









2020/2/17
最近电脑坏掉了,可怜我刚买三个月的小新pro13啊,显示屏出了问题。不知道哪里坏掉了,打开黑屏,只有显示屏在某个特殊的角度才会显示亮(其他的角度其实是最暗的亮度,趴在上面能模模糊糊的看到轮廓,蜜汁问题),最骚的是我用一个比较重的东西压住电脑的左下角也就是我左手的位置的话,就显示的比较正常,???真搞不懂什么问题,不过今后对联想的电脑敬而远之吧。最近因为疫情,联想售后还不开门,香菇。
好,说了一大堆纯属发泄学习过程中的牢骚,这个电脑让我太难了。
刚把爬虫开发实战爬取今日头条图片的代码完成,发现网站有些变化,也就是书里的代码会无法爬取。主要有两个变化,1)模仿ajax请求爬取图片需要cookie;2)返回的json内容有所变化,并没有image_detail字段。下面是具体内容
1)添加cookie
cookie可以在街拍网页的第一个xhr请求中得到
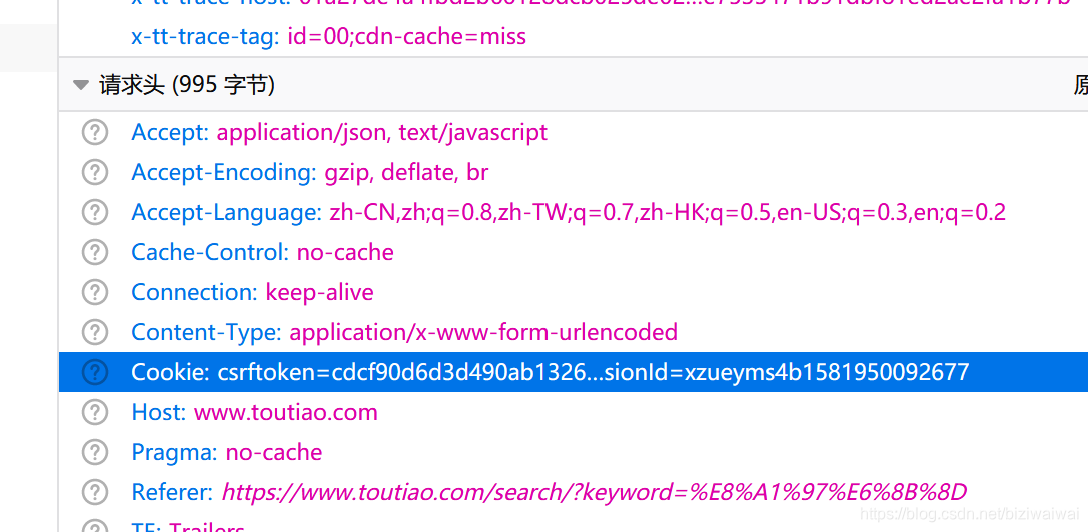 而且,在第一个xhr请求之前可以看到有一个img请求的响应字段中设置了该cookie,而且过期时间很长,过期了再访问一次复制一下cookie就可以了。
而且,在第一个xhr请求之前可以看到有一个img请求的响应字段中设置了该cookie,而且过期时间很长,过期了再访问一次复制一下cookie就可以了。
所以,加上cookie之后的headers设置如下。
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Referer":"https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D",
"X-Requested-With":"XMLHttpRequest",
"Cookie":"__tasessionId=da6dc6d4q1581851848391; s_v_web_id=k6oxqyas_VGn20UCx_WXjQ_40eQ_9nhD_h0a5HUmjAsyD; csrftoken=cdcf90d6d3d490ab1326e261b2eff18a; tt_webid=6794001919121065486"
}
2)返回的json内容的格式发生了变化
在data中没有image_detail字段,有一个image_list字段,而且data中也不是每一个都有image_list字段
具体代码:
代码部分分为了三个部分,main函数;get_one_page函数:获取某个offset范围的json数据,并返回,这是一个生成器,可以在main中遍历;save_img函数:从生成器中得到img的url信息并保存
import requests, json, time,os
from lxml import etree
from requests import RequestException
from hashlib import md5
base_url1 = "https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset="
base_url2 = "&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp="
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0",
"Referer":"https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D",
"X-Requested-With":"XMLHttpRequest",
"Cookie":"__tasessionId=da6dc6d4q1581851848391; s_v_web_id=k6oxqyas_VGn20UCx_WXjQ_40eQ_9nhD_h0a5HUmjAsyD; csrftoken=cdcf90d6d3d490ab1326e261b2eff18a; tt_webid=6794001919121065486"
}
base_save_path = "D:/toutiao/"
def get_one_page(base_url:str)->dict:
'''
@base_url: request url
@return: nop
'''
try:
resp = requests.get(base_url, headers = headers)
except RequestException:
return None
json_content = resp.json()
print(base_url, '\n')
# print(json.dumps(json_content, indent=2, ensure_ascii=False))
data = json_content.get("data")
for item in data:
title = item.get("title")
imgs = item.get("image_list")
if (imgs):
title_img = {}
title_img["title"] = title
title_img["image_list"] = imgs
yield title_img
else:
continue
def save_img(title_img: dict):
title = title_img.get("title")
title_path = base_save_path +title
if not os.path.exists(title_path):
os.mkdir(title_path)
for img in title_img.get("image_list"):
img_url = img.get("url")
img_resp = requests.get(img_url)
if img_resp.status_code == 200:
file_path = '{0}{1}.{2}'.format(title_path + '/', md5(img_resp.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as img_f:
img_f.write(img_resp.content)
else:
print("already downloaded :", file_path)
def main():
for i in range(0, 120, 20):
base_url = base_url1 + str(i) + base_url2 + str(time.time()).replace('.','')[:-4]
title_imgs = get_one_page(base_url)
for title_img in title_imgs:
save_img(title_img)
time.sleep(1)
if __name__ == "__main__":
main()














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









