







引言:前面我们知道了STL库的容器中的序列式容器包括(vector.list,deque)。还要关联式容器(map,set)。
容器分为三大类:序列式容器,关联式容器,容器适配器(不讲了)。
顺序性容器与关联性容器:
- 顺序性容器 是一种各元素之间有顺序关系的线性表,是一种线性结构的可序群集。顺序性容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。这个位置和元素本身无关,而和操作的时间和地点有关,顺序性容器不会根据元素的特点排序而是直接保存了元素操作时的逻辑顺序。比如我们一次性对一个顺序性容器追加三个元素,这三个元素在容器中的相对位置和追加时的逻辑次序是一致的。
- 关联式容器 和顺序性容器不一样,关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。但是关联式容器提供了另一种根据元素特点排序的功能,这样迭代器就能根据元素的特点“顺序地”获取元素。
关联性容器的有无序:
- 有序容器的底层是红黑树实现的,而红黑树是一种不太严格的AVL平衡搜索二叉树,所以像map,set中存放的数据都是有序排列的。访问速度较慢
- 无序容器的底层是哈希表实现的。哈希表通过把关键码值映射到表中一个位置来访问记录。其存储的内容是无序的。但是访问速度较快。
map与unordered的优缺点:
map:
- 优点:有序性,这是map结构最大的优点,内部实现一个红黑树使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
- 缺点: 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的
unordered_map:
- 优点: 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点: 哈希表的建立比较耗费时间

2.undered_set和set的效率
老说哈希表比红黑树的底层快,到底有多快,上手比较一下就知道了。
#include<iostream> #include<vector> #include<set> #include<time.h> #include<unordered_set> using namespace std; void test_unordered_set() { vector<int> v; v.reserve(10000); srand((unsigned int)time(NULL)); for (int i = 0; i < 10000; i++) { v.push_back(rand()); } //插入 set<int> s; size_t begin1 = clock(); for (auto e : v) { s.insert(e); } size_t end1 = clock(); unordered_set<int> us; size_t begin2 = clock(); for (auto e : v) { us.insert(e); } size_t end2 = clock(); cout << "set insert time:" << end1 - begin1 << endl; cout << "unorder_set insert time:" << end2 - begin2 << endl; //查找 size_t begin3 = clock(); for (auto e : v) { s.find(e);//set自带的查找效率是O(logn) } size_t end3 = clock(); size_t begin4 = clock(); for (auto e : v) { us.find(e); //unordered_set自带的查找,优点:使用哈希特性查找,效率高--O(1) } size_t end4 = clock(); cout << "set find time:" << end3 - begin3 << endl; cout << "unorder_set find time:" << end4 - begin4 << endl; //删除 size_t begin5 = clock(); for (auto e : v) { s.erase(e); } size_t end5 = clock(); size_t begin6 = clock(); for (auto e : v) { us.erase(e); } size_t end6 = clock(); cout << "set erase time:" << end5 - begin5 << endl; cout << "unorder_set erase time:" << end6 - begin6 << endl; } int main() { test_unordered_set(); return 0; }先来10000个数的比较。
再来100000比较一下:
到底快不快,各位细品,我就不说话了。

3.undered_set
3.1特点
- (1) unordered_map是存储<value, value>键值对的关联式容器,对value进行快速索引。
- (2)在unordered_set中,元素的值同时是其键,是唯一标识,键和映射值的类型相同,键不可修改。unordered_set中的元素在容器不可修改,但是可以插入和删除元素。
- (3)在内部,unordered_set中的元素没有按照任何特定的顺序排序,为了能在常数范围内找到指定的key,unordered_set将相同哈希值的键值放在相同的桶中。
- (4)unordered_set比set通过键访问单个元素的速度更快,但它通常在遍历元素子集的范围迭代方面效率较低。
- (5)容器中的迭代器至少有正向迭代器。
3.2三种构造方式
- 1、构造一个空容器
unordered_set<int> us1;
- 2、拷贝构造一个容器
unordered_set<int> us2(us1)
- 3、使用迭代器构造一段区间
string str("Hash") unordered_set<string> us3(str.begin(), str.end());
3.3函数接口
成员函数 功能说明
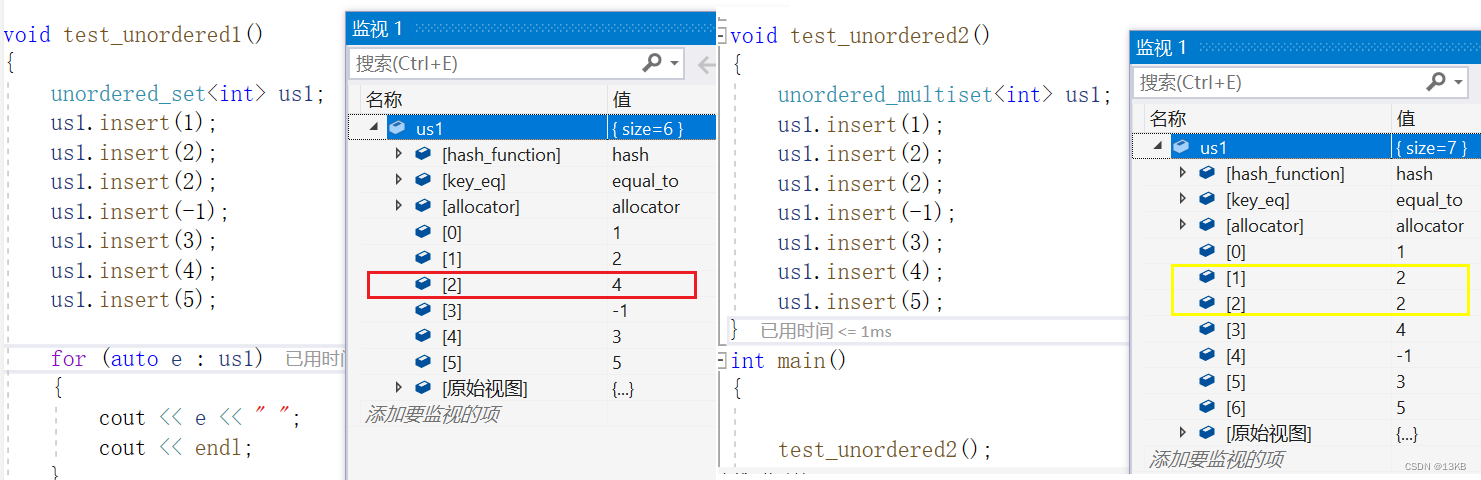
功能说明 begin 获取容器中第一个元素的正向迭代器 end 获取容器中最后一个元素下一个位置的正向迭代器 insert 插入指定数据 erase 删除指定元素 find 查找指定元素 size 获取容器中元素的个数 clear 清空容器 swap 交换两个容器中的数据 count 获取容器中指定元素值的元素个数 void test_unordered1() { unordered_set<int> us1; us1.insert(1); us1.insert(2); us1.insert(-1); us1.insert(3); us1.insert(4); us1.insert(5); for (auto e : us1) { cout << e << " "; cout << endl; } //判空 cout << "容器容量:"<<us1.empty() << endl; //不为空 0 //判断容器当前数据个数 cout << "容器当前数据个数:"<<us1.size() << endl; //5 //求容器当前可存储的最多数据个数 cout << us1.max_size() << endl; //迭代器+查找 unordered_set<int>::iterator it = us1.find(-1); if (it != us1.end()) { cout << "找到了:" << *it << endl; //删除 us1.erase(it); } for (auto e : us1) { cout << e << " "; cout << endl; } //插入区间段 unordered_set<int> us2(us1.begin(),us1.end()); unordered_set<int>::iterator itr = us2.begin(); while (itr != us2.end()) { cout << *itr << endl; itr++; } /*for (auto e : us2) { cout << e << endl; }*/ }
xdm,打印的结果是无序的,可不像set一样是有序的。

3.4延伸(unorder_multiset )
unorder_nultiset和unorder_set其实没啥大的区别,就是它允许简直冗余,如果插入两个相同的数,它会正确打印,但是 unorder_set不行。
find函数的功能略微有点差异:
unordered_set对象 返回值为key的元素的迭代器位置 unordered_multiset对象 返回底层哈希表中的第一个值为key的元素的迭代器
4. unordered_map
4.1特点
map知道不?对,这个跟他有关系但是关系不多。这个也是无序的。
- 1、unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 2、在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 3、在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- 4、unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- 5、unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问value。
- 6、它的迭代器至少是前向迭代器。
4.2函数构造
map咋构造它咋构造。
- 1、构造一个空容器:
unordered_map<string, int> mp1;
- 2、拷贝构造一个容器:
unordered_map<string, int> mp2(mp1);
- 3、使用迭代器区间构造一个容器:
unordered_map<string, int> mp2(mp1.begin(), mp1.end());
4.3相关函数接口
功能我就不在一一讲解了,兄弟们自行到官网去查吧,直接上代码。
头文件#include<unordered_map>
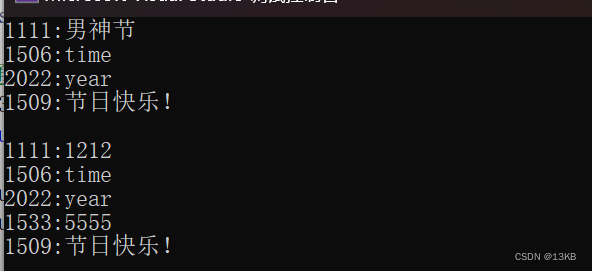
void test_unordered_map() { unordered_map<int, string> mp1; pair<int, string> kv(1111, "男神节"); //5种插入方法 mp1.insert(kv); mp1.insert(pair<int, string>(1506, "time")); mp1.insert(make_pair(2022, "year")); mp1[2222] = "csdn"; //map就有用[]访问 mp1.insert({ 1509,"节日快乐!" }); for (auto e : mp1) { cout << e.first << " "; cout << endl; } unordered_map<int, string>::iterator it = mp1.begin(); while (it != mp1.end()) { cout << it->first << ":" << it->second << " "; it++; } cout << endl; //1111:男神节 1506:time 2022:year 2222:csdn 1509:节日快乐! //2:范围for for (auto e : mp1) { cout << e.first << ":" << e.second << " "; } cout << endl; //1111:男神节 1506 : time 2022 : year 2222 : csdn 1509 : 节日快乐! }
祝兄弟们节日快乐!
void test_unordered_map2() { unordered_map<int, string> mp1; pair<int, string> kv(1111, "男神节"); mp1.insert(kv); mp1.insert(pair<int, string>(1506, "time")); mp1.insert(make_pair(2022, "year")); mp1[2222] = "csdn"; //map就有用[]访问 mp1.insert({ 1509,"节日快乐!" }); //1:根据key删除 mp1.erase(4); //2:根据迭代器位置删除 unordered_map<int, string>::iterator pos = mp1.find(2222); if (pos != mp1.end()) { mp1.erase(pos); } for (auto e : mp1) { cout << e.first << ":" << e.second << " "; cout << endl; } cout << endl;//1:one 3:three 5:five /*修改*/ //1:通过迭代器位置修改 pos = mp1.find(1111); if (pos != mp1.end()) { pos->second = "1212"; } //2:通过[]修改 mp1[1533] = "5555"; for (auto e : mp1) { cout << e.first << ":" << e.second << " "; cout << endl; } cout << endl;//1:one 3:Ⅲ 5:Ⅴ }
4.4延伸(unordered_multimap)
unordered_multimap跟unordered_map的区别也不是很大,前者能存储重复的数据,后者不行,在一些函数接口上会有一些不同,这个参考前的multimapjike。















 3163
3163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









