







并查集的应用场景与优势
1.处理对象:Disjoint Set,即“不相交集合”。
在一些应用问题中,需将n个不同的元素划分成一组不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定顺序将属于同一组元素的集合合并。其间要反复用到查询某个元素属于哪个集合的运算。适合于描述这类问题的抽象数据类型称为并查集。
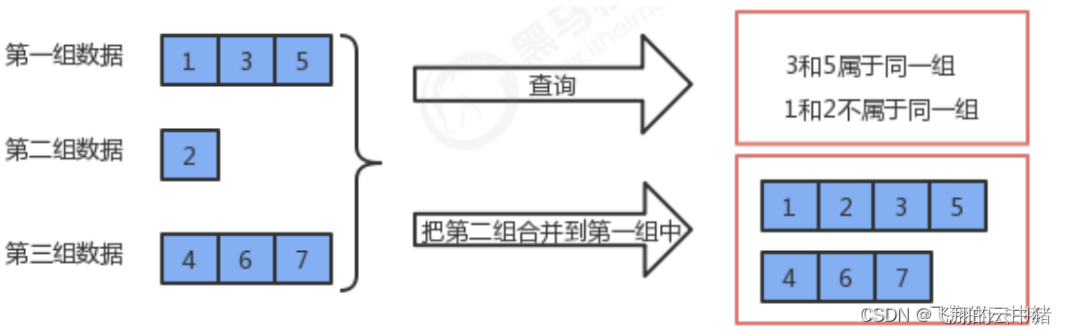
2.并查集(Union-Find Set)是一种高效解决
(1)将两个元素所在的集合合并
(2)查询元素处在哪个集合的数据结构

一.并查集结构
并查集是一种树型结构,这种树的要求比较简单:
1.每个元素都唯一的对应一个结点;
2.每一组数据中的多个元素都在同一颗树中;
3.一个组中的数据对应的树和另外一个组中的数据对应的树之间没有任何联系;
4.元素在树中并没有子父级关系的硬性要求。
简单说就是同一组的元素可以看成是一棵树。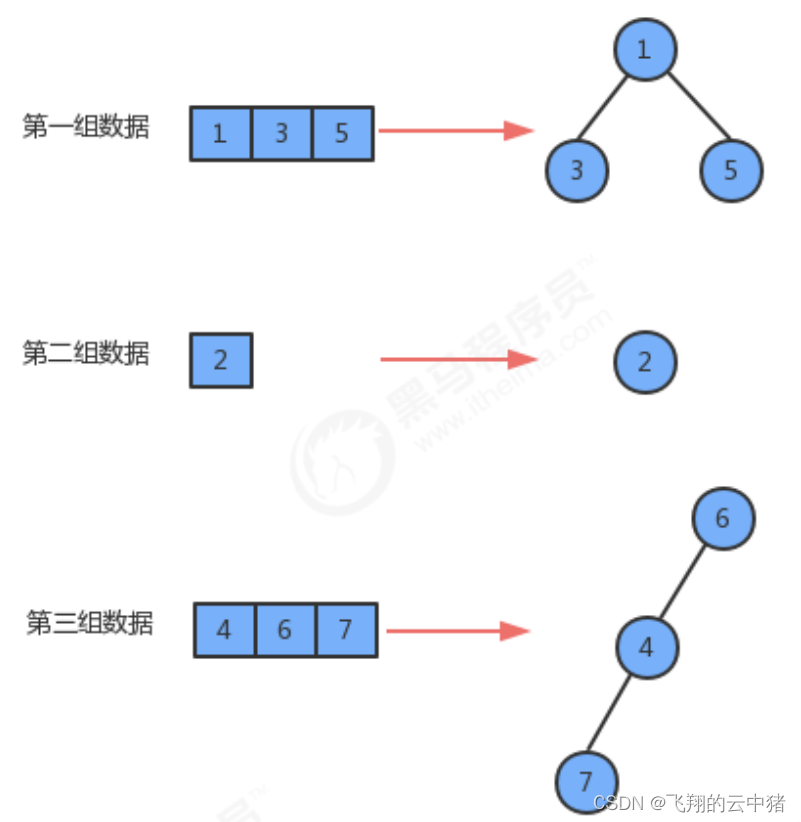
二.并查集主要功能
初始化(init),查询(find),合并(union)
三.并查集的实现
初始化,查询与合并


四.查找算法的优化--路径压缩
思考:上面查找的图,从4开始向上查找,当这颗树非常长的时候,是不是就要运算很多次?而且合并算法也要用到查找算法,所以当树/路径很长,就会导致查找算法和合并算法的复杂度很高。
我们可以考虑在查找的同时将查找元素直接指向最顶的父节点。
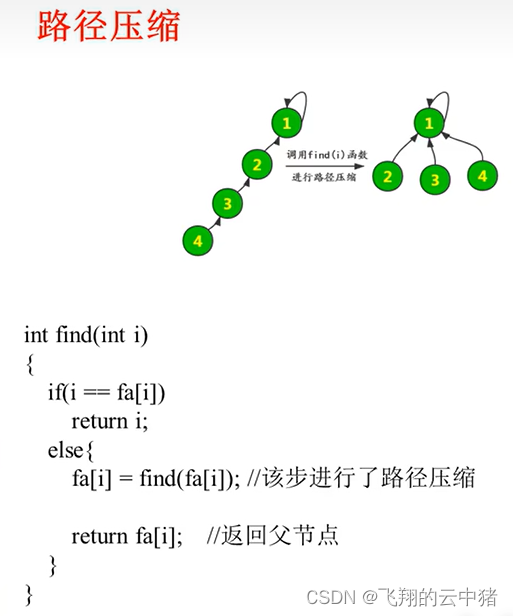
封装后的结构体(考试可以直接用):
#include<iostream>
#include<vector>
using namespace std;
struct League {
vector<int> fa;
int count=0;
void init(int n) {
fa.resize(n);
for(int i=0;i<n;i++){
fa[i]=i;
}
count=n;
}
int find(int i) {
if(fa[i]==i)
return i;
else {
fa[i]=find(fa[i]);
return fa[i];
}
}
void unionn(int i,int j) {
int i_fa=find(i);
int j_fa=find(j);
if(i_fa!=j_fa) {
fa[i_fa]=j_fa;
count--;
}
}
};















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









