






三维数据集,其中包含来自两个类的数据点,每个类包含1000个点,在图中表示为“+”和“o”类,添加一个噪声属性Z,服从[0,20]之间的均匀分布
plt.figure(figsize=(10,8))
#'+'类
#高斯分布数据点
#“+”类中,5000个实例的生成服从二元高斯分布
mean1 = [5,15]#中心值
cov1 = [[1,0.0],[0.0,1]]#协方差矩阵
gdata1 = np.random.multivariate_normal(mean1,cov1,500)
plt.plot(gdata1[:,0],gdata1[:,1],'+',c='blue')
mean2 = [15,5]#中心值
cov2 = [[1,0.0],[0.0,1]]#协方差矩阵
gdata2 = np.random.multivariate_normal(mean2,cov2,500)
plt.plot(gdata2[:,0],gdata2[:,1],'+',c='blue')
#'o'类
mean3 = [15,15]#中心值
cov3 = [[1,0.0],[0.0,1]]#协方差矩阵
gdata3 = np.random.multivariate_normal(mean3,cov3,500)
plt.plot(gdata3[:,0],gdata3[:,1],'o',c='red',markerfacecolor='white')#空心点绘制
mean4 = [5,5]#中心值
cov4 = [[1,0.0],[0.0,1]]#协方差矩阵
gdata4 = np.random.multivariate_normal(mean4,cov4,500)
plt.plot(gdata4[:,0],gdata4[:,1],'o',c='red',markerfacecolor='white')
x=range(0,21,2)
y=range(0,21,2)
plt.xticks(x)#重新划分x轴坐标刻度
plt.yticks(y)#重新划分y轴坐标刻度
plt.show()
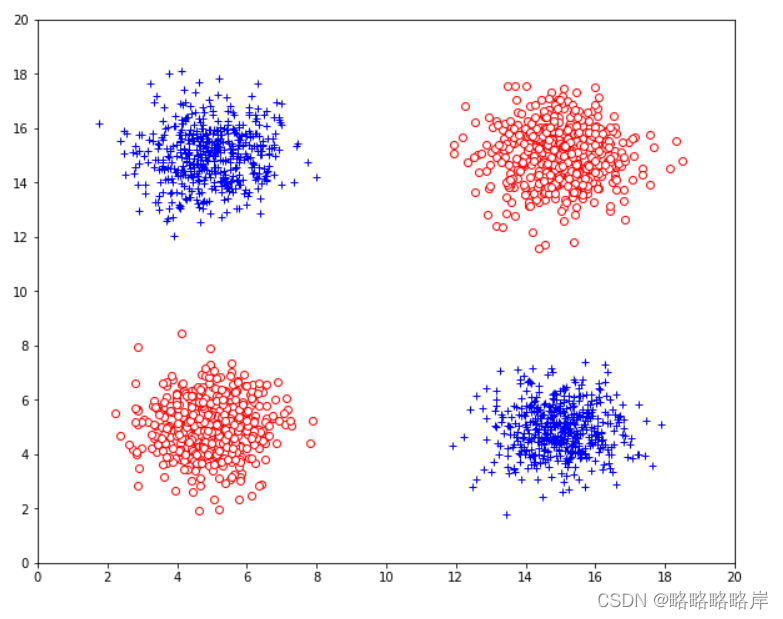
添加一个噪声属性Z,服从[0,20]之间的均匀分布
z1=np.random.uniform(0,20,2000)#获取开始值0和结束值20作为参数,返回一个浮点型的随机数
#plt.plot(z1,'o',MarkerSize=5,color='red',markerfacecolor='white') # 绘制散点图,面积随机
print(z1)
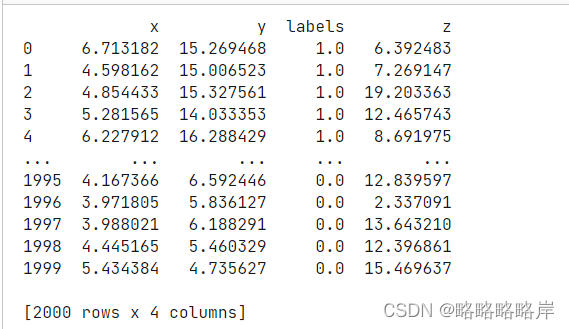
高斯分布中‘+’,‘o’两类数据进行的合并转换格式,最后添加Z噪声该列,构成一组三维数据集
from pandas.core.frame import DataFrame
label1=[]
for i in range(500):
i=1
label1.append(i)
A=[gdata1[:,0],gdata1[:,1],label1]
#print('x1数据',y1)
label2=[]
for i in range(500):
i=1
label2.append(i)
B=[gdata2[:,0],gdata2[:,1],label2]
label3=[]
for i in range(500):
i=0
label3.append(i)
C=[gdata3[:,0],gdata3[:,1],label3]
label4=[]
for i in range(500):
i=0
label4.append(i)
D=[gdata4[:,0],gdata4[:,1],label4]
#将其4个高斯分布的数据转化成dataframe格式
data_1 = DataFrame(A).T
data_2 = DataFrame(B).T
data_3 = DataFrame(C).T
data_4 = DataFrame(D).T
#合并以上四组数据
frames=[data_1,data_2,data_3,data_4]
data=pd.concat(frames)
#将列名改成x1和x2,labels标签
data.columns = ['x','y','labels']
data = data.reset_index(drop = True)#将这个index重新排列
#data中添加一列Z的噪声数据
data['z']=z1
print(data)
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
#划分数据
X=data[['x','y','z']].values#将DataFrame的特定列x,y转换为ndarray
y=data['labels'].values
X_train, X_test, Y_train, Y_test = train_test_split(X,y,test_size=0.9,random_state=0,shuffle=True)
##决策树
scores_test = []
scores_train=[]
for i in range(2,15) :#限制最大叶子节点数
##### 训练模型
dtcf = DecisionTreeClassifier( criterion='entropy', max_leaf_nodes=i)
# criterion 选entropy---信息熵
dtcf.fit(X_train, Y_train)
#获取训练误差
score_test = dtcf.score(X_test, Y_test)
score_train = dtcf.score(X_train, Y_train)
scores_test.append(1-score_test)
scores_train.append(1-score_train)
plt.figure(figsize=(10,10))
#绘制折线图
plt.plot(range(13), scores_test,'-o',MarkerSize=3,color='red',label='Test Error')#修改符号大小粗细
plt.plot(range(13), scores_train,'-o',MarkerSize=3,color='blue',label='Train Error')#修改符号大小粗细
plt.xlabel('Nodes')
plt.ylabel('Errors')
plt.title('10%train-90%test')
plt.ylim([0,1])#设置了x,y轴的范围
plt.legend()
plt.show()
可是化三维
#可视化3D
from mpl_toolkits.mplot3d import Axes3D
fig=plt.figure(figsize=(10, 10))
ax =fig.gca(projection='3d')
#分别绘制‘o’,‘+’两类的三维分布
ax.scatter3D(X1[:,0],X1[:,1],X1[:,2],'+',c='blue', s=40,marker='+')
#绘制空心点,edgecolors是控制圆圈的边缘颜色,c为白色
ax.scatter3D(X2[:,0],X2[:,1],X2[:,2],'o',c='white',edgecolors='r', s=40,marker='o')
plt.grid(linewidth=6,linestyle='-')
#设置坐标轴
ax.set_xlabel('X ')
ax.set_ylabel('Y ')
ax.set_zlabel('Z ')
plt.grid(linestyle=':')
plt.show()

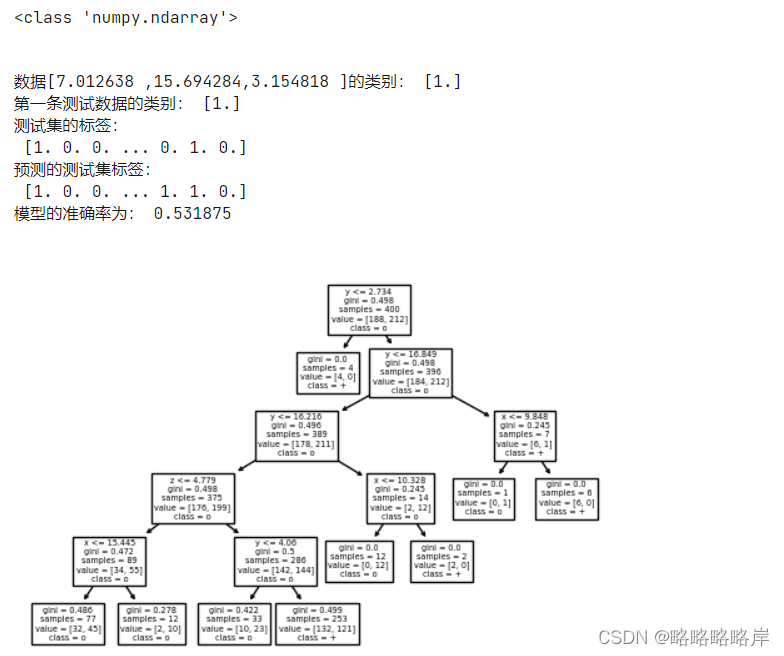
决策树分类,验证Z是否可能被划分为属性
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
X=data[['x','y','z']].values#将DataFrame的特定列x,y转换为ndarray
y=data['labels'].values
X_train, X_test, Y_train, Y_test = train_test_split(X,y,test_size=0.8,random_state=0,shuffle=True)
print(type(X_test))
clf = DecisionTreeClassifier( max_depth=5)#创建决策树模型,criterion属性缺省为‘gini',基尼系数 数据维度很大,噪音很大时使用
clf.fit(X_train, Y_train) #拟合模型
plt.figure(dpi=100)
feature_names=['x','y','z']
target_names=['+','o']
tree.plot_tree(clf,feature_names=feature_names,class_names=target_names) #feature_names属性设置决策树中显示的特征名称
plt.show()
# Predict for 1 observation
print('数据[7.012638 ,15.694284,3.154818 ]的类别:',clf.predict([[7.012638 ,15.694284,3.154818 ]]))
print('第一条测试数据的类别:',clf.predict(X_test[0].reshape(1,-1)))
# Predict for multiple observations
print('测试集的标签:\n',Y_test)
Y_pre=clf.predict(X_test)
print('预测的测试集标签:\n',Y_pre)
# The score method returns the accuracy of the model
#(正确预测的分数):正确预测/数据点总数
print('模型的准确率为:',clf.score(X_test,Y_test))
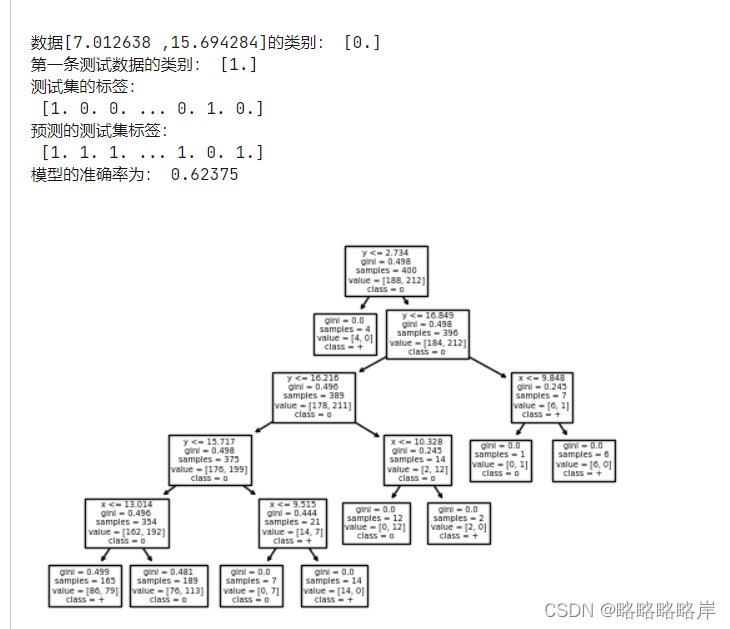
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
X4=data[['x','y']].values#将DataFrame的特定列x,y转换为ndarray
y4=data['labels'].values
X_train_4, X_test_4, Y_train_4, Y_test_4 = train_test_split(X4,y4,test_size=0.8,random_state=0,shuffle=True)
print(type(X_test))
clf = DecisionTreeClassifier( max_depth=5)#创建决策树模型,criterion属性缺省为‘gini'
clf.fit(X_train_4, Y_train_4) #拟合模型
plt.figure(dpi=100)
feature_names=['x','y']
target_names=['+','o']
tree.plot_tree(clf,feature_names=feature_names,class_names=target_names) #feature_names属性设置决策树中显示的特征名称
plt.show()
# Predict for 1 observation
print('数据[7.012638 ,15.694284]的类别:',clf.predict([[7.012638 ,15.694284]]))
print('第一条测试数据的类别:',clf.predict(X_test_4[0].reshape(1,-1)))
# Predict for multiple observations
print('测试集的标签:\n',Y_test_4)
Y_pre_4=clf.predict(X_test_4)
print('预测的测试集标签:\n',Y_pre_4)
# The score method returns the accuracy of the model
#(正确预测的分数):正确预测/数据点总数
print('模型的准确率为:',clf.score(X_test_4,Y_test_4))
总结:
第一个模型中Z可以被划分为属性,它作为一个叶
子节点,进行分枝并且Z被划分为属性的模型的准确率0.531低于未被划分模型(无躁)的准确率0.623,与正常数据一起影响训练集的分布,此模型去预测从正常数据分上取的未知数据,就很有可能得到不理想的泛化效果。














 1289
1289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









