会阻塞原表DML的语句,非online方式创建索引,则会以SHARE NOWAIT锁表,阻塞原表DML语句。
(3) 由于online方式创建索引,Oracle执行工作复杂,因此比非online方式创建索引用时要久。
(4) 一句话“不能什么便宜均占着”,要么选择可以快速创建索引的非online方式但创建期间会锁表阻塞DML语句,要么选择不会阻塞原表DML语句的online方式创建索引但用时较久。从实际来看,我理解,若小表选择任何一种均可,大表,尤其是生产系统,找不着非高峰时间,选择online更合理一些,若不关注是否影响DML操作,则两种方式均可以了。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









