






目录
观看本文之前,可以先去了解一下:响应式宣言
本文会从传统的Web应用模型开始讲解,针对传统应用产生的问题进行改进和分析,逐步引入到响应式编程模型,使大家能更清楚的理解:为什么使用响应式编程?响应式编程是什么?响应式编程怎么使用?
以下内容以web应用作为例,同一个接口在同时可能会有多个请求进入。
传统模型的原理与弊端
传统方式是一种同步阻塞式的模型,用户发送请求之后,会以线性的方式进行业务操作,然后再返回结果。
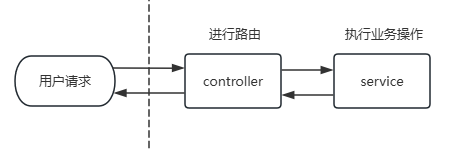
在这种模型当中,往往service层会有很多的阻塞操作,例如:数据库操作、网络请求、文件操作,线程必须等待阻塞操作执行完毕才能往下执行。
如果与此同时有另一个用户访问该系统,则会通过servlet容器(例如Tomcat)再分配一个线程进行单独的处理,这种处理方式我们称作:one-request-per-thread model,字面意思是一个请求分发一个线程进行处理。这样能使得并发的用户都能够及时得到响应。
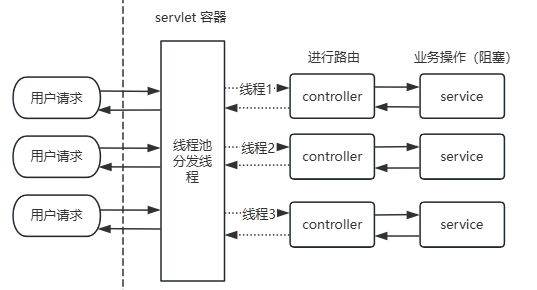
这种模型有什么弊端呢?当并发用户过多的时候,则会有多个线程处于阻塞状态,每个线程占用一份资源(数据库资源、文件资源),所以我们的系统将维护大量的线程,大量的线程就会有很大的开销:创建线程会有内存开销,线程会轮换在CPU上执行,线程切换会有调度开销。每个线程的执行时间没有发生变化,所以系统能同时处理的请求数量依然很大程度上受限。
同时,Tomcat的线程池大小决定了可以同时处理多少个请求。
传统模型的改进与弊端
传统模型的问题关键点还是在于会有阻塞操作的发生,如果减少阻塞操作,每个线程都能更快返回数据,则不会有大量请求同时等待的情况。
改进方式是:我们可以使用异步的方式进行阻塞操作,假设一个线程遇到阻塞之后,我们不要让线程等,我们可以采用异步的方式执行,异步操作结束之后进行获取结果或者回调某个方法。
这里采用Java的CompletableFuture进行举例:左边是传统模型的执行方式,可以看到一个业务的发生可能会伴随多个阻塞操作,极大的影响了程序执行的性能,改进为CompletableFuture的执行方式之后,当阻塞操作发生的时候,依然可以执行其他操作(阻塞操作2)。
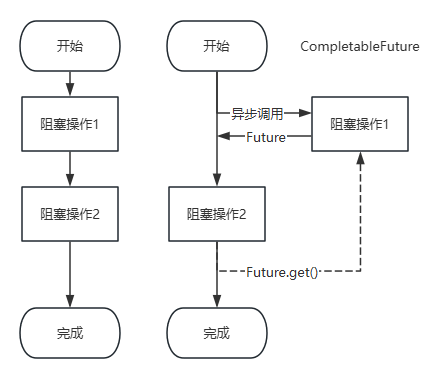
这种方式能减少业务的执行时间:
- 传统方式执行时间 = 阻塞1 + 阻塞 2 ;
- 改进方式执行时间 = MAX(阻塞1 + 阻塞2);
单次业务执行时间降低,则系统能同时处理的请求数量会增加,下面我会举一个代码例子,分别使用同步和异步的方式实现某个业务,假设我们有一个业务需要查询订单详情和状态,同步的方式是:首先查询订单ID,然后根据订单ID查询订单详情和订单状态,然后再进行合并输出结果。
// 1. 阻塞获取订单ID列表
List<String> orderIds = fetchOrderIds();
// 2. 顺序处理每个订单
List<String> allOrderInfo = new ArrayList<>();
for (String orderId : orderIds) {
// 阻塞获取订单详情和状态
String details = fetchOrderDetails(orderId);
String status = fetchOrderStatus(orderId);
// 合并结果
String combined = String.format(
"Order ID %s: Details=%s, Status=%s",
orderId, details, status
);
allOrderInfo.add(combined);
}
// 3. 输出结果
System.out.println("Processed orders: " + allOrderInfo);当采用CompletableFuture的异步方式时,异步获取订单id,获取订单详情和订单状态的异步操作依赖获取订单id的操作。(代码不需要完全看懂,观察大致操作流程即可)
// 1. 异步获取订单ID列表
CompletableFuture<List<String>> orderIdsFuture = fetchOrderIds();
// 2. 处理每个订单ID的异步任务链
CompletableFuture<List<String>> resultFuture = orderIdsFuture.thenComposeAsync(orderIds -> {
// 为每个订单ID生成并行的异步任务流
List<CompletableFuture<String>> taskList = orderIds
.stream()
.map(orderId -> {
// 异步获取订单详情(例如从数据库或外部API)
CompletableFuture<String> detailsFuture = fetchOrderDetails(orderId);
// 异步获取订单状态(例如从另一个服务)
CompletableFuture<String> statusFuture = fetchOrderStatus(orderId);
// 合并两个异步任务的结果
return detailsFuture.thenCombineAsync(statusFuture,
(details, status) -> String.format(
"Order ID %s: Details=%s, Status=%s"
, orderId, details, status)
);
}).toList();
// 将任务流转换为数组以便批量等待
@SuppressWarnings("unchecked")
CompletableFuture<String>[] taskArray = taskList.toArray(new CompletableFuture[0]);
// 等待所有订单任务完成
CompletableFuture<Void> allTasksDone = CompletableFuture.allOf(taskArray);
// 所有任务完成后,提取每个任务的结果并汇总为列表
return allTasksDone.thenApply(v ->
taskList.stream()
.map(CompletableFuture::join) // 此时join不会阻塞,因为任务已全部完成
.collect(Collectors.toList())
);
});
// 3. 阻塞主线程等待最终结果
List<String> allOrderInfo = resultFuture.join();
System.out.println("Processed orders: " + allOrderInfo);这种异步的方式能提高接口访问的性能,异步的方式本质上是对数据一步一步的加工,但是使得代码的可读性非常的差,非常不利于调试和维护。
如果业务逻辑更加复杂,我们会使用更多的异步数据链(或者是很多的回调方法),这种情况被称为“回调地狱”,意思是实现某个业务的时候,为了保证性能采用异步的方式,会有很多的回调方法使用,回调方法里面又可能包含回调方法,使代码结构非常复杂难懂。
不管是传统模型,还是改进后的异步模型,其实都避免不了两个问题:
-
阻塞:传统方式无论是否用异步的方式进行改进,都会发生阻塞,只要有阻塞就会有线程的等待和切换,浪费系统资源。
-
耦合:传统的方式执行代码是耦合的,例如A调用B,一定要B先执行完毕,A才能继续执行,就算是采用了异步方式,A的执行也可能会依赖B的执行结果。
并且对于程序员来讲,想构建一个性能良好的异步系统,需要很好的异步编程功底。
生活案例引入响应式编程
如何解决上面的问题?我先用生活中的例子来进行说明:你经营了一家餐厅(系统),每天都会有很多人来吃饭(访问系统),你餐厅的员工数量(线程)是有限的,并且你做菜的灶台数量(CPU核心)也是有限的。
传统的方式:来了一个顾客,就有一个员工去接待,顾客点菜之后,员工拿着菜单进入厨房:选菜、洗菜、切菜、炒菜、装盘、然后给顾客上菜。因为灶台的数量是有限的,所有你的餐厅常常有很多员工等着使用灶台,甚至发生竞争。
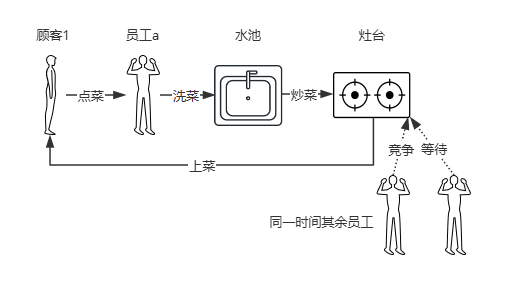
如果我们采用另一种管理方式,将员工按职责划分为:收银员、服务员、厨师等。顾客来到餐厅,专门有收银员进行点菜、然后通知服务员,服务员进行菜品准备再通知厨师,厨师做完之后再通知另一个服务员上菜,这样是不是合理得多了。
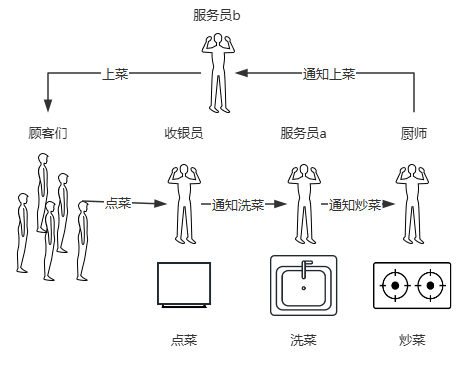
通过这种方式我们可以看到,收银员、服务员、厨师他们都是互不干扰的(异步)各忙各的,收银员不需要等待洗菜结束,就可以进行下一个顾客的点菜。厨师也不需要等待服务员上菜,就能继续炒下一个菜。只需要将菜品放在上菜端口(缓存),然后叫服务员过来上菜就行(消息通知)。
同样的员工配置和设备配置,后面这种方式极致的压榨了员工和设备,让他们无时无刻保持工作状态,一定比传统方式效率高。
响应式编程
针对命令式编程(传统编程)的痛点提出了一个响应式的思想:我们的系统实际上就是在处理数据,因为数据在不断的产生,我们的系统实际上就是在不断的处理产生的数据,所以我们可以把数据给抽象出来,变成一个一个的数据事件流(每个来点菜的顾客都可以看做一个数据事件),我们的系统对这个流中事件进行不断的处理。换句话说,系统等到数据产生的时候,系统去响应这些事件,而并不是直接顺序调用,例如下面这个图,A和B之间通过onNext()事件进行响应。
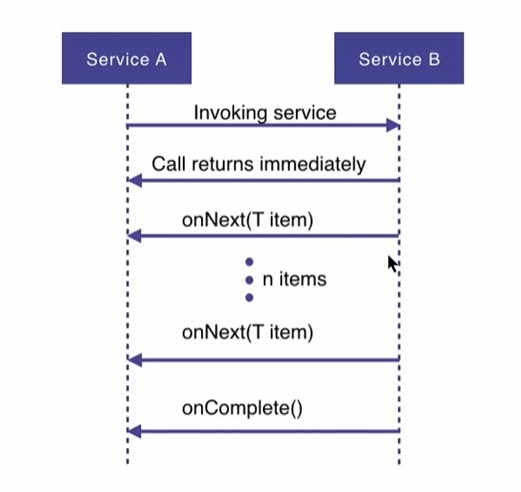
响应式编程的思路是:让少量的线程一直忙,而不是让大量的线程一直切换和等待。一个线程一直不空闲,不等任何数据返回,当数据到达后,自动放到缓冲区并触发消息回调机制即可。(例如:调用网络请求后直接进行后面的事情,可能继续调用别的网络请求,网络请求的数据放入缓冲区中,进行消息通知即可)
响应式编程的核心概念
响应式编程(Reactive Programming)是一种以数据流和变化传播为核心的编程范式,旨在更高效地处理异步、事件驱动的场景。响应式编程是一个编程范式,并不是具体只哪一门语言,在Java9中实现了响应式编程的这个范式。所以想在Java中使用响应式编程应该使用比Java9更高的版本。
-
数据流(Data Streams) 将一切视为随时间变化的数据流,包括用户输入、网络请求、状态变更等。例如:点击事件、API响应、变量更新都可建模为流。(餐厅例子中的顾客点单)
-
响应变化(Reactive to Changes) 当数据流中的值发生变化时,依赖这些值的代码会自动重新执行,无需手动触发更新。
-
声明式(Declarative) 程序编程的时候,通过组合操作符(如
map,filter,reduce)声明“要做什么”,而非一步步写“如何做”。我们成为命令式编程,例如:stream //数据流 .filter(x => x > 0) // 只保留正数 .map(x => x * 2) // 每个值乘以2 .subscribe(updateUI); // 订阅最终结果 -
异步与非阻塞 天然支持异步操作(如网络请求、定时任务),通过非阻塞方式处理高并发或延迟敏感的任务,提升资源利用率。(餐厅例子中各个步骤独立操作)
响应式中的组件
响应式的组件主要包括4个部分,分别为:发布者、订阅者、订阅关系、处理器,在Java9中分别由几个接口进行定义。
背压(back pressure):
在讲各个组件的之前,先介绍一下什么是背压:字面意思就是反过来的压力,是指订阅者可以根据自己的需求量获取发布者的数据。假设订阅者每次只能消费5个数据,那么订阅者可以通过request(5)方法,从发布者拿到5个数据,发布者有再多的数据订阅者每次也只取5个。背压机制可以有效的防止发布者数据量太大撑爆订阅者。
注意:这种称为拉模型,我需要多少就拉取多少,如果需要实现推模型(不进行背压,有多少数据就传多少),可以通过request(Long.MAX_VALUE)的方式实现。
Publisher
表示数据流的生产者或者数据源,其中包含一个方法让订阅者注册到发布者,Publisher代表了发布者和订阅者直接连接的标准化入口点。publisher发布的数据,存入到它的缓冲区,消费者在缓冲区中拿到数据。
public interface Publisher<T>{
public void subscribe(Subscriber <? Supper T> s) // 用于将订阅者注册到发布者
}Subscriber
表示消费者或者订阅者,onSubscribe 方法为我们提供了一种标准化的方式来通知 Subscriber 订阅成功。
public interface subscriber<T>{
public void onSubscribe(subscription s);// 订阅成功后执行
public void onNext(T t); // 下一个元素到达后执行
public void onError(Throwable t); // 发生异常时执行
public void oncomplete(); // 数据流完成时执行
}-
onSubscribe:发布者在开始处理之前调用,并向订阅者传递一个订阅票据对象(Subscription)。 -
onNext:用于通知订阅者发布者发布了新的数据项。 -
onError:用于通知订阅者,遇到了异常。 -
onComplete:用于通知订阅者所有的数据事件都已发布完成。
Subscription
同时,onSubscribe方法的传入参数引入一个名为 Subscription(订阅)的订阅票据,Subscription 为控制元素的生产提供了基础。
有如下方法:
public interface subscription {
public void request(long n);
public void cancel();
}-
request用于让订阅者通知发布者随后需要的元素数量。 -
cancel用于让订阅者取消发布者随后的事件流。
Processor
如果实体需要转换进来的项目,并将转换后的项目传递给另一个订阅者,此时要Processor接口。该接口既是订阅者,又是发布者:
public interface processor<T, R> extends subscriber<T>, Publisher<R>{
}响应式小结:
原理层面:响应式系统 = 消息驱动 + 数据流抽象 + 背压管理 + 异步非阻塞 + 容错机制
编码层面:流式编程+链式调用+声明式API
解决痛点:以前要做一个高并发系统:缓存、异步、队排好,这些操作全部需要程序员控制。现在响应式系统全自动控制整个逻辑,只需要告诉它需要哪些步骤就行。
Reactor框架
Reactor框架实现了Java9中的响应式编程规范,Reactor 框架作为 Java 响应式编程的核心库,提供了丰富的 API 操作符和类型,用于处理异步数据流。这里我将会简单介绍一下相关API,具体请参照官网:Project Reactor。
1. 核心数据类型:Flux 与 Mono
万物皆为数据,可以分为单个数据流和多个数据流,单个为Mono(一个数据或者没有数据)、多个为Flux。
Reactor 的核心是两种发布者类型,用于表示不同规模的数据流:
-
Flux 表示 0 到 N 个元素的异步序列,适用于流式数据处理(如 HTTP 请求流、数据库查询结果集)。
Flux<Integer> flux = Flux.just(1, 2, 3); // 创建包含多个元素的流 Flux<Long> intervalFlux = Flux.interval(Duration.ofSeconds(1)); // 每秒生成递增数字 -
Mono 表示 0 或 1 个元素的异步序列,适用于单值操作(如单个网络请求、数据库查询)。
Mono<String> mono = Mono.just("Hello"); // 创建单值流 Mono<Void> emptyMono = Mono.empty(); // 创建空流
2. 创建数据流的操作符
用于初始化 Flux 或 Mono 的常用方法:
-
静态工厂方法
-
just():直接创建包含指定元素的流 。
-
empty():创建空流 。 -
error():创建以错误结束的流 。 -
fromIterable():从集合创建流 。 -
range():生成整数范围的流 。 -
interval():按时间间隔生成无限流 。
-
3. 数据转换与处理操作符
对数据流进行过滤、映射、合并等操作:
-
转换类
-
map():将元素映射为新值(同步转换)。Flux.just(1, 2, 3).map(n -> n * 2); // 2, 4, 6
-
flatMap():将元素映射为新的流合并,异步展开元素(可能改变数量)。Flux.just(1, 2).flatMap(n -> Flux.range(1, n)); // 1, 1, 2
-
filter():按条件过滤元素。Flux.range(1,5).filter(n -> n % 2 == 0); // 2, 4
-
-
组合操作
-
zip:合并多个流(严格对齐)。Flux.zip(Flux.just("A", "B"), Flux.just(1, 2), (s, i) -> s + i); // A1, B2 -
merge:合并流(按时间顺序)。Flux.merge(Flux.interval(Duration.ofMillis(100)), Flux.interval(Duration.ofMillis(150)));
-
-
错误处理
-
onErrorResume:错误时切换备用流。Flux.error(new RuntimeException()) .onErrorResume(e -> Flux.just("Fallback")); -
retry:重试操作。Flux.error(new RuntimeException()).retry(3); // 最多重试 3 次
-
4. 背压控制
-
onBackpressureBuffer:缓冲溢出的数据。Flux.range(1, 1000).onBackpressureBuffer(100); // 缓冲 100 个元素 -
onBackpressureDrop:丢弃无法处理的数据。Flux.range(1, 1000).onBackpressureDrop(dropped -> log.info("Dropped: {}", dropped));
5. 调度与线程控制
-
Schedulers
示例:
Flux.range(1, 10) .publishOn(Schedulers.parallel()) // 后续操作在并行线程执行 .subscribe(n -> System.out.println(Thread.currentThread().getName())); -
切换调度器
subscribeOn:指定订阅时使用的调度器。Mono.fromCallable(() -> blockingIO()) .subscribeOn(Schedulers.boundedElastic()); // 阻塞操作在弹性线程池执行
6. 生命周期钩子
doOnNext:元素发出时触发。
Flux.just(1, 2).doOnNext(n -> log.info("Emitted: {}", n));doOnComplete:流完成时触发。
Flux.empty().doOnComplete(() -> log.info("Completed"));7. 工具方法
阻塞获取结果(测试用)
-
block()/blockFirst()/blockLast():String result = Mono.just("Hello").block(); // 阻塞直到获取结果
延迟操作
-
delayElements:Flux.just(1, 2).delayElements(Duration.ofSeconds(1)); // 每个元素延迟 1 秒
Web Flux
Web Flux是Spring基于Reactor整合的响应式web应用框架,使用方式跟Spring MVC大同小异。具体实用详情博主会在后续的文章中详细介绍。这里简单进行一下使用。
导入相关Pom
注意:spring-boot-starter-webflux 和 spring-boot-starter-web 不能同时存在。
<!--使用Springboot 3.4.5 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<!--使用JDK 17 -->
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<!--响应式的web依赖项 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<!--springboot测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>编写controller
@RestController
public class TestController {
/**
* 返回一个数据
*/
@GetMapping("/one")
public Mono<String> getOne() {
return Mono.just("one");
}
/**
* 返回多个数据
*/
@GetMapping("/many")
public Flux<String> getMany() {
return Flux.just("one", "two", "three");
}
/**
* SSE(Server-Send Event)请求
* 浏览器的效果是每500毫秒响应一部分数据
*/
@GetMapping(value = "/sse",produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> getSse() {
return Flux.just("one", "two", "three")
.delayElements(Duration.ofMillis(500));//每个元素延迟500毫秒
}
}webflux的使用基本和mvc没有区别,需要注意的是返回值都是以数据流的形式返回


















 1310
1310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









