







近期与人谈论起数据库索引时,发现记忆中很多概念已经变的模糊不清了,因此特意重新查阅了相关资料,正好做一下整理。对于索引的一个经典比喻应该是大家都耳熟能祥的字典目录了。MySql内的数据就是字典的正文内容,而索引就是前面的目录。当你要查找某一个字时,如果没有目录,很有可能需要遍历字典的每一页(暂且忽视二分查找 ),这样的效率可想而知。而通过遍历目录,则能很快的定位到字所在的页码,正如索引能够为你指出你所需要的数据存储在何处。如果数据库规模很小,即使没有索引,也可以有很好的性能,正如一片十几页的论文不需要目录一样。
B-Tree索引
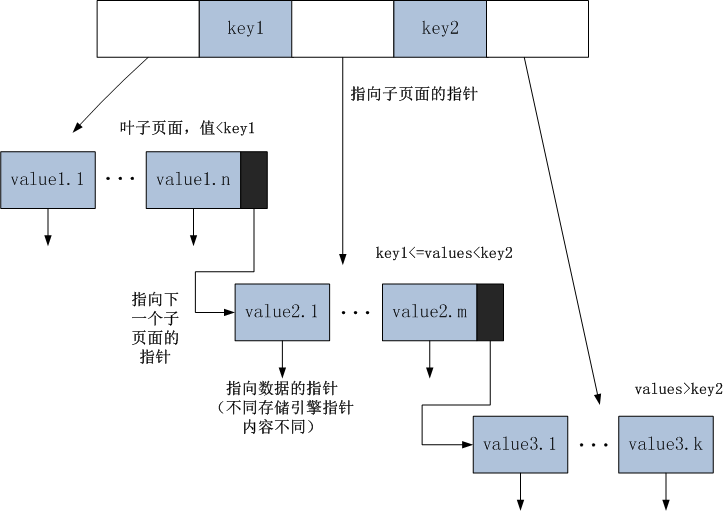
通过B-Tree索引的数据结构我们可以看出,其能够很好的用于以下类型的查找:
1. 全键值匹配:指查询条件与索引中的所有列匹配
2.匹配最左前缀:如果索引为(a,b,c),B-Tree索引可以很好的找到所有a=1的数据,但这仅使用与索引中的第一列(或前N列)
3.匹配列前缀。可以匹配某列的值的开头部分,若上述索引中的a为人名,则可以很快找到所以已A开头的名字的列。并且这也只会使用索引的第一列
4.匹配范围值。可以很快的找到 a>3且a<8的数据。这也只会使用索引的第一列
5.精确匹配一部分并且匹配某个范围中的另一部分。如a=2且3<b<8。记住精确匹配的部分必须在最左,范围匹配的部分必须在除了精确匹配的部分的最左。如a=2且3<c<8就无法快速查找
6.只访问索引的查询。即“覆盖索引“,索引包括了查询所需的所有列,因此不要查找数据行
同理我们也可以看出B-Tree索引的一些局限:
1. 如果查找没有从索引列的最左边开始,它就没有什么用处
2. 不能跳过索引中的列。如查找a=1且c=1的数据,此时只能使用索引的第一列
3. 存储殷勤不能优化访问任何在第一个范围条件右边的列。如查找a=1且b>3且c=4,,就只能使用索引的头两列,因为b用的是范围条件
由此可以看出列顺序是极为重要的:这些局限都和列顺序有关。对于 高性能应用程序,也许要针对相同列以不同顺序创建多个索引,以满足不同需求。
InnoDB VS. MyISAM
如前所述,mysql索引是在存储引擎层实现的,而不是在服务层,不同的存储引擎使用了不同的方将索引保存在磁盘。例如,MyISAM使用前缀压缩(Prefix Compression)以减小索引,而InnoDB不会压缩索引,因为它不能把压缩索引用于某些优化。同样,MyISAM索引按照存储的物理位置引用被索引的行,但InnoDB按照主键值引用行,即InnoDB采用了聚集索引。当表有聚集索引的时候,它的数据行实际保存在索引的叶子页面中。”聚集“的一次是指实际的数据行和相关的键值都保存在一起。每个表只能有一个聚集索引,因为不能一次把行保存在两个地方(需要注意的是,覆盖索引可以模拟多个聚集索引)。叶子页面包含了行的全部数据,但是节点页只包含有被索引的列。
InnoDB按照主键进行聚集,上面的图中的”key“其实是主键列。如果没有定义主键,InnoDB会使者使用唯一的非空索引来代替。若没有这种索引,InnoDB就会定义隐藏的主键然后在上面聚集。InnoDB只聚集在同一页面中的记录。包含相邻键值的页面也许会相距甚远。
下图展示了InnoDB和MyISAM的叶子节点分别是如何组织的: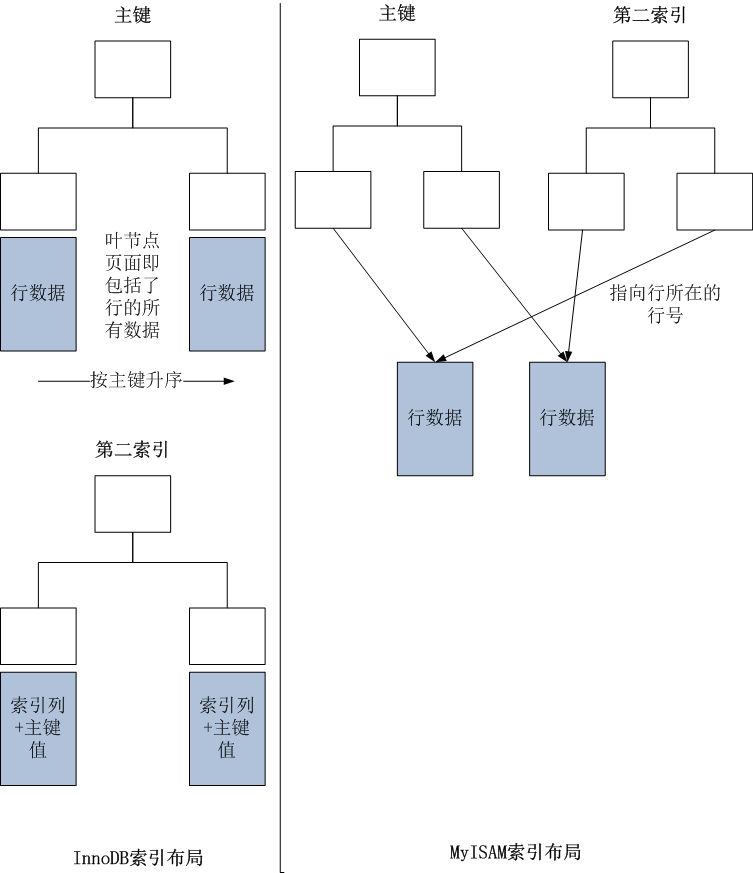
MyIsam按照插入的顺序把值保存在了磁盘上。MyISAM一般使用行号表示每一行,对主键索引中的每个叶子节点包含了行号;对于第二索引也一样。事实上MyISAM中主键和其他索引没什么结构上的区别。主键只是一个唯一的,名为PRIMARY的非空索引。而由于InnoDB支持聚集索引,因此它以很不一样的方式保存相同的数据。对于主键上的索引,其索引显示了整个表,其每个索引中的叶子节点都包含了主键以及剩下的列。
同时,InnoDB的第二索引和聚集索引很不一样。InnoDB的第二索引叶子节点包含了主键值作为指向行的“指针”,而不是“行指针“,即以主键的值作为查找行数据的指针。这种策略减少了在移动行货数据分页时候索引的维护工作,当InnoDB移动行时,无需更新索引叶节点上的指针。但同时也会产生如下两种效果:1.第二(非聚集)索引可能会比预想的大,因为他们的叶子节点包含了被引用行的主键列。2.第二索引访问需要两次索引查找。由于第二索引保存了主键值,因此存储引擎首先需要通过第二索引找到主键值,然后再根据主键值在聚集索引上找到最终的数据行。不过对于InnoDB来说,自适应哈希索引可以减少这种性能上的损失。(当InnoDB注意到一些索引被很频繁地方位时,它会在B-Tree的顶端为这些值建立起内存中的索引,以进行很快的哈希查找。这个过程是全自动的,无法被 控制、配置。)















 463
463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









